
Tout plein de Lightnings imaginaires
par X.Toff, cmeunier27@free.fr – premiers dessins en 1998 et mis à jour le 25 Juillet 2023 –
|
- Le bipoutre Lockheed P-38 Lightning était un monoplace bipoutre très rapide - La version biplace P-38 Droop Snoot avait un observateur dans le nez - La version biplace P-38M avait un opérateur radar derrière le pilote 
|
|
- Le prototype biplace Lockheed XP-58 Chain Lightning était un gros quadrimoteur bihélice - Le prototype biplace RP-38 (Restricted Pursuit, 38e) explora le pilotage latéral asymétrique - Le prototype biplace Swordfish testait des profils d'aile 
|
|
- Un modèle à verrière intégrée fut envisagé avant de retenir la configuration finale à nez libre - Autre piste envisagée chez Lockheed : 2 moteurs alignés avec le cockpit, en "push-pull" - Autre encore : le cockpit aligné avec un des moteurs, en "bifuselage" asymétrique 
|
|
- Autre voie de dessin chez Lockheed : un simple fuselage central avec des moteurs latéraux - Aussi : un fuselage abritant les gros moteurs, actionnant à distance les hélices latérales - Variante : des hélices propulsives soufflant des dérives latérales 
|
|
- Non construit, le projet Lockheed L-24 aurait vu le Lightning (L-22) pourvu de moteurs en étoile - Une des variantes L-106 du XP-49 (P-38 amélioré) aurait eu aussi de tels moteurs radiaux - Une des variantes L-121 du XP-58 aurait été similaire 
|
|
- Une version à flotteurs, envisagée, n'aurait pas eu besoin de pistes de décollage - Une version à stabilisateurs avant fut testée en soufflerie à haute vitesse - Une version à nacelle alourdie, grossie, a été dessinée pour un gros bidule dit "75mm" 
|
|
- Une version lourde du XP-58 fut envisagée par Lockheed avec une soute interne centrale - Un dérivé cargo léger du P-38 (brevet Sullivan/Lockheed US 2.367.538) aurait eu des portes arrières 
|
|
- L-131 : projet Lockheed monomoteur de nez à écope ventrale, apparemment biplace - L-131B : version hypothétique simplifiée - L-131U : version optimisée pour réemployer des pièces de P-38 
|
|
- Une maquette originale fut proposée dans la gamme des avions-œufs Hasegawa (Egg-Lightning) - Un fichier Corel (P-38 LTN) était distribué avec de très déformantes simplifications - Un modèle volant (P-38 Combat) était simplement monomoteur. 
|
|
A partir de maquettes commerciales de P-38 furent construites des versions tronquées ou doublées (Jahsan Pair of 38's, Brooks P-38Z & Drone, Petrie P-38T) 
|
|
- Le P-38 Kiwi fut une maquette bipoutre monomoteur asymétrique - Aussi asymétrique, le P-38S-1 était monopoutre monomoteur - Enfin, le Ludgate P-38Y fut un asymétrique push-pull canard… 
|
|
- Le Ludgate P-38X fut une maquette asymétrique mixte avec un réacteur et un moteur à piston - Un canard propulsif à dérives avant fut aussi construit en maquette - Enfin, le Steacy P-38 pusher était similaire mais à dérive centrale le rendant plus ou moins tripoutre 
|
|
- La maquette Fordham P-38XF avait des dérives modernisées et un empennage Tabouret - La maquette Halsted P-74 Forked Lightning avait un nez moteur et des stabilisateurs de Mustang - La maquette Perri P-38XL était quadrimoteur 
|
|
- Le Klos P-38L fut un fichier 3D élaboré par un enfant de 13 ans - Le Robinson P-38B, à poutres éloignées, fut une autre maquette virtuelle, composée rapidement - Le Besson P-38d, à dérives écartées, est un troisième exemple bâti avec le logiciel RC-CAD 
|
|
- The Squirt : version de P-38 à poutres réacteurs, dessinée en 1945 dans un magazine pour étudiants - Kakuki P-38M-2 : version à poste arrière dégagé, dessinée sur ordinateur dans les années 2000, pour Internet - P-38 DONUT : version triplace push-pull à nez libres, illustrant les paroles de l'Internaute D-ONUT 
|
|
- P-1938A : version de bimoteur simple à nez libre "oubliée" par Lockheed - P-1938B : variante différemment asymétrique - P-1938C : version à moteurs dans le fuselage 
|
P-1938D, E, F : autres bimoteurs à nez libre
|
P-1938G, H, J : petits pas de plus dans la ligne des bimoteurs à nez libre
|
|
- Le P-38VG à flèche variable fut dessiné suite à un malentendu sur l'E.E. Lightning à géométrie variable - Le P-38VG' à dièdre variable déclinait cette possibilité - Le P-38VG" à envergure et corde variables achevait le parcours 
|
|
- Le P-38Jt fut une version du Squirt dessinée pour se rapprocher davantage du P-38 de base - Le P-38JR-3 fut une version modernisée, dessinée selon les idées de l'Internaute Ollie - Le P-38AJ aurait été une version asymétrique mixte pistons/jet, sorte de P-38X bifuselage 
|
|
- Le P-38 Reco aurait été une version du RP-38 débarrassée de la nacelle centrale - Le P-38Y-2 serait une version assagie du P-38Y, simplement tractrice et monopoutre - P-38Y-3 : version du précédent avec cockpit latéral 
|
|
- Le Deino P-38DE aurait été une version vraiment canard, tripoutre - Le P-38DE-2 fut une version bipoutre asymétrique du précédent - Le P-38DF fut dessiné comme version "aile volante" sans plans de profondeur 
|
Le P-38LR aurait doublé l'esquisse monofuselage du P-38, avec 2 à 4 moteurs, 1 ou 2 pilotes.
|
|
- Une version de Twin-Lightning fut dessinée avec deux nacelles centrales - Un Big-Lightning s'inspira de l'Egg-Lightning en doublant les hauteurs sans toucher les longueurs - Un TP-38R s'inspira du P-38Reco, rendu davantage harmonieux 
|
|
- P-74B : version push-pull du P-74 - P-74C : version bimoteur optimale – un double moteur propulsif et le nez reste libre - PP-3838 : version de double Lightning dupliqué longitudinalement au lieu de transversalement 
|
|
- P-38P : version canard propulsif à 2 dérives arrières – joignant le caractère bipoutre pur à un certain équilibre - P-38-31 : inspiré de l'Airspeed AS.31, qui n'a jamais été construit, étonnamment… - P-38LS LightSpeed : mixage du P-38-31 et du P-38P 
|
Le HP-38 aurait réinventé l'esquisse monofuselage du P-38 avant doublement et asymétrisation…
|
Les P-38N auraient réinventé, en version bipoutre, les moteurs centraux (au nombre de 2, 4 ou 6…) actionnant des hélices latérales.
|
Les P-38R-1 et R-3 auraient eu des moteurs-fusées et le P-38Jt-4 : des turbofans…
|
|
- GP-38W : maquette de Lightning simplifiée, planeur hypersonique ou pédalo lacustre… - P-38PF : projet de Lightning complexifié, hexamoteur pour record de vitesse ou pour rire - P-38R-4 : Lightning quadrirotor à décollage vertical 
|
|
- P-38-3V : version asymétrique de Lightning surmotorisé - P-38YF-5 : version sage dans l'asymétrie, avec motorisation normale - P-38-11 : Lightning normal, symétrique, mais à moteurs radiaux monstrueux 
|
Famille des AP-38, dérivés de RP-38 avec asymétrie accrue.
|
|
- P-38TXF : hybride asymétrique de P-38JR-3 et P-38DF - Forbidden-38 : version improbable, à empennage double mais un seul moteur - Permitted-38 : version assagie, "équilibrée" par doublement 
|
Ci-dessous, trois P-38YY obtenus en doublant le P-38Y avec fonctions copier/coller et miroir.
|
Avec trois boîtes de P-38 pouvaient être créés divers modèles "raisonnables".
|
Sous les noms P-38V et P-38W auraient pu apparaître des Lightnings à ailes en flèche marquée.
|
La série PT-38 (A, B, C) aurait été constituée de biplaces simples.
|
|
- TA-38 : biplace bimoteur push-pull - BT-38 : biplace quadrimoteur push-pull à radiateurs frontaux - B-38A : biplace quadrimoteur push-pull à verrière bulle 
|
|
- P-74OSh : moteur central actionnant des hélices latérales, façon Bedounkovitch OSh - P-74OSh-2 : variante asymétrique du précédent - P-74M : moteurs latéraux actionnant des hélices centrales, façon Matra R-75 
|
|
- P-74N : version du P-74M à moteurs sur les flancs de la nacelle centrale - P-74J : version à réaction du P-74N - P-38Rol : version avec une casserole allongée pour rapprocher les moteurs sans choc entre hélices 
|
|
- PZ-3838 : version du PP-3838 sans dérive, sans empennage. Bipoutre quand même ? - PL-3838 : version aile volante, à empennage sur l'aile. Bipoutre ? - P-38DZ : version non push-pull du précédent 
|
|
- RP-58 : XP-58 monoplace façon P-38 - P-48A : P-38 à poste arrière de XP-58 - P-58J : version triréacteur du XP-58 
|
|
- P-38Car : P-38 à portière de voiture façon P-39, donc cockpit avancé - P-38Pcp : version sûre, sans hélice du côté de la sortie - P-38W² : version sûre pour sortie au sol, mais interdisant le parachutage en vol 
|
|
- P-38St : variante du précédent à hélices caudales - TP-38C : version biplace à deux portières derrière les hélices - FP-38FC : version quadriplace, à portion voiture détachable (combiné Avion-Auto) 
|
|
- TJ-38 : version menaçant de couper en rondelles le pilote qui sauterait en parachute - P-38PP : variante à hélices latérales - P-38P : inclassable, protégé des hélices principales mais avec autre danger derrière 
|
|
- P-38Kit-2 : Lightning à décollage vertical, posé sur la queue, à rotors bipales engrenants - P-38TWv : version à aile tandem du précédent 
|
Ajout d'une brochette de P-38 trimoteurs.
|
|
- P-38AL AirLining : avion de ligne Lightning à multiples hublots et porte latérale arrière - P-38 LG : avion de transport léger, ambulance, pour deux civières - P-389 : avion à verrière panoramique arrière, façon Fw 189 
|
|
- P-38-141C : version asymétrique de P-38LG, avec accès encore plus facile - P-38-141R : version asymétrique de P-389, façon Bv 141, visibilité optimisée - P-38-141D : version double à 3 verrières panoramiques 
|
|
- P-38-72-48 : ce que serait une maquette au soixante-douzième avec nacelle au quarante-huitième - P-38-72-144 : idem avec nacelle au cent quarante quatrième - P-38-0 : version sans nacelle, sans pilote, bipoutre ou bifuselage ? 
|
|
- P-38-32-72 : ce que serait une maquette au trente-deuxième avec verrière au soixante-douzième - P-38-24-144 : extrême absolu de vingt-quatrième avec verrière au cent-quarante-quatrième, bifuselage - CBY-38 : variante à fuselage porteur du précédent, façon CBY-3 
|
|
- P-388 : ce que serait une maquette mixte de Lightning au 1/48e et 1/72e porté sur la queue - P-3858 : appariement de P-38 et XP-58 - P-38ST : double P-38S-1, bipoutre 
|
Versions monoréacteurs ou trimoteur asymétrique.
|
|
- BP-38 : version de P-38 simple à fuselage porteur, façon Burnelli, et portes frontales - P-38NT : aile volante longue - P-38HT : aile volante évidée ou bipoutre alaire 
|
3 modèles à aile arrière : aile volante et canards, à base P-38 ou XP-58.
|
3 modèles à dérives en bout d'aile.
|
Planeur, remorqueur de planeur et semi-planeur…
|
|
- P-38S : push-pull asymétrique - P-38hf : Lightning hydroplaneur - P-38RJ : Lightning transsonique à moteurs fusée 
|
Autres Lightnings asymétrique ou panoramiques.
|
Doux délires sur le thème des habitacles sans nez.
|
Empennages en folie.
|
|
- P-38-1/2 : mixte de P-38 et précurseur - P-38-1/3 : idem en version bifuselage triple-nez - P-38-II : version modernisée du P-38, à verrière bulle et hélices doubles 
|
|
- PL-38 : version à flotteurs-poutres, comme le PL 200 - PF-38H : version à fuselage bipoutre - PF-38V : version à poutres superposées verticalement 
|
|
- P-38S-2 : version de P-38S-1 à une poutre et une poutrelle de soutien, bipoutre ? - P-38S-3 : version à un fuselage et une poutrelle, bipoutre ? - P-38S-4 : hybride de P-38 bipoutre et monofuselage 
|
|
- P-58K : version monoréacteur asymétrique du XP-58, à verrière sous poutre - P-38-1+1 : version canard asymétrique - P-38DONUT' : version canard du push-pull DONUT 
|
P-38LW, HW, BW : versions à aile basse/haute/biplane
|
P-38A+, B+, H+ : variantes sur les thèmes asymétrique, biplan, hydravion
|
|
– Chevy 1/Mitsubishi A8M1 : dessin Internet de dérivé exotique, de taille réduite – P-38-82 : hybride bifuselage de P-38 et P-82 Twin-Mustang – P-82-38 : dérivé triplace, plus proche du P-82 
|
P-38-^-, P-38W, P-38V V : du Lightning Circonflexe au Lightning Papillon
|
P-38Î, P-38CF, GP-38S : variations sur la queue du Lightning
|
P-38AE (-1, -2, -3): sur le thème "monopoutre avec asymétrie et/ou pilotage excentré"
|
|
- Hall-Rhodes/Bell Patent D143731: bimoteur inspiré du Lockheed P-38 - Hall-Rhodes/Bell Patent D143730: version biréacteur - Hall-Rhodes/Bell Patent D143729: version monoréacteur 
|
|
- Hall-Rhodes/Bell Patent D143732: grand quadriréacteur à fuselage porteur - D-143-738: Lightning inspiré de Bell en retour - D-138 : version triréacteur de Lightning à petits jets façon Bell 
|
P-38 Delta, versions -1, -2, -3, à la recherche de centrage...
|
OP-38, versions -1, -2, -3, de pire en pire...
|
3 versions propulsives canard, en terminant par des dérives et poutres vitrées, pour la visibilité latérale, sérieusement…
|
|
- P-38Z' : ce P-38 n'est qu'un bimoteur bipoutre standard, oui, mais binez… - P-38Q : bifuselage monopoutre panoramique - P-38U : inclassable binacelle monopoutre 
|
|
- AG-38 : hélicoptère semi-autogyre à rotor anti-couple tractif - AT-38 : intermédiaire entre aile annulaire et aile tandem - XC-38 : transport à cabine détachable 
|
|
- Lightning Mk IV : quadrimoteur bien refroidi - P-38MP Laïtning : multipoutre solide - P-38Q2 : le Lightning est un avion à 2 queues, disent les Québécois 
|
| Des soucoupes volantes P-38: - Tsr-Joe TSR-38 (ou TSR-38-2) : l'invention initiale - TSR-38-1 Flying Sausning : dérivé asymétrique, un peu moins sage - TSR-38-3 : version trimoteur push-pull 
|
- P-38WI What-if Lightning-like Lightning : triple P-38 en forme d'éclair
|
- P-38WI-1 et WI-2 : versions éclair sur base mono-Lightning et bi-Lightning
|
| Très gros Lightnings : - DC-38 : avion de ligne, remplaçant du DC-3 - C-38-2 : avion cargo, remplaçant du C-38 qui était un DC-2 - PA-38 : avion PanorAmique pour groupe de touristes 
|
| Des dizaines de "P-38 astronefs" ont été construits en miniature (maquettes ou lego), avec des formes cubiques (ici adoucies pour faire "un peu plus P-38"). - Bubbalicious SW-38 : modèle sans queue à réacteurs en bout de poutres (dérivé de vrai P-38) - Jassim SF-38 Lightning 2 : modèle à bloc fusée formant la queue (dit P-38 car bipoutre) - Sammis SV 38 : modèle semi delta à queue multiple (dit P-38 car bipoutre) 
|
|
- Greg GTX PR-38 "Lightning meets Pond-Racer" : hybride tripoutre inspiré d'un avion de course - PR-38B : version monofuselage - PR-38C : version quadrimoteur push-pull 
|
- PR-38D, E, F Lightnings plus proches du Pond Racer
|
| Trightning tripoutres à plans canards : - XPC-38 : prototype à (stabilisateur arrière et) soutien avant de moteurs allongés - YPC-38 : version à stabilisateurs avant - PC-38 : biplace à (stabilisateurs avant et) soutien arrière de poste caudal 
|
Autres P-38 tripoutres (triplex-boom) mais sans plans canards : PX-38A, B, C.
|
P-38 tripoutres à aile tandem, ancêtres des Rutan/Scaled ATTT et Proteus : Pro-38A, B.
|
| P-38O-2 LightNaster: ancêtre LightNing du Cessna O-2 Skymaster P-38-26 LightNooter : dérivé LightNing du Boeing P-26 Peashooter P-38-72 LightNerbolt : précurseur LightNing du Republic XP-72 Superbolt 
|
| Lightning Mk IIIC : ancêtre du Mirage IIIC (delta radar supersonique à dérives, cockpit et allure P-38) Lightning Mk IIID : dérivé asymétrique (à traînée aérodynamique et poids réduits) Lightning Mk IVA : dérivé biplace biréacteur (bifuselage pur) 
|
| P-38i : modèle canard à hélice intégrée P-38ii : modèle avec cockpit avant et hélice intégrée P-38iii : modèle trihélice à 1 hélice intégrée 
|
P-38WB (-1, -2, -3) Wing-boom (poutres-ailes ou poutrelles)
|
P-38FB (-1, -2, -3) Fin-boom (poutres-dérives)
|
| Lightning marins originaux : - P-38HB : biplan à flotteur central - P-38HM : parasol monomoteur asymétrique (1 coque + 1 flotteur) 
|
| - triplace Pe-38 : ce n'est pas un Petlyakov-38 mais un Perfect-38, à visibilité et traînée optimales - Boxkite M-38 Katamaran : inspiré d'un projet Myassishtshev M-63 - Topheed P-38HM-2 : terrestre monomoteur asymétrique (1 fuselage + 1 poutre) 
|
| - P-38Z" : asymétrique à moteurs décalés (pour solides poutres proches) - PF-38U : poutres alaires dissociées des moteurs - PP-38A : quadrimoteur push-pull à aile et cockpit simples 
|
| - P-38LA : tripoutre Légèrement Asymétrique car les hélices tournent dans le même sens - XU-38 : transporteur de cube - YU-38 : version asymétrique du XU-38, à chargement facilité 
|
| - XP-38P² : push-pull tripoutre de base - YP-38P² : version monoplace simplifiée - P-38P² : version asymétrique simplifiée 
|
Dérivés lightning du push-pull Dornier Do-335 : Dornheed Do-338A, B, C
|
Dérivés monomoteurs propulsifs des précédents : Do-339A, B, C
|
Dérivés inversés avec moteur arrière tractif, moteur avant (central) propulsif : Do-340A, B, C
|
Avec le code 341, il fallait ressembler au Bv 141 asymétrique : Do-341A, B, C
|
PB-38A, B, C : non Pursuit-Bomber mais Personal-Biplane (biplan personnel)
|
FB-38A, B, C : non Fighter-Bomber mais Four-Boom (quatre poutres)
|
AB-38A, B, C : non Attack-Bomber mais Asymmetric-Biplane (biplan asymétrique)
|
TP-38A, B, C : non Trainer-Pursuit mais Tail-Propeller (hélice de queue)
|
BrianDaBasheed SP-38A, B, C : SPecial SPort SPats P-38 (P-38 pantalonnés)
|
BrianDaBasheed SP-38D, E, F : P-38 pantalonnés exotiques - monotrace, à empennage surbaissé, convertible avion/voiture
|
CL-38A, B, C : Control Line Lightnings, modèles réduits asymétriques optimisés pour le vol circulaire
|
| - Toy-38 : jouet représentant un P-38, bihélice sans moteur, croisillon de plans - Toy-P-38 : version moins éloignée de la source - Toy-Q-38 : version à profil interprété comme mono-corps 
|
| - P-38 Stunt : modèle réduit monomoteur, de 1966, trouvé sur Internet - P-38ST : P-38 modifié pour ressembler au Stunt - P-38 Stunt-2 : vérsion rendue bimoteur du Stunt, pour ressembler davantage au P-38 
|
| - D-119714 (Design patent for Airplane Model P-38) : projet breveté en 1939 - D-19714 : dérivé simplifié asymétrique, 2008 - D-9714 : dérivé encore simplifié et encore plus asymétrique 
|
| - Myers US2578578 (Patent for convertible aircraft) : genre de P-38 canard à longs arbres de transmission - My-38A : P-38 ressemblant à un Myers - My-38P : dérivé plus proche encore du P-38 
|
BF-38 Big-Fin Lightning, BP-38-II, AT-38-II
|
| - Mc Coy Patent US2542042 : modèle réduit de 1944 - Mc-38 : modèle Mc Coy qui ressemblerait davantage à un P-38 - P-38Mc : P-38 qui ressemblerait au Mc Coy 
|
| - Le Tigre Rose P-38TR : caricature délicieuse, 2007 - P-38HS Half Solid Lightning : version prévue à arrière libre, mais en pratique consolidée - P-38HS-2 : version du précédent à cockpit arrière 
|
P-38TF (-2, -1, -3) Twin-Fin : Lightning presque normaux (bidérives à nacelle)
|
Entre le Lockheed P-38 Lightning et le Lockheed F-35 Lightning II, le chaînon manquant s'appelle Lightning I (versions XF-38, YF-38, F-38A).
|
| - P-38 OT : sorte de biplace d'essai en photo sur le site de Orion Technologies - P-38 OT-1 : version monoplace (imaginaire) à même canopée, mais "bulle" sans barreaux, avec long nez classique - P-38 OT-4 : version quadriplace extrapolée du biplace 
|
DL-38 (A, B, C) Delightning (Delanne-Lightning) à ailes tandem décalées
|
P-38ET (-1, -2, -3) Extra Tails. Lightnings à complément latéral d'empennage, pas tout à fait bipoutres.
|
| - Phillips P-38DC Derby Car : version voiture de Lightnings, par des membres de la P-38 Association - P-3DP Derby Plane : version avion de l’étroite DC - P-38LC Lightning Car : P-38DC moins simplifié 
|
Sur le site de l’américaine P-38 National Association figurent trois caricatures de P-38 Cartoon (avec les noms Piggyback, Toon, Toon long), similaires, parfois en vue seulement partielle – ici complétée.
|
| - P-38SL Solar Lightning : avion électrique à énergie solaire, ayant une raison originale d’être bipoutre : doubler la surface de panneaux photovoltaïques orientables. - SP-38G Solar P-38 Glider : planeur emmagasinant l’énergie solaire au dessus des nuages le jour, puis atterrissant pour éclairer l’aéroport de nuit. - QP-38SU Solar Unmanned : version télécommandée du précédent. 
|
| - XH-38 Helicopning : transformation du P-38 en hélicoptère birotor. - YH-38 Lightnopter : version améliorée à rotors moins rapides (rotors engrenants monopales, entrainés par un même moteur). - H-38A Lighopter : version finale à rotors coaxiaux, simplement bipoutre par filiation. 
|
DP-38Z (-1, -2, -3) Lightning Zwilling : doubles P-38 en version simple ou asymétrique ou à moteur central
|
P-38SB monopoutre, P-38TSB bi-monopoutre, P-38TFP bifuselage à nacelle (SingleBoom, TwinSingleBoom, TwinFuselagePod)
|
P-38BHT (biplane half tail), P-38TLW (tail like wing), P-38WLT (wing like tail)
|
| - AS-38Z : double-dirigeable Airship Zeppening - RT-38A Boomning : ancêtre du Rutan Boomerang - RT-38B Twin-Boomning : version double du précédent 
|
J.38A, B, C : Lightnings à réaction, doubles ou asymétriques
|
EP-38A, B, C : Engine-Pod Lightnings, bipoutres verticaux binacelles avec partie basse occupée par 2 moteurs en tandem
|
YP-49, P-49A, P-49B : dérivés à réaction du XP-49, imaginés par le what-if designer SSgtBaloo
|
| - P-83 Xwing-Lightning : version canard à aile en X conçue par le what-if designer ElektrikBlue, avec petites hélices à 6 pales et arrière protégé. Sans relation avec le prototype Bell XP-83, abandonné, lui… - P-83B : version moins oblique, moins équilibrée mais plus lisible sous mon angle. - HP-83 : version avec flotteurs, biplace dos à dos, suggérée par ElektrikBlue. 
|
| - P-383X et HP-383X : versions non-canard ("davantage P-38") des P-83 et HP-83 - P-3883XX : hybride de P-383X et P-83, officiellement rejeté car la configuration triplace paraissait peu crédible 
|
| Finir une vieille maquette de Droop Snoot, 30 ans après, a conduit à diverses étapes, d’hérésie croissante : - GP-38J : version planeur à nez plein inversé haut-bas - GP-38K : version à empennage en T et moustaches de nez - GP-38L : n’ayant pas retrouvé les parties vitrées et réutilisant une casserole d’hélice en pointe 
|
Lock-and-Voss P.238A, B, J : inspirés des Blohm-und-Voss P.208 et P.209
|
| - R-38 racer de course à micro-verrière - SN-38A asymétrique inspiré d'un projet véritable quoique sans nom - SN-38B version monopoutre encore plus asymétrique 
|
| - TH-38A et B Twinhulling: bicoques sous P-38, à aile haute ou parasol - XV-38 VTOLing : version à décollage vertical 
|
| - XP-58 préliminaire d'après un dessin de 1940 - XXP-58 : accouplement des versions préliminaire et finale de XP-58 - XP-358 : version de P-38 reprenant les idées et moteurs du XP-58 préliminaire 
|
| - TD-38 Lightandem quadrimoteur à aile tandem - TPX-38 Triplex-Lightning : trimoteur à nez moteur mais à cockpit latéral - QPX-38 Quadruplex-Lightning : version quadrimoteur du précédent 
|
PS-38A, B, C Pushing : versions bizarres à moteur pousseur
|
SG-38A, B, C Singling : versions à une seule dérive
|
| TTRE-38 : Trimoteur Tractif à Moteur Arrière GSN-38 : Nez Court Vitré FGN-38 : Nez Vitré Avant 
|
| Thewlis Wide Eye : maquette (d'avion de reconnaissance sans pilote) présentée à l’Eagles Day 2008 YR-38U : version "à décollage piloté" avant saut en parachute du pilote R-38U : version trimotrice 
|
La réinvention du Pair of P-38, présentée à une exposition IPMS 2009 (F-26B Twin Lightning) rappelle que des trifuselages (ou quadrifuselages) binacelles peuvent décliner côte à côte les différents modèles. Cela peut générer des milliers de doubles asymétriques, à commencer par les DA-38A, B, C ci-dessous.
|
| Sources d’inspiration du BAC-EE Lightning supersonique : - P-38SJ à réacteurs superposés - P-38TD à delta tronqué en ailes en flèche - P-38NC à entrée d’air autour d’un cône de nez 
|
Doubles asymétriques plus simples : DA-38D, E, F.
|
Lightnings quadripoutres additionnels : QB-38A, B, C.
|
Versions quadripoutres davantage asymétriques : QB-38A-2, B-2, C-2.
|
| - LMZ : Lightning-Mosquito-Zwilling inventé par B787, jeune what-if designer - LNZ : version asymétrique push-pull - LOZ : version trimotrice 
|
Avec 2 hélices propulsives : Twin-Pusher TPsh-38A, B, C
|
Avec 2 hélices propulsives arrière : Twin-Rear-Pusher TRPsh-38A, B, C
|
BESp-38A, B, C : bimoteurs à nacelles motrices séparées des poutres (pour des versions diverses : tractrices, propulsives, push-pull, tout en réutilisant des pièces de série P-38)
|
| - FVP-38A : version de P-38 avec 2 postes avant panoramiques - FVP-38B : dérivé monoplace (asymétrique) - FVP-38C : dérivé simplifié très asymétrique 
|
| - FVP-38D : version canard du FVP-38A - FVP-38E : version propulsive - FVP-38F : dérivé monomoteur asymétrique à vue avant/arrière 
|
| - FVP-38G : version du FVP-38F sans formule canard - FVP-38H : version du FVP-38G sans formule propulsive - FVP-38J : version du FVP-38H avec davantage de pièces standards P-38 
|
P-74 D, E, F : dérivés pousseurs
|
P-74 D-2, E-2, F-2 : versions légèrement asymétriques des précédents
|
| - Ludgate LR-38M-1 : maquette quadrimotrice du P-38M (inachevée à ce jour, silhouette à confirmer) - LR-38M-2 : erreur d'interprétation de Tophe, à 2 types de moteurs, d'après les nacelles externes en construction - LR-38M-3 : version entièrement à moteurs en étoile 
|
LR-38M-4/5/6 : versions de Long Range 38 à vue arrière et configuration asymétrique |
| - AP-38M Aviconing : inspiré du Bartini M révélé par AvicoPress - BP-38M Bartining : dérivé push-pull davantage bifuselage - CP-38M Uconing : version asymétrique hybride, améliorée par mon ami Konstantin/Ucon, expert  |
AP-38M-2, BP-38M-2, CP-38M-2 Uconing-2000 : versions à moteurs latéraux et transmission à hélice(s) centrale(s) |
CP-38M-3 Push-Pulling, CP-38M-4 Pull-Pulling, CP-38M-5 Push-Pushing |
| - TF-38H : Hydravion à triple flotteur (projet véridique sauf le code) - CP-38C Caterpilning : version tous terrains à chenilles (non rétractables...) - Pb-38L Lightlead : version en "plomb allégé"  |
|
Histoire d’une maquette de science-fiction, par AeroplaneDriver, réinterprétée par Tophe : – sPec-38A Spectre : Lightning sans aile ni queue puisque astronef dans le vide sidéral – sPec-38B : conversion du monoplace 1/72 en gros 7-places réduit au 1/350 – sPec-38C : version plus avancée du précédent, redescendue au 1/144. – Référence Utapau P-38 Starfighter : maquette en vedette du film StarWars III, ici dessinée en version civile plus proche du Lockheed  |
| Ludgate P-38 Glider : ébauche de maquette planeur avec pilote couché au 1/35 en avion 1/48 (inachevée à ce jour, silhouette à confirmer - 3 hypothèses de Tophe : PG-38A, B, C) 
|
Avant le célèbre Centre NC-1070 vint le tripoutre NC-1038, et ses dérivés NC-1038/4m et NC-1038J
|
P-74G, H, K : simples tri-pousseurs, plus ou moins asymétriques
|
TF-38A, B, C Tailfirning : canards propulsifs monomoteurs
|
PIN-38A, B, C : P-38 à nacelle plus ou moins intégrée dans l'aile
|
| - SP-38H Spatning : nouveau P-38 pantalonné - PS-38D Shortning : P-38 court pour ascenceur de porte-avions - PS-38E Shortning II : version asymétrique à meilleure visibilité latérale 
|
| - P-38++ : chainon manquant entre queues séparées et stabilo jointif - P-38+T HalfTing : Lightning à demi-empenage en T - P-38VT HalfVing : Lightning à demi-empennage en V 
|
| - LPF-38 : Le Plus Fragile Lightning - P-38LP-CE : à Hélices Latérales, (mono)moteur central - P-38CP-LE : à Hélices Centrales, (bi)moteur latéral 
|
| - SSF-38A : Lightning à aile semi-soufflée - WC-38 : Lighting à aile canal (channel wing) - DN-38 : Lightning à double nez, pour lancer deux fois plus de fleurs 
|
| - DN-38B : version à double nez fusionné - LA-38A : version transonique à ajouts de section échelonnés (selon "Loi des Aires") - LA-38B : version plus symétrique pour l'aile mais plus progressive pour les moteurs 
|
CM-38A, B, C Catamaring : bateau catamaran, hydravion bicoque, avion à triple habitacle
|
TB-38A, B, C TwinBeaming : Lightning à doubles poutrelles, plus ou moins distantes
|
LC-38A, B, C : Lightning à large corde sur ailes externes (pour énormes réservoirs, immense autonomie), avec 2 à 4 moteurs
|
SP-38J, K, L Sesquip-lightning : semi biplans à trains d'atterrissage très courts et solides (sans garde d'hélice gênante)
|
SP-38M, SP-38N, CD-38A : du sesquiplan au canard, avec l'hybride intermédiaire
|
P-38 Delta-4, -5, -6 : variantes à ailes externes triangulaires et empennage tabouret
|
| - Psn-38 Nikining : hybride de Lightning et Nikitine PSN-2 - ThP-38A Threesning : P-38 triplace tricockpit vers l'avant et l'arrière - ThP-38C : version canard du ThP-38A 
|
ThP-38B, TwP-38A, TwP-38B Pushpulning : étapes vers l'avion tête-bèche
|
| Le pape es-bipoutres, X-Toff-II, a déclaré religieusement qu’un bipoutre orthodoxe se devait d’avoir des poutres « pures » : ni fuseaux moteurs allongés ni dérives allongées (ni habitacles allongés). Pour que le Lightning reste le chef de file des bipoutres, il fallut simplement reconstruire à dix mille exemplaires les OP-38A, B, C ci-dessous. Avec l’argent du contribuable, tout est possible assez simplement... Sauver l’âme des gens est aisé, finalement. 
|
µP-38A, B, C Microning : Lightings à micro-moteurs.
|
JHM-38A, B, C Lowning-Mouse : Lightings à empennages (biplans décalés) inspirés d'une idée du what-if modeller John Howling Mouse.
|
Grâce au what-if modeller Mossie s'ajoutent les asymétriques MP-38A Mossing, MP-38Z-1 et Z-2 Twin-Mossing
|
| – XP-73 Swordstar : demi-XP-58 (Chain-Lightning) à queue de F-80, inventé par le What-if modeller/Secret-Projector Stargazer2006 – XP-73B Swordning : version du Swordstar employant davantage de pièces du XP-58 – XP-73Z Chain-Swordning : double XP-73B ramenant presque au XP-58 
|
| – P-38/73 : version monomère de P-38 traité « façon XP-73 Swordstar » – P-38/73B : version bicockpit push-pull asymétrique (pour faire simple) – P-38/73Z : version jumelée du B, ramenant presque à un P-38, enrichi (bipoutre oui, mais quand même quadriplace asymétrique) 
|
| – Patent-38,38,38 : Lightning à "double queue double" inspirée du Patent Bragg 6,086,014 – P-38BT : bouche-trou entre les deux autres, asymétrique faute de place sur le dessin – P-38,38,38 : version consolidée du Patent 38,38,38 
|
| – P-38JB-1 et 2 : vues du mignon P-38F de Jean Barbaud dans la BD "Les Dézingueurs", maladroitement extrapolées selon mon angle – P-38BJ : P-38 classique à nacelle inspirée du JB-2 
|
P-38CTS-1, 2, 3 : Lightnings basés sur la formule du Curtiss XP-71
|
| Lightnings inspirés des bipoutres imaginaires de Howdy Bixby – Fg-38 Anteatning, version Lockheed du Furtwangler Fg-103 Anteater – Dt-38 Dratning, version Lockheed du Drat 80-T 
|
|
– LO-38VV Lozenjning, version à empennage losange (V + V inversé) – DP-38C Cargning, version cargo biplane à deux P-38 superposés – AT-38E Torqning, version à gros moteurs tournant dans le même sens, nécessitant équilibrage 
|
|
– P.38CT Caning, d'après un alphabet 1943 pour enfant américain : "P is for P38 Lightning" ou "P is for a performing P.38" (à visage de petit chien) – CT-38i Innosning : version gentille, innocente, du P-38 personnalisé (tortue) – CT-38e Evilning : version méchante, colérique, du P-38 personnalisé (crocodile) 
|
|
– P38MD Artning, d'après un collage de Matt Dawson, artiste libre – P-38DM-1 Smilning : P-38 "sérieux" à visage souriant – P-38DM-2 : P-38 parfait à queue inspirée du P38MD 
|
P-38VC-1 (et -2, -3) Vietning : versions à moteurs en étoile et doubles hélices, demandées par Vietcong, membre du forum Secret Projects.
|
|
– P-38BHA : extrapolé d'une mignonne caricature de profil chez Black Heart Art – P-38BHB : P-38 standard à dimensions inspirées du BHA – P-38BHC : P-38 standard à nacelle gonflée un peu comme le BHA 
|
|
– P-38EB-1 : version trimoteur tripoutre tridérive inventée par le what-if designer José-Manuel Electrik-Blue – P-38EB-2 : version bimoteur bipoutre bidérive d’ElectrikBlue, asymétrique permettant des moteurs très rapprochés (moindre déséquilibre « asymétriue » en cas de panne d’un moteur !) – P-38ET : version monomoteur du précédent, imaginée par Tophe, avec radar au vitriol fumant, à installer loin du pilote 
|
|
– MAG-38 : Lightning à portance par effet Magnus – CYC-38 (au repos puis en marche) : Lightning cyclogire avec ailes "roues à aubes" (à 2 tours/seconde) 
|
|
– L-1638 Super-Constellightning : avion de ligne ressemblant à un P-38 très grossi – P-38FP Four-Propelning : version agrandie du P-38 – NP-38A Mass-Murdning : version (dite "nucléaire") à multiples postes, d'observation pacifique sans doute 
|
|
– XFM-38 Airaclightning : version Lockheed du trifuselage Bell FM-1 Airacuda – YFM-38 Airaghtning : version bifuselage monopoutre à rapport puissance/poids améliorée – FM-38A Airaning : version finale solidifiée, bifuselage + bipoutre 
|
BOK-38A, B, C Borovning : dérivés Lightnings du dessin de Tchijevskii BOK-6 par Borovik, membre du forum Secret Projects
|
DS-38A, B, C Droopy-Lightning : variantes basées sur le Droop Snoot
|
|
– CAO.38 Lightcleaning: tentative de dessiner le plus « propre » P-38 toutes catégories… (suggestion du what-if modeller CAO 700) – MG -38PL Poisson-Luning : autre « très pur », MG signifie MontGolfier (ballon à air chaud), pas du tout Machine-Gun (mitrailleuse)… 
|
|
– AGB-38T kilowning : machine inspirée du Lockheed/NASA AGB-7-TBI à 2 gros moteurs et deux petits moulins dynamos de 500 kiloWatts. – AGB-38A Monoplightning : version monoplane du précédent – P-38AGB Agabandhe : Lightning à nacelle hybride P-38/AGB-38 
|
AsP-38A, B, C Aspiring : nouveaux P-38 asymétriques
|
SyP-38A, B Syphilning et AsP-38D : autres P-38, symétriques et asymétriques
|
D-38A, T Deltaning : P-38 deltas canards dessinés d'après une idée du what-ifer Glippy
|
|
– D-38Dd : autre multi-delta Lightning – CF-38M2 Marseillaise-II : Lightning canard pouvant envoyer des fleurs de bienvenue sans qu’elles se cognent au stabilo – YC-38 : Lightning à décollage court inspiré du Boeing YC-14 
|
EC-38A, B, C Remotning : un moteur central actionnant une hélice latérale par arbre de transmission, ça libère le nez, mais il peut falloir un second moteur, donc de l'autre côté.
|
EC-38D, E, F Panoraning : à quoi sert un nez libre ? à admirer le paysage...
|
|
– Mistel Lightning : avion composite à réservoirs planants largables (non explosifs, j’y tiens) – Double Twin Lightning : dans une paire de jumeaux, le plus grand peut être jusqu'à deux fois plus imposant – Siamese Twin Lightning : couple, un peu faible, de jumeaux très soudés 
|
|
– U-38 Stratolightning : ancêtre du U-2, pour la très haute altitude à atmosphère raréfiée – KhAI-38 : dérivé bidérive de l’aile volante KhAI-3 – KhAA-38 : version asymétrique bimoteur du précédent 
|
TriP-38A, B, C Tridentning : méritant mieux que le P-38 le surnom de "diables à queue fourchue"
|
|
– LP-38 Longlightning : modèle allongé pour réservoirs (grande distance franchissable) – ShP-38 Shortlightning : modèle raccourci pour ascenseur (porte-avions ou souterrain) – PoP-38 Rigolightning : modèle mixte pour carnaval 
|
ST-38AD, FO, ADFO : Stealth-Lightnings Adouci, Fondu, Adouci-fondu
|
VP-38A VertiLightning : en vol de croisière, en transition asymétrique, à l'atterrissage/décollage
|
TN-38A, B, C Twinozning : Lightnings planeurs bi-nez divers
|
|
– Cat-38 : catamaran de course sur l'eau – Qua-38 : quadriptère mécanique – Bi-38 : biplan serré sans mats 
|
Cola-38A, B, C : Lightning inspirés par les aéronefs du bio-designer Luigi Colani
|
DE-38A, B, C Deux-Echelning : avec des maquettes 1/72 et 1/144 de P-38, on peut générer plein d'hybrides
|
DP-38D, P-XXXVIII, D.38D Borovning : intermédiaires entre Lightning et Borovkov Florov D
|
TaP-38A, B, C : Tail-Propeller Lightnings à moteurs avant et arbres de transmission jusqu'aux sommets de dérives.
|
|
– TaP-38D, E : variantes du push-pull TaP-38C encore plus asymétriques, encore plus compliquées mécaniquement – DF-38 Dwarfning : micro-Lightning pliable pour ascenseur (bateau, sous-terrain, immeuble, ...) 
|
|
– MJ-38A, B Motorjetning : variantes de Lightning à motoréacteurs (pistons + réchauffe) – TPL-38 Triplening : version triplace sécurisée avec pilote suppléant et suppléant du suppléant 
|
|
– RP-38A, B Roadable Plane : combinés avion-voitures bimoteurs à ailes repliables – RH-38A Roadable Helicopter : combiné avion-hélicoptère à rotor détachable 
|
Ludgate FGL-38A (et FGL-38B, C): version finie du Glider-38 (et dérivés plus ou moins empennés)
|
|
– IPMS-38? : Lightning à voiture incorporée, présenté en maquette à une exposition "IPMS Region 4". – CR-38-2000 : version du précédent modernisée avec voiture moins ancienne – CR-38-2010 : version améliorée à portière latérale au lieu d'entrée par le toît... 
|
| La future maquette GP-38L a été rebaptisée LO-1 grâce à Stargazer2006, mais la découpe des pièces plastiques ne permettait pas la version à empennage en T envisagée au départ. Les versions LO-1A, B, C ont donc été envisagées. 
|
Une vieille maquette de Lightning pouvait être convertie en avion-radar P-38AWACS (-1, -2, -3)
|
| Le what-if modeller Caveman a amélioré le P-38 AWACS. – CAC-38 : Caveman Aircraft Co model 38, biplace tridérive – CAC-48 : version à nacelle allongée pour l'électronique du radar – CAC-58 : version remplaçant la base P-38 par un XP-58 
|
| Suite à une interrogation du what-if modeller Stargazer2006, détail expliquant ma classification : – P-38-1F : aile volante binacelle – P-38-2F : bipoutre sans stabilisateur – P-38-3F : bipoutre sans dérive 
|
P-38-1P, -2P, -3P : équivalents des -xF avec nacelle centrale
|
| – P-38-4P version bipoutre asymétrique – XP-38TP Turbo Lightning : projet à turbopropulseur du what-if modeller Bladerunner – P-38G-2 V-1-Hunter : projet de Bladerunner à moteurs en ligne et radiateurs annulaires 
|
| TC-38A, B, C : dessin (et développement) inspiré(s) de la maquette inachevée du XP-55 Skunk (projet de mix Lightning-Meteor du what-if modeller tc2324) 
|
Skunk A, B, C : dessin corrigé de la maquette Skunk finalisée, version monomoteur, version monofuselage
|
E-38A, B, C Electroning : versions à gros volumes d'électronique de brouillage
|
| – LO-1 Bb Baby Lightning glider : version finalisée de la maquette LO-1B – LO-1 Bd Bandessining : version encore plus asymétrique – LO-1 Be : canard aussi asymétrique 
|
| – XF-5D : véridique biplace de reconnaissance – YF-5D : version biplace à esthétique améliorée – F-5D : version biplace à vision optimale vers le bas 
|
| – AV-38 Alvightning : double push-pull inspiré du Twin-Skymaster construit par le what-if modeller Alvis – FL-38 Flyer-38 : comme l'ancêtre Wright, avec pilote à gauche, moteur à droite, hélice propulsive au centre – FL-38A : version optimisée du FL-38 en ayant moins peur de l'asymétrie 
|
| Une magnifique brochette conçue par le what-if modeler Stargazer2006 d’AviaDesign : – Lockheed L-2022 Quad-Lightning : tripoutre bi-push-pull – Lockheed L-2122 Sudden-Lightning : version asymétrique bimoteur push-pull – Lockheed L-2222 Tough-Lightning (prononcé Toff-Lightning) : version bipoutre asymétrique… 
|
Le succès de la famille L-2022 conduisit aux L-2038/2138/2238, plus proches des P-38.
|
Inspirés par une visite au joli Parc des Oiseaux : BD-38 aviaire, BU-38 sorti de chrysalide, BE-38 apicole.
|
Un Dieu Lightning n’aurait pas créé à Son image que les animaux ailés : SD-38 arachnide, AN-38 ouvrière, CW-38 à cornes.
|
Le Ludgate LR/PR-38M est la version finalisée du LR-38M ; les QR-38 et RR-38 en sont dérivés.
|
| – Brentnall Patent US2460804 : véridique brevet pour rendre canard une sorte de P-38 – Brentheed US3838 : version de modèle Brentnall à nacelle de P-38 – Brentoff P-3804 : P-38 à moustaches Brentnall + ajout arrière 
|
AV-38B, C, D : dérivés simplifiés de l'AV-38, plus ou moins asymétriques
|
AFT-38A, B : modèles P-38 à réservoir volant auxiliaire
|
| H2-38A, B : cela aurait pu être des avions à immense autonomie dévoreurs de pétrole, mais il s'agit d'avions "normaux" à carburant hydrogène très volumineux. Leur vol ne produit que de l'eau : des nuages de pluie, c'est bon pour la planète et les salades. 
|
| – P-38 Alternate 2 : invention du what-if modeller GTX, d’un Lightning à puissance de feu doublée – P-38 Exterminate : charmante version moins rapide mais encore plus destructrice (“rien ne sert de courir, il faut massacrer à point”) – P-38 Nobelpeace : idyllique version à soutes nucléaires pour vitrifier en masse les bébés de suspects terroristes 
|
PK-38A, B, C : réalisation ultra-simple de maquettes P-38 asymétriques
|
CN-38A, B, C Cartooning : avec une verrière doublée et des yeux, vers une caricature de Lightning
|
AL-38A, B, C Airlining : étapes vers un Lightning pour passagers
|
| LB-38A, B, C Littlebooming : modèles à petites poutres-poutrelles, (tenant l'empennage sans prolonger dérives ni moteurs ni habitacles) 
|
TW-38A, HW-38, DJ-38
|
Lockheed-Payen Pa-38A, B, C Flech-ning : versions bipoutres du canard-delta Fléchair
|
| Lockheed-Consolidated Par-38A, B, C Catalining : versions à aile parasol du Lightning (le nouveau nez libre reçoit un gentil radar météo, pas des méchants canons) 
|
TC-38D, E, F : hybrides de TC-38A et fusée atomique imaginaire Nebulor
|
| – A-38C Turbo-Lightning : version biplace turbopropulsée construite par Alvis Petrie – A-38D : version monoplace plus proche du P-38 usuel – XA-38 : version préfigurant le A-38C mais à moteurs standards 
|
EO-38A, B, C Sailboatning : P-38 reconvertis en voiliers catamarans
|
TX-38A, B, C Trifusning : Lightning à soutes cargo latérales (poutres-fuselages? sans moteur ni train)
|
P-38YR-1920, 1910, 1950 : différentes générations méconnues de Lightning
|
| FP-38A Flying Prao : premier hydravion "prao" au monde... (Même si un hydravion catamaran asymétrique semblait naturel, il semblait impossible d'avoir un avion-prao, l'avant ne pouvait pas devenir arrière, sinon l'aile cesserait de porter pour déporter... avec une simple aile pivotante, le miracle est obtenu : l'aile fait un demi-tour pour tirer le nouvel avant.) 
|
TM-38A, B, C : trimaran et dérivés simplifiés asymétriques
|
| – G-38A : version à moteurs Griffon dessinée par les what-if modellers GTX et Apophenia – G-38B : un seul Griffon suffit comme supplément de chevaux... – G-38C : un seul Griffon suffit comme source de chevaux... 
|
| – P-38SE : version monofuselage créée par le what-if modeller Apophenia – P-38SK : version asymétrique suggérée par le what-if modeller PR19_Kit – TP-38SE : double monomoteur – TP-38SK : version double asymétrique 
|
G+38A, B, C : versions propulsives de G-38 suggérées par le what-if modeller PR19_Kit
|
| – CC-38 Jet-Lightning : dérivé à réaction dessiné par le what-if modeller Captain Canada – XCC-38 : prototype du CC-38 avant installation des réacteurs – PCC-38 : P-38 standard reprenant les solutions du CC-38 
|
| – N-38 : composite asymétrique de 2 Lightnings – N-38S : version quadruplane à envergure très réduite – N-38T : version triplane simplifiée du précédent 
|
UAV-38A, B, C : versions téléguidées de Lightning
|
RPV-38A, B, C : jouets sans pilote déguisés en militaire, touriste, transporteur
|
N-38U, V, W : autres modélisations Lightning en construisant la maquette N-119
|
N-38X, Y, Z : encore des modélisations Lightning en finalisant la maquette N-119
|
| – Dempsey TD-3 Beta Lightning : prototype véridique daté 1969 – TD-38 : version à nacelle étroite (à la P-38) du TD-3 – P-38TN : version à nacelle large (à la TD-3) du P-38 
|
CaP-38 Carning inspiré du Carplane : mode aérien, routier à hélice, routier à roues motrices.
|
P-38WV (et dérivés) imaginé par le what-if modeller Weaver inspiré par le what-ifer JP Vieira.
|
SL-38C (et A, B, plus proches du P-38) : cousins du Lightning imaginés par le what-if modeller Slerski.
|
| KJP-38 : version à moteurs plus petits du SL-38C, demandée par la what-if designeuse KJ_Lesnick PAB-38A, B: versions du KJP-38 évitant le couple de 2 moteurs tournant dans le même sens, imaginées grâce à Pablo1965. 
|
| FR-38A, B, C : versions plus puissantes du P-38PF requises par le maquettiste créatif finsrin (le FR-38C est de taille réduite, plus concentré) 
|
BB-38A, B, C : avec tant de puissance, les FR-38 peuvent avoir un solide train fixe (versions souhaitées par le maquettiste créatif Brian da Basher)
|
| RC-38A, B, C : versions de Lightning inspirées par le joli "art déviant" de RussC, avions paraboliques ou à poutre porte-roulette 
|
XAS-38, XAT-38, XAU-38 : premiers essais de Lightning asymétriques pour multiples touristes
|
Blaireaux Super P38J, A, B : Ligntings vitrés basés sur une invention de Tonton42
|
PM-38A, B, C : inventions touristiques du what-if modeller pyro-manic
|
PM-38J, XPM-38, AP-38 Asymightning : versions bimoteurs de pyro-manic et moi-même
|
PR-38B, PR-38R, AB-38A : versions issues d'idées des what-if modellers PR19_Kit et abtex
|
PM-38S, MU-38A, MU-38B : versions tirées de malentendus avec pyro-manic ou inventions personnelles
|
PM-38T, PR-38S, PR-38T : améliorations avec l'aide de PR19_Kit
|
P-47Z ChainBolt, YP-47Z, XP-47Z : hybrides de P-38 Lightning et P-47 Thunderbolt imaginés par José Fernandes
|
| SKL-38A, B, C : Lightnings philippins (dessinés à la demande de la what-if modeleuse Saint Katana Legacy) avec puissance accrue par fusées 
|
LD-38A, LD-38B, DL-38A : Lightnings doubles et demi Lightning bouche-trou...
|
RC-38D, E, F : dérivés du RC-38C se rapprochant du P-38 standard
|
| – PF-38 Sesquiplane-Lightning : ce n'est pas un 38e Pursuit Fighter mais la transformation d'une maquette offerte par mon frère Pierre-François. – PH-38 : ce n'est pas un 38e Potentiel Hydronium mais un Pursuit Helicopter convertible pour vol vertical/horizontal 
|
| – XN-38 & YN-38 : versions monoplanes atant précédé le N-38 – Horten V38 : asymétrique franc, mono-aile en flèche 
|
XMI-38, YMI-38, MI-38A : Lightnings à Moteurs Inférieurs
|
DoP-38A, B, C : P-38 à nez asymétrique inspirés du Dornier P222/9-08
|
MN-38A, B, C : P-38 multi-nez pour "envoi de fleurs" ou tourisme multi-passagers
|
| Une famille DiB-38 qui n'est pas le Développement industriel Balmolan dans l'Isère : – DiB-38A & B : P-38 Différemment Bimoteurs (dans l'axe à hélices asymétriques, au lieu de latéralement à hélices symétriques) – DiB-38C : P-38 Différemment Bipoutre (à hélice tractrice centrale, au lieu de fuseaux moteurs latéraux ou hélice propulsive centrale) 
|
|
– MMP-38 : Mono-MonoPoutre – BMP-38 : Bi-MonoPoutre – MPBN-38A : MonoPoutre BiNacelle Asymétrique 
|
FP-38C, D, E : tri-corps inspirés d'un multi-jet dessiné par Stargazer2006
|
CLD-38A, B, C : P-38 ConsoLiDés...
|
P-38FFF : dérivé Lightning d'une maquette Fw189 à moi
|
µJ-38A, B, C : Micro-Jets dérivés du Lightning
|
CA-38A, B, C : Lightnings à cockpit arrière
|
RF-38A, B, C : Lightnings à moteurs fusées
|
MA-38 : Lightning à rotors basculants inspiré d'un projet Marmonier
|
AsyP-38A, B, C Asymmetric Lightnings : nouveaux P-38 asymétriques
|
F-138B, C, D : dérivés Lightninguisés de la maquette F-138 du créatif Finsrin et son projet push-pull associé
|
KP-38A, B Kitning : dérivés à grand allongement après discussion avec le what-if modeller PR19_Kit
|
Me-338A, B, C : Lightnings inspirés par le Messerschmitt Me-334
|
RaP-38A, B, C Radishning : Lightnings chauve-souris inspirés par le Bat-Dakota du what-if modeller Radish
|
B-38B, C, D Lightuda : ancêtres de l'Airacuda ?
|
B-38E, F, G : suite de la série de Lightnings lourds
|
|
B-38B, C, D Lightuda : ancêtres de l'Airacuda ?
|
|
Lightnings du nouveau monde, à l'invitation de Brian da Basher: - BdP-38A: avec air épais et propulsion mentale, pas besoin d'envergure ni de moteurs - BdP-38B: avec pantalons pour l'élégance - BdP-38C: avec un clin d'oeil pour le défilé des bisounours 
|
BR-38A, B, C : Dérivés lightninguisés du Briar/Aarcesair XF-43 Chariot
|
RB-38A, B, C : modèles à poutres-fusées
|
|
Vue inspirée de la caricature peinte sur le P-38L Pacific Prowler (et intermédiaires avec les P-38 "normaux") 
|
MP-38B, C, D: multipoutres inspirés par une discussion avec le what-if-maquettiste PR19_Kit
|
MP-38ZB, ZC, ZD: correction, Kit ayant parlé de tripoutre avant que je délire sur les multipoutres...
|
|
– Stargazer2006/Bispro/Lockheed FTO-1 Thunder : version avec axe central libre pour lourde charge largable – FTO-2 : version monoplace asymétrique – FTO-3 : version plus proche du P-38 standard 
|
HH-38A, B, C : versions russo-egyptiennes à hélices carénées, suggérées par un ami
|
HC-38A, B, C : dérivés Lightninguisés de l'Hélican Mercier
|
|
– D-8 : version désarmée du P-Dirty-Eight de Christian Pearce – D-8A, D-8Z : versions asymétrique et double 
|
|
– P-38TJ : triple Droop Snoot fabriqué par le what-if modeller ericr – YP-38TJ et XP-38TJ : variations moins équilibrées 
|
P-38TK, YP-38TK, XP-38TK : variantes asymétriques des P-38TJ
|
|
– EF-38A : egg-Lightning à flotteurs inventé par le what-if modeller Ericr – EF-38B : variante profitant du fuselage large 
|
|
– EF-38D : Droop-Snoot à flotteurs inventé par le what-if modeller Ericr – EF-38E, EF-38F : variantes monoplace et monomoteur 
|
|
– EF-38C : modèle manquant dans la collection Ericr, un egg-Droop-Snoot – EF-38G : variante basée sur mon premier dessin d'egg-Lightning – EF-38H : variante double comparant les deux dessins 
|
|
– EF-38J Ballerine : drone monopoutre monoroue construit par Ericr – EF-38K : variante moins "improbable" mais moins amusante – CE-38 : egg-Lighting en céramique trouvé par Ericr sur le Web 
|
AL-38H, J, K : délire à partir de l'idée "avion de ligne triréacteur à empennage en H"
|
AL-38L, M, N : autres "avions de ligne trimoteurs à empennage en H"
|
|
– TPT-38 : tripoutre à radiateurs latéraux et gros fuselage central – N38K1 : variante inspirée de la maquette N1K1/2 du what-if modeller Sticky Fingers – AR-38 : Lightning arctique sur skis 
|
XPL-38, YPL-38, PL-38A : Lightnings asymétriques inspirés d'un avion virtuel présenté par X-plane.org
|
XXL-38, YXL-38, XL-38A : versions à postes arrières
|
|
– LPB-38 : Lightning à Long-PareBrise – PL-38B, C : Lightnings convertis en planeurs modernes 
|
|
– Mystery MyP-38 : création asymétrique du what-if modeller Librarian – MoP-38A : croisement de laboratoire entre un P-38 et une mouche – MoP-38B : P-38 déguisé en mouche 
|
|
– Li-38A : bête curieuse inspirée de l'autogyre pousseur, bipoutre vertical, du what-if modeller Librarian – Li-38B, C : versions avions du précédent 
|
|
– MS-538A : dérivé Lightninguisé du Morane Saulnier 050 AP6 – MS-538B, C : versions plus lointaines 
|
|
– SM-38A : bihélice monomoteur dérivé du Salmson-Moineau SM-1 – SM-38B : bimoteur trihélice dérivé du Salmson-Moineau SM-2 – SM-38C : bimoteur axial inspiré du triste Sylvain-Métailié SM-0 
|
|
– SM-38D : Lightning Semi-Monotrace – SM-38E : Lightning Super-Mouette – WIG-38A : Lightning marin à effet de sol 
|
BC-38A, B, C : Lightnings tout bancals
|
ES-38A, B, C : intermédiaires entre Eshelman The Wing et Lightning
|
P-38> <, P-38X X, P-38< > : Lightnings inspirés de celui dessiné par le P-38X du deviant-artist Binoched
|
|
– D-38D : Davis Davis dessiné comme dérivé de P-38 – XD-38D : P-38 à nacelle Davis – YD-38D : Davis à nacelle Lightning 
|
UB-38, UB-38A, UB-38B : versions Burnelli du Lightning, à long rayon d'action
|
UB-38J Jackning, UB-38K, UB-38L : versions aile-volante de l'UB-38B
|
UB-38L-2 -3, -4 : versions modifiées de l'UB-38L suggérées par le what-if modeller Weaver
|
UB-38M, UB-38N, UB-38P : autres versions de l'UB-38B
|
UB-38FW-1, 2, 3 : autres versions aile-volante de l'UB-38
|
UB-76A, B, C : versions jumelées de l'UB-38
|
UB-38A-3, -1, -2 : dérivés de l'UB-38A à motorisation changée
|
UB-38Z-1, -2, -3 : versions jumelées de l'UB-38A-1
|
UB-38TJ-1, TJ-2, TR-1 : versions à réaction du Burnelli Lightning
|
UB-38E-4, UB-38E-8, UB-38AL : versions à 4 ou 8 moteurs, complétées par un gros avion de ligne
|
UB-38S-1, S-2, S-3 : version monofuselage et dérivés
|
RB-38, XUB-38, YUB-38 : versions antérieures à l'UB-38
|
UB-38CA-P, CA-J, CA-R : versions très canard du Burnelli Lightning
|
UB-38O-1, O-2, O-3 : versions d'observation ou tourisme de l'UB-38
|
UB-38O-4, O-5, O-6 : versions de tourisme à multiples places panoramiques
|
UB-38TC-1, -2, -3 : comme le Turboclair, il s'agissait d'avions reconvertis en dispositifs anti-brouillard au sol
|
UB-38TC-4, -5, -6 : dérivés "avions" des Burnelli Lightning Turboclairs
|
UB-38BV-1, -2, -3 : versions Blohm und Voss du Burnelli Lightning
|
UB-38BV-4, -5, -6 : versions agrandies de Blohm und Voss/Burnelli Lightning
|
UB-38BV-4B, -5B, -6B : petites versions à 4/5/6 moteurs de l'UB-38BV-3
|
UB-38MI-1, -2, -3 : évolution du Mistel double Burnelli-Lightning vers un biplan à aile supérieure (réservoir) largable
|
UB-38XP, P-38XP-1, P-38XP-2 : asymétriques inspirés de mon évolution du XP-69Z (de José Fernandes)
|
UB-38U-1, -2, -3 : sans nez armé, une version compactée est possible
|
UB-38S-4, -5, -6 : variantes asymétriques du Burnelli-Lightning monopoutre
|
UB-38Asy-1, -2, -3 : variantes asymétriques des Burnelli-Lightnings les plus standards
|
UB-38Asy-4, -5, -6 : Burnelli-Lightning demi avion-de-ligne et demi-Burnellis
|
UB-38Asy-7, -8, -9 : autres variantes asymétriques du Burnelli-Lightning
|
UB-38NF-1, -2, P-38NF : variantes nocturnes à multiples observateurs
|
UB-38RAA-1, -2, -3 : Burnelli-Lightnings à hélices engrenantes suggérés par le what-if modeller Raafif
|
UB-38RAA-4, -5, -6 : Burnelli-Lightnings à hélices engrenantes améliorés, un doublet d'hélices étant entraîné par un même moteur...
|
P-38RAA-4, -5, -6 : Lightnings "classiques" inspirés des UB-38RAA-4 à 6
|
UB-38RAA-7, -8, -9 : autres Lighting-Burnellis à hélice contra-rotatives
|
UB-38RAA-10, -11, -12 : version bimoteurs quadrihélices
|
UB-38PP-1, -2, -3 : versions push-pull asymétrique de l'UB-38
|
P-38IM, PPA, PPB : versions de P-38 à hélices engrenantes ou push-pull asymétriques
|
UB-38W-1, -2, -3 : versions bi-push/pull de Burnelli Lightning inspiré par un Spitfire étrange trouvé par le what-if modeller Wuzak
|
UB-38WZ-1, -2 : versions tandem des précédents
|
AL-38P, Q, R : vers un Lightning avion de ligne
|
P-38CA-1, 2, 3 : Lightnings inspirés d'une caricature trouvée sur Internet (zazzle et cafepress)
|
P-38R1830A, B, C : versions motorisées en étoile, à base plus ou moins véridique
|
UB-38HT-1, 2, 3 : Lightnings à queue surélevée
|
UB-138A, B, C : ancêtres Lightnings du Blohm und Voss Bv 138
|
UB-38SM-44, 55, 66 : dérivés Lightning des Savoia-Marchetti S.55, 66 et 77
|
UB-38SP-1, 2, 3 : dérivés hydravions des précédents
|
UB-38DO-1, 2, 3 : versions hydravions à longue quille et "sponsons" (ailerons stabilisateurs)
|
P-38NACA-1, 2, 3 : versions affinées de Lightning, "véridiques" (si je ne rêve pas) puis fantaisiste
|
P-38NACA-4, 5, 6 : en poursuivant (au delà du raisonnable) l'affinement du Lightning, on perd hélas toute ressemblance avec un P-38
|
XP-38X-3, -2 : versions à 3 ailes tandem, et 6 ou 2 moteurs
|
|
– UB-38X-3 : Burnelli-Lightning à immenses endurance et longueur de décollage – UB-38XB : version avec moins de problèmes aérodynamiques, mais plus grande fragilité 
|
|
– MyP-38B (POA-38Q) : projet modifié de Mystery Lightning construit par le what-if modeller Librarian – V-38B : version modifiée de bipoutre vertical inspiré d'un montage photo de Librarian – FV-38B : hydravion asymétrique et bipoutre vertical, inspiré de la maquette semi-Twin-Mustang du what-if modeller Ericr 
|
XDP-38, YDP-38, DP-38A : double-Lightnings de plus en plus compacts
|
|
– OA-38N : maquette inventée par le what-if modeller Librarian – R-38N : version de course de l'OA-38N – OA-38M : version de OA-38 moins différente du Lightning standard 
|
XER-38, YER-38, ER-38A : Lightnings monoflotteurs inspirés par les biflotteurs du maquettiste créatif Ericr
|
VX-38, NF-38, RA-38 : Lightnings styles Vieux, Neuf, Rapide
|
|
– RE-38A (à position de moteurs tournant autour de l'axe central) en configuration "tout va bien" – RE-38A avec des ratés sur le moteur droit (le moteur valide venant sur l'axe central pour couper le moteur défaillant sans asymétrie – RE-38A avec des ratés sur le moteur gauche 
|
|
– RE-38B version solidifiée du RE-38, ici en position "tout va bien" – RE-38B (ou C) avec des ratés sur le moteur droit – RE-38C (à 2 moteurs solidaires pour simplifier mécaniquement le levage du moteur valide) en position "tout va bien" 
|
ER-38B, C, D : hydravion Lightning corrigé avec l'aide d'Ericr, et versions inspirées de son Me-609W
|
ER-38E, F, G : hydravions à poutres-flotteurs, pour inspirer le maquettiste Ericr
|
North American Lockheed Adder : 3 des multiples interprétations du profil imaginé par AviaDesign/Stéphane Beaumort (monodérive à tridérive, monopoutre à tripoutre, bimoteur à quadrimoteur)...
|
Adder (suite) : 3 autres des multiples interprétations possibles (monopoutre, tridérive, pentamoteur binacelle)
|
Adder (fin) : Pour illustrer le cas quadrimoteur mentionné plus haut, il est utile d'introduire l'enrichissement de moteur sans poutre ni cockpit
|
Adder (post final) : A la réflexion, une autre famille de silhouettes auraient partagé le profil de l'Adder, avec une partie Mustang "externe"
|
AD-38A, B, C : Ligntings à poutres courtes inspirés de ce détail de l'AviaDesign ADder.
|
EL-38A, B, C : Ligntings bipoutres à hélices latérales et moteur(s) central (aux).
|
ERP-38A, B, C : Il ne s'agit pas ici de logiciel Enterprise Resource Planning mais d'avions Eric Rutten Pursuit, intermédiaires entre P-38 et Delanne 10C2 conçus en hommage à ce maquettiste rêveur: Ericr
|
P-38-1012, P-38-2012, P-38V7 : Lightnings polymoteurs à 12 moteurs V-1710 ou V-3420 (24 moteurs V-1710), ou 7 moteurs jumelés intégrés dans l'aile
|
|
– MP-38T : Lightning triplace sérieux inspiré du POA-38Q – MP-38Q : Lightning quadriplace tranquille – MP-38AL : Lightning multiplace à 12 passagers 
|
FW-38A, B, C, D : versions de plus en plus minimalistes du Lightning monodérive aile volante
|
TTP-38A, B : Lightnings "Tandem-wing Three-surface Push-pull" inspirés du Bristol Bullseye du rêveur Stargazer
|
RP-38Z, YP-38L, YP-38R : Lightnings tripoutres ou trifuselages inspirés de la maquette YP-82L du what-if modeller PR19_Kit
|
|
RP-38Z, YP-38L, YP-38R : Lightnings tripoutres ou trifuselages inspirés de la maquette YP-82L du what-if modeller PR19_Kit
|
|
– PAc-38 : modèle de P-38 en Acajou trouvé sur Internet (sans relation avec la Politique Agricole Commune...) – PAd-38 : P-38 standard à poutres de PAc-38 – PAe-38 : hybride asymétrique de P-38 et PAc-38 
|
BO-38A, B, C : autres Lightnings jouets en bois trouvés sur Internet
|
|
– PV-38A : Lightning inspiré du robot transformeur Powerdive, lui-même inspiré du P-38 – PV-38B : version encore plus sage, Lightninguisée loin de la science-fiction – PV-38C : version avec une raison de reculer le pilote: pour installer un moteur supplémentaire (central pour optimiser la maneuvrabilité et pas pousseur pour permettre le saut en parachute) 
|
PVw-38A, B, C : Lightning-Views optimisés pour la vue vers l'avant, au contraire du PV-38 (aucun rapport avec Volkswagen)
|
|
– PVw-38D : version de PVw-38 à hélices protégées du raclement au décollage – P-38V-3420 : version de P-38 à double-moteurs trouvant de quoi brasser l'air – P-38V-3421 : version monomoteure V-3420 (ou bi-V-1710 comme le P-38 standard) 
|
ERP-38D, E : nouveaux Lightnings à ailes tandem
|
OHP-38, OAP-38, OAP-38P : Lightnings hélicoptères et autogyres
|
|
– P-38DR : cartoon-Lightning asymétrique dessiné par le deviant-artist Zombiedragon123 – XP-38DR : version un peu plus réaliste – YP-38DR : version avec un peu d'asymétrie pour montrer son joli profil au photographe 
|
|
– PW-38A : Pursuit-Wreck 38, Lightning en ruine/épave, ayant perdu sa queue et ses pales d'hélice (ou Lightning intersidéral à propulsion ionique...) – PW-38B : ruine sans arrière des poutres ni casseroles d'hélice (ou aile volante biréacteur) – PW-38C : ruine presque en miettes, enfin désarmée 
|
|
– PW-38TF : version du PW-38B à turbofans Pratt & Whitney – PW-38TF-2 : retour à la configuration bipoutre – PW-38TF-3 : retour à la configuration bihélice, avec "léger appoint" 
|
P-38FE-1, 2, 3 : quadrimoteurs Lightnings compacts sans être push-pull
|
P-38FE-4, P-38FEB, P-38TEB : autres délires sur le thème des Lightnings quadrimoteurs et/ou à aile tandem
|
KJ-38-I, III, V : hybrides de Lightning, Mosquito et Black Widow inspirés par la what-if modeleuse KJ_Lesnick, merci à elle
|
P-38FE-5, 6, 7 : autres Lightnings quadrimoteurs
|
DL-38D, E, F : versions Delannisées de Lightnings précédents à ailes tandem
|
WB-38A, B, C : dérivés d'un dessin humoristique de Flying ("we built it to compete with Lockheed!")
|
|
LECP-38A, B, C : Lightnings Lateral-Engines-Central-Propellers inspirés du Matra R75 (2 moteurs pour la puissance au décollage, hélices centrales pour symétrie en coupant un moteur en croisière, axe central pour passagers présents ou non) 
|
P-38XL-1, 2, 3 : intermédiaires entre Lightning et F-16XL
|
EE-38A, B, C : intermédiaires finaux entre Lightnings Lockheed et English Electric
|
TL-38, WU-38A, WU-38B : Twin-Lighning et dérivés conçus par le what-if modeller Wuzak
|
|
– "EV-38A" : véridique version bricolée pour évacuation de 2 passagers couchés – EV-38B : version plus "sérieusement" dessinée pour 4 passagers couchés – EV-38C : version VIP avec 2 passagers assis et pilote couché 
|
|
– XP-49 : prototype véridique qui avait été oublié en présentant un L-106 déviant – XP-4938 : avion double montrant la différence P-49/P-38 – YP-4938 : version insistant sur la différence de longueur 
|
|
– XP-49Z Twin-Super-Lightning : double P-49 – XP-49X : version bipoutre quadrimoteur – YP-49X : version hexamoteur 
|
|
– XP-49Y : modification du XP-49X suggérée par le what-if modeller Wuzak – YP-49Y : version rétrécie – P-49Y : version purement jet 
|
|
– Lightning Mk III : maquette créée par le what-if modeller Flyboy69, avec radiateurs de Heinkel 111 (et moteurs Merlin) – Lightning Mk IV : version simplifiée sans sur-refroidissement – Lightning Mk V : version radar asymétrique à double-Merlin 
|
|
– Lightning Mk IIIZ : pentamoteur inspiré du Heinkel He-111Z – Lightning Mk IIIZ-2 : version plus solide, plus légère, plus maneuvrable 
|
| Hybrides Lightnacuda de P-38 Lightning et FM-1 Airacuda, baptisés en remerciement à Pierre-François Meunier (qui m'avait offert un P-38 à ma sortie de l'hôpital). – PFM-38A : A comme Asymétrique – PFM-38B : version la plus proche de l'Airacuda – PFM-38C : version optimisée, plus légère et plus rapide 
|
Micro-lightnings : reconstructions à partir d'un stock de pièces P-38 sans ailes ni poutres
|
XF-138, YF-138, F-138A : hybrides de F-38 et de YF-16
|
Au lieu de se faire la guerre, P-38 Lightning et A6M Zero se sont mariés, et ont eu pour enfants les P38M3, P38M2, P38M1
|
GMTL-38A, B, C : Lightnings à Groupe Moteur Tandem Latéral, inspirés d'une petite maquette réalisée pour mon anniversaire
|
GMTL-38D, E, F : versions bifuselages et dérivée
|
|
– CoP-38A : Lightning "conventionnel" à queue de Shooting Star, conçu par ysi_maniac – CoP-38B : version Twin-Tail du précédent, par ysi_maniac aussi – CoP-38C : version monodérive moins inspirée du Shooting Star 
|
|
– LF-38A : Light Fighter tiré du P-38 par ysi_maniac – LF-38B : version Twin-Tail du précédent – LF-38C : version monodérive moins inspirée du Shooting Star 
|
PCa-38A, B, C : versions cargo de P-38
|
C-38A, YC-38, XC-38 : Lightning cargo secrets (le Douglas DC-2 baptisé C-38 serait une légende)
|
BiP-38A, B, C : Big Lightnings divers
|
|
– BOL-38 : Lightning à aile basse/haute pour le pilote ou les moteurs – LOB-38 : idem à aile haute/basse – LOB-38A : version avion de ligne du LOB-38 
|
HA-38A, B, C : Lightnings à Hélices Arrières
|
UP-38A, B, C : Lightning à hélices centrales propulsives, et dérivés à réaction
|
Ts-38A, B, C : Jet-Lightnings antiques inspirés d'un projet Tsiolkhovsky (avant que soit fixée la taille de moteur à réaction)
|
RO-38A, B, C : Lightnings terrestre et marins inspirés d'un projet pusher Robertson
|
X-38P-56, -55, -54, -38 : Réinvention du P-38 en imitant un petit XP-56/55/54
|
PO-38A, Z, ZB : Lightning et Twin-Lightning à aile annulaire, ou semi-annulaire
|
ST-38A, B, C : Stipa Lightnings à aile annulaire motorisée
|
CS-38A, B, C : premiers Lightnings hydravions pour la Coupe Schneider (inspirés du somptueux livre Speedbirds volume 1.2)
|
CS-38D, E : suite des Lightnings pour la Coupe Schneider
|
CS-38F, G, H : nouvelle suite des Lightnings pour la Coupe Schneider, avec flotteurs antiques ou foils modernes
|
CS-38J, K, L : Lightnings à flotteurs + hydrofoils
|
CS-38M, O, N : autres Lightnings marins de course inspirés par Speedbirds Volume 1.2
|
JA-38A, B, C : Jackynings dessinés pour mon fils : train, tracteur, Disney plane
|
JI-38A, B, C : Cartoon-Lightnings inspirés du dessin animé Jimbo-Jet, de Budgie-the-little-helicopter, et synthèse personnelle finale, volant les yeux fermés...
|
DQ-38A, B, C : Lightnings à Double Queue plus ou moins décalée
|
DQ-38D, E, F : Lightnings différemment multidérives
|
Bf-138A, B, C : Lightnings dérivés de mes projets de maquette Bf-109½
|
Bf-138D, E, F : autres dérivés du délire Bf-109½ 
|
JAC-38A, B, C : dialogue avec mon fils - son dessin, mon interprétation, sa correction
|
FL-38A, B, C : dérivés Lighnings d'un brevet Fairey-Lobelle de 1938/1939 (GB515562)
|
SP-38P, Q, R : Astronefs Lightnings dessinés pour un concours "Beyond the Sprues"
|
W-38R, O : Lightnings lunaires (sol et orbite) suggérés par Weaver
|
ME-38A, B : Lightnings solaires comme astronefs mystérieux de Mercure ou comme satellites terrestres
|
JC-38R, O, O-2 : Lightnings lunaires au sol et dans l'espace, imaginés avec l'aide de jcf
|
VA-38, SW-38 Ericraft : autres astronefs Lightnings, avec énergie du vide ou voile solaire
|
LSS-38 : Litening Space Station, à 2 modules d'évacuation asymétriques
|
BP-38A, B, PP-38B : Lightnings bipropulsifs ou push-pull à hélices entrainées à distance
|
Wea-38BW, LW-38A, MF-38A : autres Lightnings astronefs, dessinés suite aux suggestions de Weaver et Kerick
|
MF-38B, C, D : versions plus proches du modèle d'astronef Mak Falke
|
RO-01, 02, 03 : soucoupes volantes tombées sur Roswell en 1934, ayant inspiré le dessin du Lightning
|
XFA-38A, 38B, 76A : intermédiaires entre le P-38 pusher canard et l'astronef XFA-77A Falcon d'Aeroplanedriver
|
UI-38A, 38Z : versions à long rayon d'action de l'UFO Interceptor model
|
Por-38A, B, C : ancêtres du Porax-38 extra-terrestre
|
MO-38L, O, O-2 : rouleur et orbiteurs lunaires inspirés de modèles 3D TurboSquid
|
SPL-38A, B, C : Lightnings astronefs inspirés du Space P-38 Lego de Sir Bugges
|
TIE-38A, B, C : Lightnings astronefs inspirés du TIE de Star Wars
|
|
– BP-38W : Lightning d'exoplanète inspiré par le Bespin Cloud Car signalé par Weaver – BP-38X : version fusée du BP-38W – YK-38A : version marsienne du P-38 adaptée à une atmosphère peu dense, avec hélice bipale blocable horizontale pour se poser au sol (merci à Dr YoKai) 
|
PSS-38 : Lightning spatial qui aurait inspiré le Space Ship 2
|
SC-38A, B, C : dérivés (ou ancêtres ?) P-38 du Space Chaser/Dream Chaser
|
CO-38 : astronef à décollage vertical inspiré de la série Cosmos 1999
|
SF-38A, B, X : Lightnings inspirés de divers modèles de science-fiction
|
NA-38A, B, C : Lightnings astronefs inspirés par une recherche Google sur "Naboo spacecraft"
|
|
– BUI-38A Buildning : Double-Lightning servant de support à un restaurant d'aviateurs au Viet-Nam – BUI-38TV Thu-Van : version de BUI-38A retourné à la vie aérienne, avec immense endurance – MI-38 : hybride de P-38 et Miles M.22 
|
DI-38C, P, S : vedettes Disney Cars/Planes/Spacecraft si Hollywood avait osé prendre en compte le Lightning. 
|
NU-38A, B : Ligntnings nucléaires à cockpits éloignés et allumage solaire
|
R38 complet et tête seule : missile Ligtning à double tête avec la technologie de 1938 (feux d'artifice)
|
MAG-38A, B, C : astronefs à propulsion magnétique dérivés du P-38
|
JF-38A, B, C : planeur et jets dérivés du Lightning III de José Fern
|
AT-38A, B, C : dérivés Lightninguisés de l'Atlas de José Fern (P-38 à ailes tandem et faible envergure, pour porte-avions?)
|
JF-38D, AT-38D et E : versions plus proches des modèles Lightning III et Atlas
|
PZ-38A, B, C : astronefs Lightnings à propulsion mentale
|
|
– GU-38A Gullining : porte-avions volant du pays de Gulliver, avec extra-terrestres géants et nains – GU-38B : version pour nains seuls, terrestres 
|
|
– P-38EM : Lightning Excursion Module lunaire, 1939... – P-38EM-2 : version biplace du précédent – P-38MR : Lightning Mars Rover 
|
TF-38D, E, F : astronefs dérivés du Thunderfighter de Buck Rogers
|
|
– AI-38 : ancêtre Lightning de l'Angel Interceptor – SJ-38 : version mono-réacteur – SB-38 : version à moteurs séparés des poutres 
|
|
– XP-37-0 : projet Lockheed battu par le Curtiss YP-37 – P-38MM-1 : mélange de P-38 arrière et XP-37-0 avant (inspiré du Méli-Mélo des animaux) – P-38MM-2 : mélange de P-38 avant et XP-37-0 arrière 
|
|
– MA-38A : Lightning triplace à moteur arrière – AI-38B : ancêtre du double Angel Interceptor – CA-38 : vrai catamaran Lightning 
|
VS-38A, B, C : voitures volantes astronefs, inspirées d'une maquette de Goonie
|
SA-38A-6, 7, 8 : versions inspirées par le SA-386 de TheXHS sur DeviantArt
|
CO-38A, B, C : versions inspirées par le Cormorant flying boat de Packie1984 sur DeviantArt
|
SR-38A, B, C : les ancêtres du SR-71 n'étaient pas les B-71...
|
P-58Ds, E3, Fw : dérivés du Chain Lightning standard (Droop-Snoot, Three-Engined, Flying Wing)
|
Sandiego89 XBU-38, YBU-38, BU-38A Bunsen : versions à réaction partant de changements minima
|
QS-38A, B, C : hydroplaneurs Lightning
|
FE-38A, B, C : Lightnings de reconnaissance électronique
|
OF-38A, B, C : Lightnings de reconnaissance visuelle
|
OF-38D, E, F : autres Lightnings panoramiques
|
|
– W-38K (U-38) : Lightning de reconnaissance à haute altitude imaginé par le what-if modeller Weaver pour le maquettiste PR19_Kit – OF-38G, H : double-Lightnings de reconnaissance 
|
OF-38J, OF-38K, FE-38D : autres Lightnings de reconnaissance, asymétriques
|
|
– CIA-38 : avion-espion véridique (nom imaginaire) vu sur Internet en photo – CIA-3838, 3839 : versions double et semi-demie du précédent 
|
|
– CF-JJA : avion-reco véridique vu sur Internet en photo – CF-38A, 38B : versions dérivées du précédent 
|
ROS-38A, B, C : avions de reconnaissance d'OVNI, Roswell 1944...
|
ROS-38D, E, F : autres avions bizarres de Roswell 1944, cherchant à ressembler aux intrus extra-terrestres
|
OF-38L, M, N : variantes de Lightning à observation avant
|
OF-38P, Q, R : variantes de Lightning à observation arrière
|
|
– NP-38N : Lightning nucléaire à réacteurs radio-actifs – PJ-38P-1, -3 : Lightnings à pulsoréacteurs 
|
|
– PZL-38 Wilk : avion contemporain du Lightning – PZL-38C, 38D, 38Z : version de Wilks voulant ressembler aux Lightnings 
|
P-38PZ-1, -2, -4 : Lightnings venant à la rencontre des PZL-38 fantaisie
|
|
– AL-38S : avion de ligne à luxe panoramique – AL-38T : version recentrée de l'AL-38S – TI-38 : version de tourisme individuel ou d'observation officielle 
|
DR-38A, B, C : triples et double Droop Snoot non conventionnels
|
DR-38D, E, F : triple et doubles Droop Snoot trimoteurs
|
SP-38PL, SP-38ST : hydravions Lightnings à flotteurs-poutres dérivés de Levasseur et Strode
|
SP-38DO, SP-38FW : hydravions Lightnings à flotteurs-poutres dérivés de Dornier et Focke-Wulf
|
SP-38BI, SP-38DB : hydravions Lightnings à flotteurs-poutres à parties doublées
|
L-1038, L-1138, L-1238 : Constellightning, Super-Constellightning, Trans-Constellightning
|
Constellightoga, Constellightosy, Constellightophe : versions transport de fret
|
|
– TBFB-38 : pompier bipoutre du ciel – JM-38 : version Lightning de l'avion inventé par Jacky Meunier – Twin-Hull Liner : hydravion de ligne dont aurait été dérivé le Lightning 
|
Twin-Fuselage Liner, TFL-2, TFL-3 : versions modulaires de Lightning avion de ligne
|
TFL-1, TFL-J, L-1010 Tristar : autres avions de ligne bifuselages dérivés du Lightning
|
SAP-38A, B, C : planeurs de tourisme basés sur le Lightning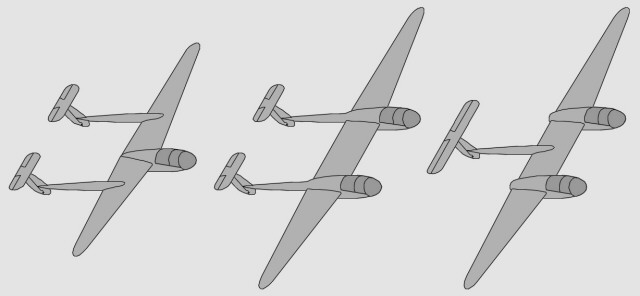
|
L-1010W, L-1010Q Quad-star, L-1010Q-2 : dérivés du Tristar bifuselage à centre de portance reculé (merci à Weaver pour sa remarque)
|
TMJ-38A, B, C : dérivés réduits des L-1010W/Q, avec petits réacteurs Turbomeca
|
L-1010X, Y, Z : transition entre le L-1010W et le célèbre L-1011 monocabine
|
TMJ-38D, E, F : dérivés réduits des L-1010X à Z, avec petits réacteurs Turbomeca
|
Lightning Clipper en vol et à l'amérissage, LC-38 en vol
|
AL-1038A, B, C : avions de ligne asymétriques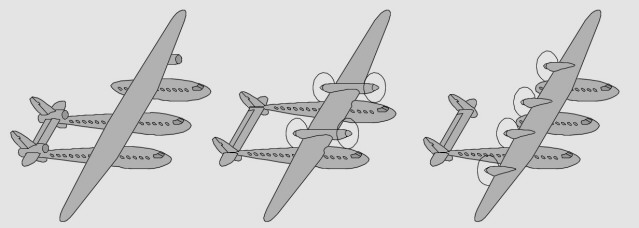
|
UB-1038A, B, C : avions de ligne Lightnings à fuselage porteur type Burnelli
|
BJ-38A, B, C : avions de transport rapide de quelques business-men
|
Lightningiro, Lightningiro-2, Lightningiro-3 : autogires de tourisme dérivés du P-38
|
II-38A, B, C : hydravions de transport de quelques passagers inter-îles
|
II-38D, E : dérivés inusuels des premiers II-38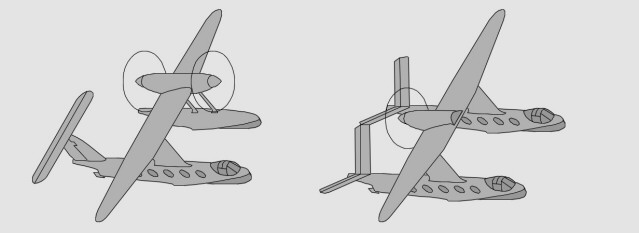
|
Loughead L-38, L-38B, L-38C : ancêtres du P-38, datés 1918 sur une autre planète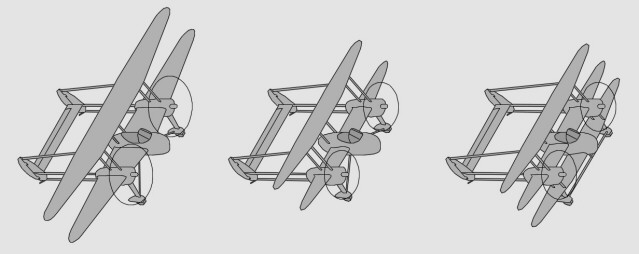
|
Loughead L-38A2, L-38B2, L-38C2 : versions biplaces des L-38
|
Loughead L-38D4, L-38E4, L-38E4F : versions quadrimotrices des L-38
|
Loughead L-38A1, L-38B1, L-38C1 : versions "monomoteur asymétrique" des L-38
|
Loughead L-38C1', L-38F1, L-38F2 : variantes modifiées des L-38
|
Burnelli-Loughead L-38G, G1, G2 : variantes à fuselage(s) porteur(s) des L-38
|
|
– Loughead LR-38A, B : L-38 à long rayon d'action – Loughead-Dunne L-38H2, H1 : L-38 ailes volantes 
|
|
– Loughead L-338A : projet de science-fiction en 1918, oubliant de mettre en question les dogmes biplan et cockpit-ouvert – L-38Z, Z2 : doubles L-38 à la mode Zwilling du Fokker M9 
|
Loughead L-37A, B, C : monoplans consolidés de 1917, ancêtres des L-38
|
Loughead XL-38W, YL-38W, L-38W : évolution d'hydravion en 1918, ayant inspiré le Caproni Noviplano de 1921
|
Loughead-Gallaudet L-38J1, J2, J3 : dérivés Loughead du Gallaudet D-4
|
MA-38B, C, D : multimoteurs asymétriques dérivés du P-38
|
L-38K1, K2, K3 : variantes canard des L-38
|
L-38K1', K2', K3' : variantes consolidées des L-38K1, K2, K3
|
L-38O1, O2, O3 : variantes à aile en O des L-38
|
Biz-38A1, A2, A3 : P-38 bizarres asymétriques
|
Biz-38Z1, Z2, Z3 : doubles Biz-38, finalement pas du tout bizarres, ou presque
|
L-38X, X2, X3 External Observer : avions d'observation à observateur externe
|
AGL-38A, B, C : premiers pas de Loughead dans les autogyres
|
ERP-38F, G, H : bifuselages inspirés par une maquette CAMS-Grumman d'Ericr
|
ERP-38J, J², H² : évolution des hydravions ERP-38H
|
XJT-38, YJT-38, JT-38 : transition vers un Lightning à réaction à partir du P-38 standard
|
L-38R8, L-38R14, L-38EC : très vieux Lightnings à moteurs fusées ou cockpits intégrés
|
JT-38A, B, C : variantes simplifiées de Jet-Lightning P-38
|
HYP-38A, B, C : dérivés hydravions bicoques du Lightning
|
|
– Loughead L-38M : monoplan pour faire moderne en 1918 – L-38N à aile annulaire antique – L-38N2 correction du L-38N par mon fils Jacky ayant vu le Snecma Coléoptère 
|
UG-38A, B, C : moches Lightnings inspirés des LWS-4, Amiot 143, Potez 540
|
DEP-38A, B, C : Lightnings à nacelle déportée loin de l'aile
|
DEP-38D, E, F : dérivés grossis du modèle DEP-38C
|
JK-38A, B : dérivés Lightninguisés d'un avion inventé par mon fils de 5 ans, Jacky, avec sa boîte de Légo Disney Planes
|
|
– JK-38C : autre invention Légo de Jacky, voiture volante à hélice ne raclant pas le sol ! – JK-38D, E, F : délires de son Papa pour bipoutriser l'avion et le stabiliser au sol... 
|
JK-38G, H, J, K : pas besoin d'hélice pour une voiture volante "en jouet", la "propulsion mentale" suffit...
|
JK-38L, M, N, O : autres dérivés Lightning de deux constructions Légo par Jacky
|
NH-38A, B, C : nouveaux hydravions Lightnings biflotteurs
|
Rolls-Royce P-38RR Radar-Rocket : Lightnings à moteurs fusées et nez radars
|
|
– VLR-38 Very Long Range Ligntning : version du P-38 à immense rayon d'action (transatlantique, avec réservoir dans l'aile) – SCF-38 Secure Flightliner : avion de ligne à hélices carénées pour qu'une pale détachée éventuelle ne heurte pas les passagers – SCF-38A (PW-38TF) : version du précédent reconstruite avec modernes turbofans (réacteurs à double flux) 
|
|
– DVP-38 : aéronef Lightning à décollage vertical – DLP-38 Double Liner : avion de ligne double inspiré du Lightning – DLP-38A Half Double Liner : demi-double avion de ligne 
|
L-38CW, CW2, CW3 : premiers avions et hydravion à Aile-Canal (Channel-Wing) au monde
|
L-38HP1, HP2, HP3 High Pilot: variantes de Loughead L-38 à pilote haut
|
L-38SP1, SP2, SP3 : variantes hydravions des Loughead L-38HP, assez normales, elles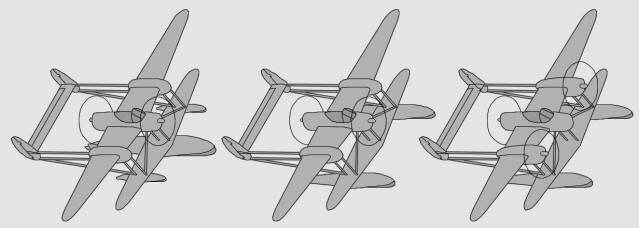
|
LCT-38A, B, C Low Cost Trainers : appareils d'entrainement formant une douzaine d'élèves par vol
|
LCT-38D, E, F : prototypes monoplaces des futurs LCT-38A, B, C
|
Loughead L-38S-55, 55B, 55A : ancêtres (du Lightning et) du Savoia S.55
|
JK-38P, Q : dérivés Lightnings autogyres d'une nouvelle construction Légo par Jacky
|
|
– DC-38P Dakoning : avion de ligne quadrimoteur construit à partir d'un Lightning et d'un Dakota – DC-38Q Lightota : même principe construit avec maquettes P-38 au 1/48 et DC-3 au 1/72 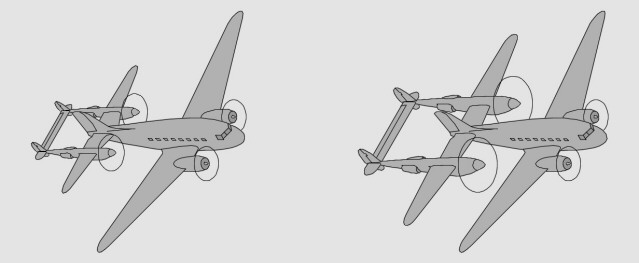
|
|
– DC-38R : version purement Lockheed du DC-38P – DC-38R4 : version quadri-fusée à décollage court 
|
WL-38, WL-38A, WL-38B : Lightnings de course à faibles charge alaire et envergure
|
DC-380L, H, P : avions de ligne Lightnings à fuselage large et aile basse/haute/parasol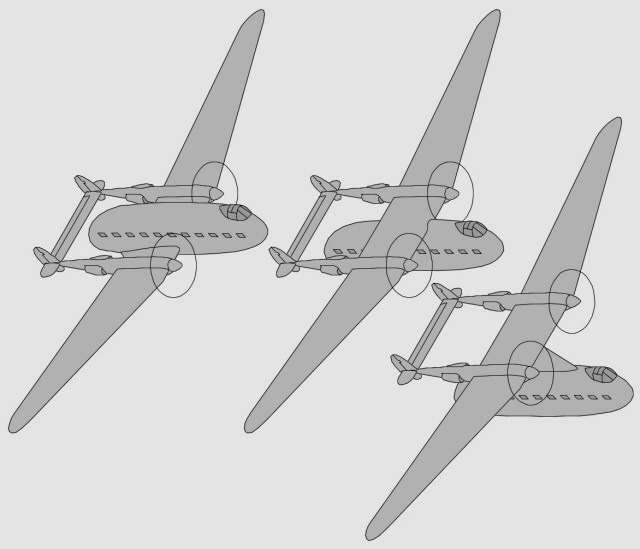
|
DC-380E4F, E4L : versions quadrimotrices en sous-versions première classe et premier prix
|
vers le LP-38PZ : selon des évolutionistes américains, de l'Université Monservo, le Lightning a pour ancêtre un triple Pégase de la famille Little Pony
|
|
vers le LP-38PZ-2 : la version à hélices rapprochées du Lightning (moins asymétrique si un moteur tombe en panne) est aussi liée à une origine Little Pony vraisemblable (à long cou ou nez court), la paléonthologie le dira...
|
|
– LP-38Z-2A, Z-2B : dérivés (civils) du Lightning à hélices très rapprochées – JK-38R : nouveau Lightning inspiré d'une invention Lego de Jacky 
|
|
– SK-38 : Lightning sur skis sans jambes trop longues – HDSK-38 : Demi-Double (Half-Double) avion sur skis – DSK-38 : ce n'est pas un violeur pervers échappant à la Justice mais un Double avion sur skis 
|
TR-38A, B, C : mixes de Lightning et Tristar(s) à échelles différentes
|
DD-38A, B, C : Lightning-Liners à double-pont (double-deck)
|
PLi-38A, B, C : Panoramic-Liners à base Lightning de taille double
|
SCa-38A, B, C : Super-Cargos civils dérivés des Panoramic-Liners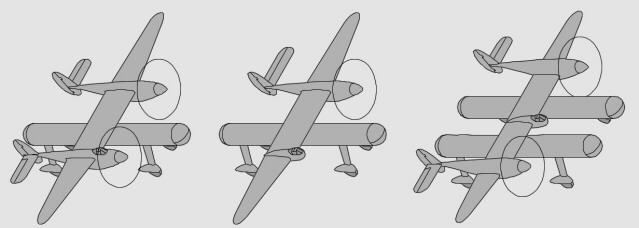
|
ALL-38A, B, C : dérivés Lightning du travail sur des Heinkel Uhu par le what-if modeller Allan
|
SPA-38A, B, C : dérivés Lightning de l'avion de ligne à immenses trains pantalonnés (spats)
|
DW-38, GU-38, GUL-38 : avions de ligne pour personnes de petite taille, pour Lilliputiens (compagnie Gulliver-Voyages), et à aile en mouette (gull-wing)
|
|
– LL-38Y : ancêtre du Lightning à ailes tandem et fuselage haut – P-38P-61A et -61L : mixes de Lightning et Black Widow 
|
Supermarine Lightning Mk.III, IV, V: mixes de Lightning et Spitfire
|
Supermarine Twin-Lightning Mk.I, II, III: doubles plus ou moins réduits du Supermarine Lightning Mk.III
|
|
– L-38RA : ancêtre du Lightning à moteurs en étoile – F-38JT-2, JT-3 : avions à réaction inspirés du Lightning 
|
P38M4, M5, M6 : nouveaux mixes de Lightnings et Zeros
|
|
– L-38TJ : ancêtre du Lightning avec le premier turboréacteur – F-38JT-3, JT-4 : jet-Lightnings à poutres courtes 
|
AF-38JT-1, JT-2, JT-3 : Lightnings asymétriques à propulsion mixte pistons + jet
|
BF-38JT-1, JT-2, JT-3 : versions assagies des AF-38JT, rendus symétriques et purement jets
|
XAW-38, YAW-38, AW-38 : Lightning devenant progressivment une aile volante
|
PN-38A, B, C : Lightnings Pas Normaux...
|
LECP-38D, E, F : Lightnings à base de moteurs latéraux et hélices cntrales
|
|
– SP-38SP : vieux Lightning à énormes roues – L-38FR-1, FR-2 : vieux Ligntings monomoteurs à nez et arrière libres 
|
|
– L-38RH-1, RH-2 : vieux Lightnings à aile rhomboïdale – L-38CAN : vieux Ligntings canard à dérives arrières 
|
P-38TR-2, -3, -1 : hybrides de Lightning et Trislander
|
F38L1, 2, 3 : versions du Lightning pour la marine
|
F38L4, 5, 6 : autres versions à un moteur radial tractif
|
F38L7, 8, 9 : nouveaux monomoteurs radiaux tractifs
|
|
– TPLX-38 : tripoutre Lighnting trimoteur – VP-38B, C : Lightnings bipoutres verticaux 
|
VP-38Z-1, -2, -3 : quadripoutres obtenus en accolant des VP-38B et C
|
F38L10, 11, 12 : autres Lightnings monomoteurs radiaux
|
|
– SP-38NL, NL-4 : Lightnings à flotteurs porte-moteurs – SL-38RD : Lightning à flotteurs et défense arrière 
|
PLD-38A, B, R : Lightnings amphibies pour appui de débarquements
|
|
– Prin-38A : concurrent Lightning du Saro Princess – PB38L-1 Lightalina, PB38Z-1 Twin-Lightalina : dérivés Lightning du PBY Catalina 
|
Prin-38B, C, D : variantes multicoques du Prin-38A
|
Jackning, Sea-Jackning, Sea-Jackning-3e : caricatures de Lightning (terrestre et hydravions) réalisées avec mon fils Jacky
|
Twin-Sea-Jacknings et Asymmetric-Sea-Jackning : variations fantaisie
|
Remorqueur Sea-Jackning-6e tirant dans les airs un hydroplaneur Sea-Jackning-Zero
|
Variantes JK-38AS1, AS2, AS3 de Sea-Jackning asymétrique
|
JP-38J-2, J-1, J-3 Jet-Sea-Lightnings
|
Les JP-38J-1Z et J-3Z Twin-Jet-Sea-Lightnings évitaient l'emploi de petits flotteurs de stabilisation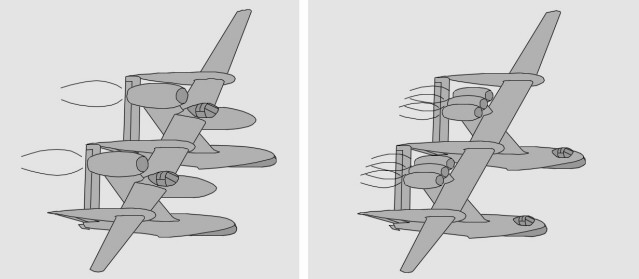
|
|
– DN-38DZ Siamese-Lightnosaure : reconstitution d'un dinosaure siamois dont les os ont été trouvés dans la terre américaine – DN-38HZ Siamese-Plesioning : reconstitution d'un dinosaure marin asymétrique siamois à partir des os trouvés (peut-être incomplets) – DN-38D, DN-38H : (vraisemblables) versions non-siamoises des dinosaures jumeaux trouvés 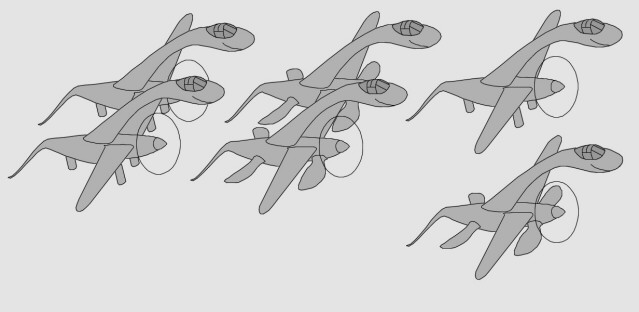
|
|
– Lockheed TH-38 : reconversion de P-38 en hydravion bicoque – Hurel-Dubois TH-38HD : modification à aile de grand allongement – Delanne TH-38DE : modification à ailes tandem 
|
VD-38, VD-38PP : Lightnings marins à aile-fleur pour la Saint-Valentin ("cadeau" pour Emelyn en version couleur)
|
L-38A-6A, 6B, 6C : Lightnings avions de ligne dessinés suite à l'invention Anatra A-6 par le what-if modeller Default Setting
|
|
– L-38A-6D : version de A-6 à moteurs en ligne suggérée par le what-if modeller Captain Canada – L-38A-6DX : prototype du A-6D sans passager, pour test – XP-38DX : prototype militaire inspiré du L-38A-6DX 
|
|
– Cola-38 : hydravion Lightning inspiré d'un jet supersonique dessiné par le designer Luigi Colani, ici avec poutres rapprochées – Cola-38P Pepso : dérivé civil du Cola-38 – Cola-38C Coco : dérivé militaire du Cola-38P 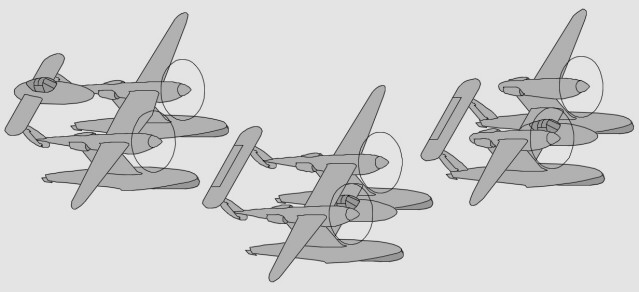
|
|
Cola-38D, E, F : dérivés du Cola-38C
|
CB-38A, B, C : bimoteurs Lightnings à poutres très proches
|
RP1-38A, B, C : Lightnings pousseurs canards biplaces côte-à-côte, sur skis, dessinés à partir d'une création Lego du maquettiste RP1
|
P-38Moo-1 Moonning, -2, -3 : versions à aile en croissant de lune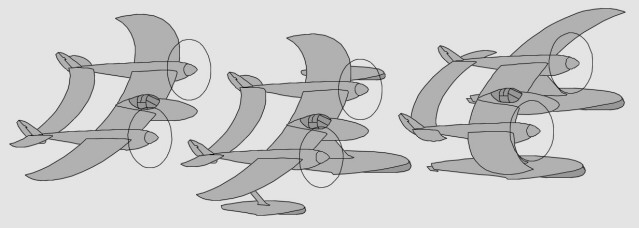
|
Lockheed P-138 Tricerightning, Kawasaki Ki-138 Lightniceratops, Ki-238 Lightniceratops-Futago
|
Pétrent'huitératops, et jumeaux siamois de la même famille (vrais dinosaures)
|
|
– SuperMan #38 : super-héros (avec vol supersonique par énergie mentale) vainqueur d'un concours de dessin pour les enfants d'ouvriers Lockheed – SM-38SM : avion à aile coton battante inspiré de SuperMan #38 – SM-38BM : dérivé batmanisé du modèle SM 
|
|
– XNF-38 :chasseur de nuit à yeux multiples avant invention du radar – YNF-38 : essai de projecteur embarqué – NF-38A : biprojecteur bimoteur bipoutre 
|
P-38LM Lightning Major, LM-2, LM-3 (ou XP-117 Blackning, YP-117, P-117A) : versions surpuissantes à moteur(s) en étoile R-4360 Wasp Major de 5000 chevaux, avec problème de couple déstabilisant
|
XP-38* Lightning Star et YP-38* : avions-étoiles inventés par Jacky Jemsey à l'âge de 5 ans et demi
|
AsL-38A Asymmetric Lightning, AsL-38B, AsL-38C : Lightnings compacts, versions asymétriques
|
AsL-38D, E, F : Lightnings asymétriques encore plus compacts, en avançant un moteur
|
XPPP-38E Ericring, PPP-38E, PPP-38E-2 : dérivés bipoutre du triple Droop Snoot construit par le what-if modeller Ericr (le maquettiste Flyer a inventé le E-2)
|
XF-13L, YF-13L, F-13L Lightnireco : dérivés presque crédibles des PPP-38E
|
CBR-38A, CBR-38B, Cerbère-38 : avions à gueules de requins au sens propre, et monstre les ayant inspirés
|
Pug-38A, B, C : avions canins (molosses carlins) à flair inégalable
|
Hydroning A, B, C : hydravions à moteurs dissociés des poutres
|
ABu-38 A, B, C : asymétriques Lightning à-la-Burnelli
|
ABC-38 A, B, C : Asymétriques Burnelli Canards dérivés du Lightning
|
P-38X-2, P-38X-2P, P-38Sam : Lightnings quadrimoteurs à pilote normal ou couché au dessus des moteurs droits, et dérivé bomoteur asymétrique
|
|
– Modelnut53's Canard P-38 : avion hybride à base de P-38 Lightning surtout mais aussi P-47 Thunderbolt et P-51 Mustang – Tophe's Canard P-38 : modèle dérivé du précédent mais avec un peu davantage de côté Lightning – Toff's Canard P-38 : dernier pas vers le Lightning standard 
|
XMCP-38Z, YMCP-38Z, MCP-38ZA : versions doubles du Modelnut's Canard P-38
|
AsyMN-38A, B, C : versions asymétriques du Modelnut's Canard P-38
|
AsyMO-38A, B, C : versions asymétriques non canards
|
MO-38A, B, C : versions symétriques des précédents
|
P-38J²TT, TP²TT, PP²TT : Lightnings à empennage en double T avancé, employant deux réacteurs, ou deux turbopropulseurs, ou 2 moteurs à piston propulsifs
|
M-38, M-38Z, M-38Z2 : substituts de Mirages à base de Lightnings, pour atteindre Mach 2 ou Mach 4 (vers l'an 1950)
|
|
– XRP-38Do : Lightning de reconnaissance camouflé en petite fille ("Dora l'exploratrice") pour ne pas être sauvagement abattu – RP-38Do : version industrielle du précédent – RP-38DoZ : version jumelle du précédent 
|
P-38PA, YP-38PA, XP-38PA : mignonne caricature de Philippe Abbet dans LuftGaffe44 tome1, et chaînons manquants avec le P-38 standard
|
P-38PA-1, PA-1A, PA-1B : versions monomoteurs que j'imagine pour le Lightning de Philippe Abbet
|
P-38PAZ-4A, PAZ-4B : versions Zwilling que j'imagine pour le Lightning de Philippe Abbet
|
P-38PAZ-3A, PAZ-3B, PAA : autres versions que j'imagine pour le Lightning de Philippe Abbet
|
P-38BE-1, BE-2, BE-3 : Lightnings à (très) gros moteur, plus que double
|
P-38ER-1, ER-2, ER-3 : intermédiaires entre le P-38 avion et la géniale maquette P-38 Cerberus (sans hélice) du what-if modeller ericr
|
P-38WD-8, WD-9, WD-10 : famille de Lightnings à poutres portantes/poutres alaires inspirées du Willoughby Delta-8
|
P-38P-51, P-52, P-53 : Lightnings d'après-guerre, inspiré du P-51D Mustang, puis avec motoréacteurs et enfin turboréacteurs
|
P-38DJ-1, DJ-2, DJ-3 : Lightnings inspirés par le modèle DJ01 Gémeaux du what-if modeller tonton42
|
X-38A, B2, C : Lightnings lancés contre la barrière du son... (le réacteur paraissait fantaisie mais l'aile en fèche : une bonne idée)
|
KM-38, YKM-38, KM-38A, XKM-38A : versions diverses correspondant au profil dessiné par le what-if modeller Karl Mesojednik (de http://www.karlsaircraftart.com/, ou KM signifie Knowlelge Management, maîtrise du savoir, tant cet avion est véridique...?) en s'inspirant de mon P-38J²TT
|
KM-38Z, YKM-38Z, XKM-38Z : versions doubles des KM-38 symétriques
|
KM-38ZA, YKM-38ZA, XKM-38ZA : versions doubles asymétriques des KM-38
|
KM-38B-1, B-2, B-3, B-4 : versions discrètement asymétriques du biréacteur équilibré KM-38
|
KM-38C-1, C-2, C-3 : autres versions biréacteurs asymétriques, semi-biplane, semi-fusée, et aile en flèche avant/arrière
|
KM-38T-1, T-2, T-3 : versions triples du KM-38
|
KG-38A, B, C : Lightnings royaux, avions ou hélicoptères
|
Pr-38, PRe-38, AM-38 Aambulightning : Lightnings à observateur avant couché, à poste arrière, Lightning ambulance inventé par Jacky Jemsey M.
|
P-38 triplace véridique, ERI-38S-9, ERI-38S-12 : à partir d'une trouvaille du what-if modeller ericr, dérivés très multiplaces
|
BM-38A, B, C : dérivés Lightning de l'avion Big-Mack inventé par le what-if modeller tonton42
|
DF-38A, B, C Dizzyfuning : version Lightning du Whirlwind radar inventé par le what-if modeller Dizzyfugu, et dérivés à radar plus compliqué à mettre en oeuvre
|
Lightinginer et pré-projets correspondants : avions de lignes rapides ou supersoniques
|
RUT-38A, B, C Raised Up Tail Lightnings : P-38 à queue réhaussée pour de bonnes raisons techniques
|
STa-38A, B, C Short Tail Lightnings : P-38 à queue raccourcie, en ailes volantes
|
Lightbulle Mk.2, 3, 4 : dérivés du Toff's Canard P-38 (Lightbulle Mk.1A) inspirés de la famille Spitbulle du what-if modeller tonton42
|
P-38TT, TT-2, TT-1 : Lightning à triple queue et dérivés
|
P-38Zw-1, Zw-2, Zw-3 : Twin-Lightning (Blitz-Zwilling) inspirés par les demandes du what-if modeller McColm pour un Neptune quadrimoteur
|
P-38Zs-1, Zs-2, Zs-1 : version monoplaces asymétriques des P-38Zw
|
P-38Zs-4, S-1, S-0 : lointains dérivés asymétriques des P-38Zw
|
P-38S-3, S-3B, S-2 : transition vers un bi-pousseur bipoutre à stabilisateur avant
|
PV-38 Verticalning, P-38TR, P-38TR-1 : Lightnings tailsitters à rotors
|
"7F Coop Flyer" : un Lightning inversé garanti Mach 3 en 1948 (ou combattant 1942 selon une autre source), et dérivés bifuselage et bipoutre
|
K-38A, 38NT et NT+ : avions du groupe américain Kameecase, avec dissuasion contre le saut en parachute de pilote craintif, menacé d'être coupé en rondelles...
|
XV-38A, X et C : Lightning tailsitters normal, à ailes en croix et inspiré du Coléoptère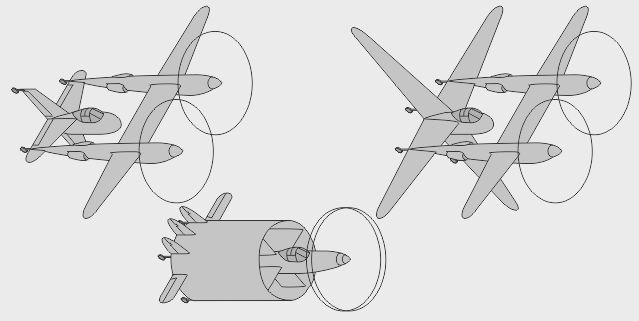
|
XF38O-1, -2 et -3 Lightcat : dérivés purement Lockheed de l'hybride P-38/Grumman XF5F Lightning/Skyrocket-Bobcat demandé par le what-if modeller Librarian (XF38F)
|
XF38O-4, YF38O-4 et F38O-4 : finalisation du Lightning naval
|
WC-38, WC-38B en 2e étape et 1e étape : l'hydravion cargo imaginé par le what-if modeller Wuzak a été transformé en avion de ligne à cabine-passagers largable à mi-chemin (avec parachute)
|
KhAI-38A, B, C : dérivés du Lockheed KhAI-38 lui-même dérivé du Kharkov KhAI-3
|
XP-38LK, YP-38LK, P-38LK : dérivés Lightning du Bélyayèf DB-LK
|
K-38TT, P-38KK (P-38FF en version française), X-38R : autres dérivés rapides du K-38A
|
MH-38, MH-3838, MH-3838B : Lightnings inspirés des Max Holste MH-20 (projet) et MH-2020 (fictifs)
|
F-83D, B, C : trimoteurs tripoutres hybrides de Lightnings et Mustangs
|
XP-38P-51, YP-38P-51, P-38P-51 : hybrides de Lightnings avec une grosse jolie verrière de P-51D Mustang (à échelle différente, ou pour gros-grand pilote)
|
XC-38P-51, YC-38P-51, C-38P-51 : versions Cartoon/Caricature des hybrides Lightnings-Mustangs
|
|
– Le XFP-38 (P-38 avec fan expérimental) aurait eu une soufflante basculante, pour décollage vertical ou bien croisière horizontale. – Le YFP-38 dérivé, toutefois, serait à nouveau un avion assis sur la queue. 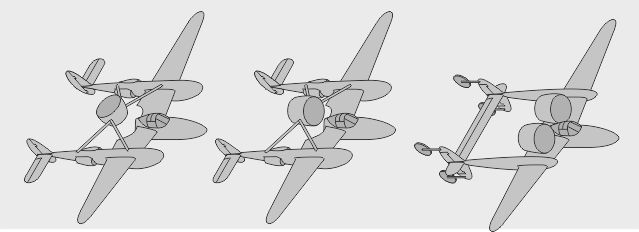
|
HA-38, 38A, 38B : ancêtre du Harrier et dérivés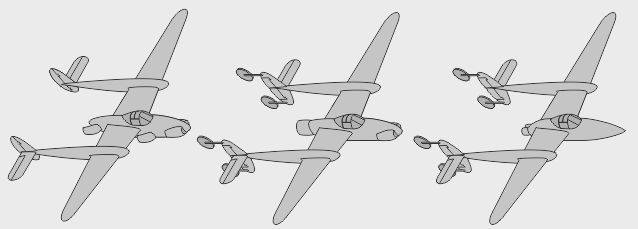
|
XP-38DB, YP-38DB, P-38DB : Lightnings inspirés de la lignée Dyle et Bacalan (similaire aux Burnelli) 
|
C-38DB, C-38DB-2, C-38DB-3 : dérivés à réaction du P-38DB
|
|
– PM-38F : Lightning original à profils, inspiré de celui trouvé à paper-model-airplane.com – XPM-38F, YPM-38F : chaînons manquants entre le P-38 standard et le PM-38F 
|
XP-38W-3, YP-38W-3, P-38W-3 : Lightnings de nouvelle génération, vers 1946
|
XP-38W-3C, YP-38W-3C, P-38W-3C : versions canards des W-3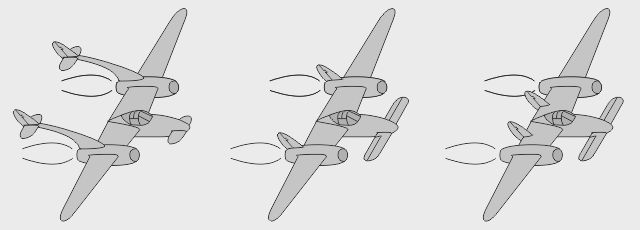
|
XF-38W-3C, YF-38W-3C, F-38W-3C Mightning : versions moins Lightning des P-38W-3C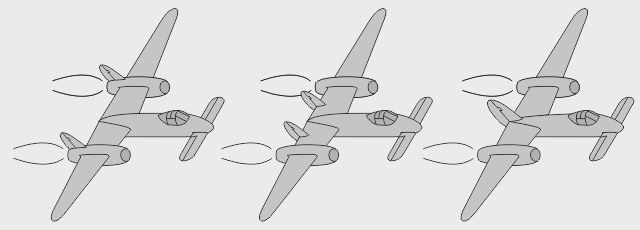
|
F-38WZ-2, F-38WZ-3, F-38WZ-1 Twin-Mightning : versions bifuselages du Mightning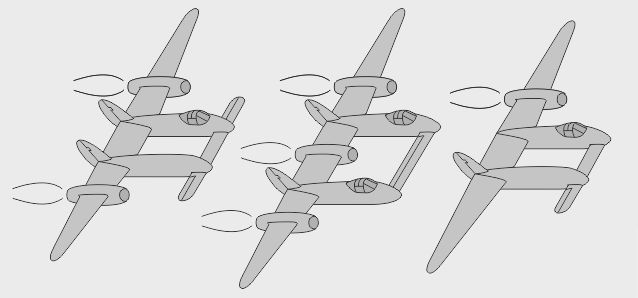
|
F-138A Oightning, F-238A Pightning, F-238H Half-Pightning : versions supersoniques dérivés lointains du Lightning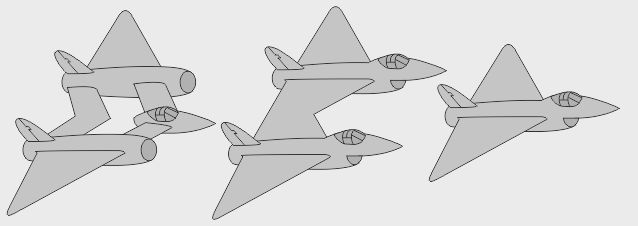
|
A-38WF, A-38WG-614, A-38WS : versions à réaction pour basse altitude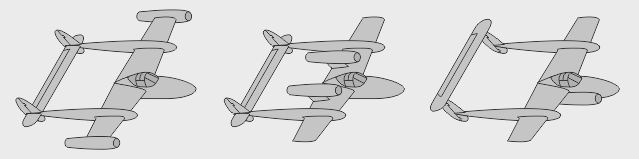
|
XA-38W, YA-38W, A-38WA : versions finalisées des préprojets A-38W
|
CV-38A, B, C : Lightnings cargo-jet ancêtres du Carvair
|
PTT-38A, B, C Fulmine : Lightnings d'entrainement à réaction, Pursuit Triplex Trainers, sans rapport avec les Postes Télégrammes Téléphones
|
WBP-38A, B, C : Lightnings inspirés du WarBug P-38
|
F-338A Qightning (ramjet Lightning), B, C : versions supersoniques de Lightning à moteurs fusée + statoréacreurs
|
Messerschmitt Me-38A, B, C Nightning : chasseurs de nuit proposés en 1946 en Argentine ?
|
P38W1, 2, 3, 4 : avions caricaturés pour la lignée totale du Lightning, finissant Made in China ?
|
Moc Page-38, Page 38A, Page 38B : Lightning Lego de Mocpages.com et dérivés à pièces de maquette moins carrée
|
P-74BO-1, -2, -3 : Versions du Lightning monomoteur pousseur à parachutage sans danger
|
P-74BO-4, -5, -6 Swoose Lightning : Versions du P-74BO optimisant la sécurité de parachutage sans sacrifier la solidité (avec empennage-maison ou canard ou canard-asymétrique)
|
TSF-38A, B, C Poning : Tail-Sit Fighters (chasseurs assis sur leur queue), à la Pogo, inspirés du P-38 Lightning modernisé fantaisie (aucun rapport avec la Téléphonie Sans Fil...)
|
IV-38A, B, C In Vitro Lightning : Lightnings à empennage ou aile en V inversé (Inverted V ?)
|
IV-38D, PSEC-38A, B : version monomoteur de l'IV-38B et Pursuit Single-Engined Cargos
|
RV-38A, B, C Voyajning : dérivés à pièces Lightning du célèbre Rutan Voyager
|
TBP-38 Trilightning, TBEP-38, TEP-38 : Lightnings étranges à 3 poutres et/ou 3 moteurs tractifs
|
PAS-38A, B, C Asymlightning : Lightnings asymétriques dessinés pour faire face au célèbre et étrange Bv-141
|
PAS-38D, E, F : Lightnings asymétriques à poutrelles
|
TBP-38B, C, D Trightling : dérivés du Lightning tripoutre avec tringlerie interne (le nom Trightling a été inventé par le what-if modeller PR19_Kit)
|
Me-380A, B, C Vogelightning : dérivés du Lightning avec pièces de Me-262 Sturmvogel
|
MiG-138A, B, C : dérivés des Me-380 façon MiG-15
|
IFA-38 Erining : Premier avion se transformant en asymétrique en vol, imaginé suite à l'idée du what-if modeller ericr
|
REP-38A, B, C Rearning : P-38 à 2 moteurs arrières, avec hélices encore plus arrières ou tringlerie vers une double hélice centrale
|
IcEr-38A, B, C Aerocar : Voitures monoplaces hors-ville dérivées d'avions, inspirées par les géniales maquettes du what-if modeller ErIcr
|
TBJ-38A, B, C : Lightnings muti-TurBoJets à ailes tandem ou quasi-aile-volante
|
PZ-38ZL-1, -2, -3 : Lightnings inspirés du PZL.37 Los
|
J7W38, 38B, 38C Shinding : cousins de Lightning inspirés du canard J7W1 Shinden très modifié par le what-if modeller Librarian
|
|
– Cave-38 : Lightning pentaroue à aile en flèche inverse, inventé par Jacky Meunier et baptisé par le what-if modeller tonton42 (CAVE = Compagnie des Aéronefs et Vélocipèdes Européens). – JC-38A : version du CAVE-38 de JaCky (ou Jésus Christ ?) retouchée par Papa Meunier. – Rest-38 : version de repos, reste des pièces ayant servi à construire le JC-38A 
|
PB-38PB Petit-Boutien, GB-38GB Gros-Boutien, GB-38GBB Gros-Boutien Biplace : avions-oeufs à la coque "pour de vrai"
|
|
Hommage à ma chère maman et ma chère petite soeur, via Lightnings interposés : – MF-38 Multi-engined Fighter rapide (ou Marie-Françoise) – NJ-38 Night-Jet à nez radar (ou Nathalie-Juliette) – JL-38 Jet Léger (ou Juliette épouse L.) 
|
|
Versions améliorées : – MF-38A à ailes tandem soutenant les poids sur l'arrière – NJ-38A biréacteur – JL-38A avec empennage surbaissé 
|
F-38R-1 Rocketning, R-2, R-3 : Lightnings fusées supersoniques... si la vitesse n'arrache pas les queues.
|
OPS-38A, B, C Obserning : Lightnings de reconnaissance à poste d'observation arrière.
|
DH-38A, DH-38B Mosquining, DH-38C : Lightnings en partie inspirés du De Havilland Mosquito, et modèle propulsif monohélice à micro-hélice latérale anticouple.
|
COP-38A & B Coinightning, COP-38Z Twin-Coinightning : avions COIN pour conflits dits asymétriques.
|
COP-38Z-2, Z-3, Z-4 : dérivés étranges du "presque crédible" COP-38Z.
|
CoiNL-38A, B, C : attaqueurs à armes Non-Léthales, avec filet (largué pour capturer ou ridiculiser le leader ennemi), ou ondes rendant pacifistes (en protégeant soigneusement le pilote), ou super-laser rendant aveugle en 1 microseconde
|
|
– MIS-38 : Mistel avec un petit drône à échelle 1/3 (inspiré d'un composute 1/48-1/144 construit par mon fils, 6 ans) – MS-38A : les remarquables performances du Mistel avant largage ont inspiré cet avion à petits moteurs et aile additionnels – MS-38B : version du MS-38 ne retenant pas la configuration bipoutre des éléments additionnels 
|
GBR-38A, B, C, D : Beegeening et Twin-Beegeening, dérivés du Gee Bee Racer, avion de course ancien
|
P-381A, D, J : North American Lightnings ayant inspiré les P-51A, D, XP-51J
|
|
– RBB-38 Returning Bullets Backwards : avion anti-violence à parabole renvoyant les tirs reçus – RBB-38B : version retournant les tirs sol-air – RBB-38H : version hélicoptère moins gênée par le caractère anti-aérodynamique de la parabole 
|
|
– RBB-38S (en vol de croisière) : version spatiale du RBB-38, mloins gênée par la trainée aérodynamique de la parabole – RBB-38S en vol stationnaire : position d'attente si la riposte tarde – RBB-38S-3 : version triréacteur (à 3 moteurs-fusées) améliorant la stabilité 
|
BEL-38A, B, C : transitions rhomboïdes entre Lightning et un projet ukrainien Belokon
|
BEL-38D, E, F : variantes quadrimoteurs du Lightning Belokon
|
SAAB J.38D, V, G : projets de Lightning suédois ayant inspiré les J.35 Draken, J.37 Viggen, J.39 Gripen
|
MESS-38A et LCT-38A : Multi-Engined Single-Seat 38 et Low-Cost-Trainer-38 auraient été des Lightnings larges
|
LiP-38A, B, C, D Little Lightning : petits P-38 simplifiés, de sous-classe "pusher" (pousseur, propulsif), essayant de gérer différemment le problème de couple moteur
|
VVLR-38, 38A : Lightnings intercontinentaux (Very Very Long Range) avec beaucoup beaucoup de place pour des réservoirs
|
NPFN-38A, B, C : Lightnings évitant nez-moteur et moteur-arrière (No-Pusher Free-Nose)
|
BvP.38A, B, C : Lightnings dérivés des Blohm und Voss P.165 et P.163
|
P-38Ki-46 Lightnah, P-38Ki-47 Dining, P-38Ki-48 Lightubishi : Lightnings jaloux de la beauté du Mitsubishi Ki-46-III Dinah, cherchant à lui ressembler
|
CoP-38D, E, F : nouveaux Lightnings asymmétriques, bifuselages ou monomoteur
|
P-38P-61, -62, -63 : hybride de Lightning et Black Widow, redevenant de plus en plus Lightning
|
GA-38A, TT, SP : Lightnings sans nez-canon, de General Aviation ("tourisme"), dont un planeur (SailPlane)
|
BS-38A, B, C : Statue en Bronze de P-38 (imprimée sur portefeuilles à www.zazzle.com), et dérivés "avions"
|
PPi-38A, B, C : Lightnings légers à pilote couché sur le ventre (prone pilot)
|
Lockheed F2O-1, -2, -3 : Lightnings marins monomoteurs asymétriques
|
SBt-38A, B, C : De la motomarine (scooter boat) Lightning à presque un vrai hydravion
|
GU-38 Gunship : Massacreur jouissif pour les adoreurs de la guerre.
|
PuPu-38A, B, C : push-pulls Lightning, pour essayer de recommencer à sourire, un petit peu.
|
CoP-38G, H, J : autres Lightnings asymmétriques, légers
|
FLI-38A, B, C : Lightnings inspirés des Focke-Wulf Flitzer, à moteurs fusées ou turboréacteurs
|
Pen-38C, 38F, 38B (PenCil, Feather-pen, Ball-pen) : Lightnings de St Exupéry imaginés par le what-if modeller ericr.
|
CoP-38K, L, M : hybrides de Lightnings asymmétriques et XP-67
|
P-38A-67, B-67, C-67 Moonbatning : hybrides de Lightnings normaux et XP-67 Moonbat
|
DV-38A, B, J : Lightnings inspirés des Davis Manta
|
CV-38HB, GD : projet de Lightning Crêpe Volante faisant face à l'avant et l'arrière, avec rotation vers le bas (en haut) comme envisagé par le what-if modeller Abtex, ou avec rotation vers la droite (en bas)
|
ATR-38A, B, C : dérivés Lightning d'un "Asymmetrical pusher" publié dans un numéro d'Air Trails en 1947.
|
ATR-38Z, Z-2, Z-3 : dérivés doublés des ATR-38, redevenant bipoutres, quoique asymétriques.
|
ATR-38Z-33, -33H, -33L : versions trimotrices d'ATR-38, avec variantes à aile de grand allongement ou faible allongement
|
TanP-38A, B : nouveaux Lightnings à ailes tandem.
|
XOB-38, YOB-38, OB-38A Obserning : observateurs aériens, avec petits moteurs V-770 pour finir.
|
XLighP-38, YLighP-38, LighP-38A Light Ning : versions légères à petites ailes (concurrents du XP-77) du lourd bimoteur P-38
|
WUZ-38A Lightnicobra, WUZ-38B Airaconing, WUZ-38T Twin-Airaconing : dérivés compliqués du Lightning, avec arbres moteurs entre les jambes du pilote, pour faire simple (inspiré du P-39 Airacobra, merci à Wuzak)
|
WUZ-38D, E, F : à la demande du what-if modeller Wuzak, tels sont les dérivés améliorés du WUZ-38B
|
LAN-38 en version petite aile ou aile large, LAN-38A : Ligtnings inspirés d'un gros projet Langley paru dans US Transport Projects #05
|
TBM-38A, B, C : Ligtnings différents, aménagés à partir d'une idée tripoutre
|
SQP-38A, B, C : Ligtnings sesquiplans bifuselage et bipoutres
|
SQP-38A2, B2, C2 : Ligtnings sesquiplans inversés, suggérés par le what-if modeller Flyer
|
SQP-38A3, B3, C3 : variantes des précédents avec moteurs hauts
|
GoP-38A, B, C : Ligtnings delta gothiques
|
SciF-38A, B, C, D : Ligtnings spatiaux du 22e siècle (ou de 2030 au moins)
|
SciFi-38A, B, C, D : Ligtnings terrestres du 22e siècle, avec moteurs aspirateurs au lieu (ou en plus) de moteurs pousseurs par réaction
|
XSPi-38, YSPi-38, Spi-38A Spidning : planeurs et avion araignées à 8 petites ailes (merci au what-if modeller Weaver ayant inventé cette idée)
|
A la demande de Weaver lui-même, voici le SPi-38W Centipning avion quasi-mille-pattes...
|
A la demande du what-if modeller Wuzak, est né le SPi-38W², un peu moins sous-motorisé
|
A la demande du what-if modeller Steelpillow, est né le SPi-38S Steelpining, dragon-ornithoptère à 60 ailes battantes (pas besoin de moteur, manger de la viande fraiche suffit)
|
Cloudning A, Cloudning H, Tie-38H, Tie-38X : Lightnings futurs inspirés du Cloud Car (+ version terrestre) et du Tie-Fighter (+ version étendue).
|
LS-38s : Lightnings spaciaux à la demande du rêveur abtex, avec cockpits biplaces, asymétrie à la Blohm und Voss, dérivés du Tie-Trainer et du Tie-V38 (bien nommé).
|
TriPl-38A, B, C : tri-Lightnings inspirés du Tristang du what-if modeller PR19_Kit.
|
TriD-38A, B, C : dérivés simplifiés des TriPl-38.
|
SPar-38A, B, C : Lightnings spaciaux-fusées.
|
Asi-38A, B, C : Asimightning presque simples
|
WIG-38B (en vol de croisière et au décollage), WIG-38C : Lightnings à réaction et effet de sol
|
P-38Asy, Asy+, Asy++ : Lightnings bimoteurs standards mais avec architecture asymétrique
|
GUI-38, GUIP-38, GUIP-38A : bipoutre Lightning hybridé avec une double guitare par le what-if modeller Ericr, et versions avions dérivées
|
Farman F-238B, A, C Beautning : dérivés de Lightning prétendus beaux à la française des années 1930
|
PL-38T, W, X Pretning : Lightning façon Airtruk PL-11/12 (Waitomo/Transavia) en un sens jolis paysannement
|
Farman FPP-38B, A, A2 : dérivés push-pull des Farman F-238 suite à la suggestion du what-if modeller Frank3k
|
Palm-38A, B, C : avions-arbres, à décollage vertical probablement
|
Palm-38A2, B2, C2 : sans stabilisateur arrière, ces arbres-avions sont presque crédibles...
|
P-38AC6-1A, 1B, 1C : intermédiaires entre P-38 et Alcor C-6-1
|
P-38AC6-1D, 1DZ, 1EZ : autre intermédiaire entre P-38 et Alcor C-6-1, + dérivés doubles
|
SD-38A, B, C Self-Defning : Lightnings à double protection arrière
|
ADH-38A, B, C : Asymétriques à Dérive Hélice
|
THY-38A, B, C : Transition vers un Lightning hydravion
|
GO-38A, B, C Gorgening : Lightnings inspirés de l'affreux Beoing 707 Phalcon, pas du tout "gorgeous" (magnifique)
|
YA-38A, B, C Yakovning : dérivés Lightninguisés du Yakovlev Yak-28
|
Train-38A Multitraining, Train-38B & C Polytraining : avions d'entrainement à 4 ou 8 sièges en tandem
|
RI-38A, B, C Rickenning : Lightnings inspirés d'un projet d'Eddie Rickenbacker envisagé en 1929
|
JP-38A, B, C Jésusning : le Messie futur (et vrai) étant un enfant de véritable mère-poule (JC en anglais : Jesus-Chicken, Jésus-Poulet JP en français), il ne faudra pas que devenir végétariens, il faudra célébrer l'oeuf et non plus la croix.
|
NSA-38S, L, LFF Notsitting : la station assise étant médicalement mauvaise pour les pilotes d'attaque, il est envisagé de les installer debout (Standing), ou couchés tête en avant (Lying) ou couchés les pieds devant (Lying Feet Fist).
|
SSP-38A, B, C Superspanning : Lighntings à envergure accrue, consolidés en quadripoutres ou non.
|
RAC-38A, B, C Racening : Lighntings civils de course à trainée réduite.
|
RAC-38D, E, F Racening-II : versions encore allégées et affinées, sans queue et puis sans symétrie (pour tourner autour de pylones, l'asymétrie est même un avantage)
|
DEL-38B, T, A : Lightnings de formule Delanne à ailes tandem (idée du what-if modeller Wuzak).
|
DEL-38B-3, B-1, A-1 : versions plus proches du Lysander-tandem.
|
DEL-38C, D, E : versions à aile arrière plus petite (idée de Wuzak encore).
|
DEL-38F, G, H : versions à moteur tractif arrière, inspiré d'un projet de Stanislaw Jerzy Rudlicki.
|
C-38B-32, B-33, B-34 : Lightnings cargos légers inspirés du Bériev Be-32.
|
L-3038A, B, C : Lightnings avions de ligne plus ou moins légers.
|
GS-38G, R, A Gunshipning : canonnières aériennes massacreuses, oui, c’est (hélas) aussi ça l’aviation, accessoirement jolie… (et quand la guerre air-sol se fait avec nos impôts réquisitionnés, on se fait massacrer en ville en retour, c’est normal hélas).
|
L.3800, 3801, 3802 : Lightnings à moteurs surélevés (suite à une discussion avec le what-if modeller Weaver).
|
WBGS-38 WaterBaloonning, BIZA-38A, BIZA-38Z : Canonnière-clown expéditrice de bombes à eau, et Ligntning asymétrique bizarre, avec version double.
|
GS-38T-1, T-2, T-3 Tankning : images cauchemardesques d'une maquette que j'aurais montée si on m'avait hélas offert un char d'assaut plastique à construire...
|
P-38DB, DC, DD Dightning : dérivés Lightning d'une création réalisée à partir d'un De Havilland Hornet
|
TPP-38A, B, C : nouvelles extrapolations du Lightning push-pull
|
BS-38, LS-38A, B, C, D : Lightning Big Span ou Little Spans (Grande et Petites envergures)
|
TU-38A, B, C : chaînons manquants jusqu'à la tortue-Lightning à quatre pattes et zéro aile (TU-38D ?) inventée par le what-if modeller Ericr
|
APP-38A, B, C : Advanced Push-Pull Lightnings, ayant pour justificatif technique de... enrichir la famille.
|
| – APP-38D version canard de l'APP-38A, à postes panoramiques – APP-38E : version asymétrique du précédent – TU-38CZ ou MST-38 Multi-Siamese-Twin 38 (suggérée par le what-if modeller steelpillow) certes pas Maladie Sexuellement Transmissible... 
|
TwiP-38A, B, C Twin-Lightnings : versions double de Lightning propulsif.
|
FaP-38A, B, C Fantasy-Lightnings : versions imaginaires diverses.
|
MAD-38A, B, C Magnetic-Lightnings : versions à "folles" poutres MAD (Magnetic Anomaly Detector), dont la première est bien sûr bipoutre.
|
XCA-38, L.3038L, YCA-38 : version canard du P-38, avec dérivé "avion de ligne" et tourisme/gunship.
|
XCB-38, L.3038P, YCB-38 : versions propulsives des précédents.
|
BH-38B, A, Z Blackheart-Lightnings (et Twin-Lightning) : versions caricaturées à partir du mignon profil de blackheartart.
|
BH-38C, D, E : versions inspirées du BH-38A, mais qui auraient un profil un peu différent.
|
XGP-38A, YGP-38, GP-38A : modèles à nacelle arrière haute.
|
MIST-38A, B, C : Lightnings composites façon Mistels.
|
WLTE-38A, B, C : Lightnings sans moteurs tractifs latéraux.
|
RePo-38A, B, C : Lightnings à poste arrière.
|
Para-38A, B, C : Lightnings (terrestres ou marin) à aile parasol.
|
AWG-38A, B, C : Lightnings à aile auxilaire, supérieure ou arrière (slip-wing, auxiliary-wing)
|
| – FAN-38 : Lightning à hélices carénées
– DH-138 : dérivé lightninguisé du tripoutre Dunne-Huntington de 1910 (à la demande du what-if modeller steelpillow) – DH-238 : dérivé bipoutre du DH-138 
|
Les Edgley EA-38A, B, C auraient été des intermédiaires entre Lightning et Optica
|
P-384 et P-384-2 : derivé quadrimoteur du Lightning, et version redevenue bimoteur
|
AE-38A, B, C Aftenginning : Lightnings à moteurs tractifs arrières.
|
RUE-38G, RUE-38A, LDE-38A : Lightnings à moteurs surélevés ou surbaissés (raised up engines, lowered down engines).
|
TS-38G1, G2, M : Lightnings à décollage vertical et posé sur la queue (TailSitter VTOL).
|
PHG-38A, B, C Powered-Hanglidning : Lightnings ultralégers pendulaires (deltaplanes motorisés).
|
HGP-38A, B, C : nouveaux Lightnings hélicoptères, dont un à rotors bipales engrenants.
|
GULL-38A & G, BURNE-38G : Lightnings à aile en mouette ou de formule Burnelli.
|
P-38X-114, X-138A & B : Lightnings ancêtres imaginaires du Lippisch X-114.
|
DH-338, 438, 538 : dérivés du Dunne-Huntington 238, essayant de suivre les mots du what-if modeller steelpillow.
|
SP-38SP-1, -2, -3 Lightning Special : inclassables P-38 plus ou moins asymétriques.
|
VB-38A, B, C : Lightnings à poutres verticales, de gros à petit
|
DH-438B : aile volante à empennages repliés, sortables/étendables en cas d'urgence instable (idée du what-if modeller Flyer).
|
AQ-38S, A, B : Lightnings à poutres latérales non-masquantes.
|
HN-38A, B, C : divers Lightnings à nez habité.
|
Weavereed W-38A, YW-38, XW-38 : Lightnings façon "Catalina monomoteur" imaginés par le what-if modeller Weaver.
|
Weavereed W-38B, YW-38B, XW-38B : Lightnings à agencement vertical (aussi imaginés par Weaver).
|
Weavereed W-38C, YW-38C, XW-38C : Lightnings hydravions à queue en X (aussi imaginés par Weaver).
|
W-38D, YW-38D, XW-38D : même sans flotteurs, la queue en X peut trouver un emploi.
|
Weavereed W-38A², B², C² : versions corrigées après clarification par Weaver.
|
P-38DH : application Lockheed (aile volante bitractrice) inspirée du Dunne-Huntington DH-438B pour la sortie d'empennages.
|
AsymP-38A, B, Z : nouvelle famille de Lightnings, initialement asymétriques.
|
AsymP-38C et D Asymmetric Lightning, AsymP-38E Asymmetric-Twin-Lightning : autres dérivés gentiment délirants, non construits bien sûr.
|
AsymP-38F, G, H : Lightnings un peu moins franchement asymétriques
|
Le site de l’américaine P-38 National Association a mis à jour sa page Cartoon avec de nouvelles silhouettes (Toon-38D, E, F ?).
|
Autres cartoons de la P-38 National Association (Toon-38G, H, J ?).
|
"DAR-38" A, B, C : dérivés de P-38 par les Deviant ARtists FlytoonsFactory, Sudro, 09camaro.
|
"DAR-38" D, E, F : dérivés de P-38 par les Deviant ARtists Star_jumper, Gwdill, Tyrranux.
|
"DAR-38" G, H, J : dérivés de P-38 par les Deviant ARtists Andifferous, Pixel_pencil, 1jazzy1.
|
P-38MC-1, -2, -3 : Lightning inspiré de mots du what-if modeller McColm, et dérivés redevenus bimoteurs, à radar(s).
|
TK-38A, B, C : Lightnings blindés, pas jolis du tout.
|
EB-38A, B, C : Lightnings à poutres dissociées des moyeurs latéraux.
|
EB-38A², B², C² : dérivés des précédents avec "davantage d'empennage".
|
Thunderbird-38 : dérivé Lightning d'un aéronef de dessin animé, à morceaux amovibles.
|
P-38LF-1, -2, -3 : Lightnings-parasols à fuselage bas.
|
PA-38A, B, C : Lightnings agricoles pour épandage aérien.
|
LVV-38A, B, C : dérivés Lightnings d'un projet Levavasseur de 1921
|
LVV-38D, PA-38D et E : dérivés asymétriques imaginés par les what-if modellers wuzak et steelpillow, merci à eux !
|
LVV-38E, F et G : dérivés du LVV-38D à empennage agrandi (amélioration suggérée par wuzak)
|
PA-38F, G, H : versions de Lightnings agricoles à petits moteurs légers (idée du what-if modeller buzzbomb)
|
WBR-38A, B, C : versions bombardiers d'eau du Lightning
|
DB-38A, T, TL : bombardiers d'eau Lightnings à train d'atterrissage Daimler-Benz
|
AIL-38A, J, J2 : nouveaux avions de ligne dérivés des Lightnings (AIrLiner à l'international, AvLi-38 pour la France sans douleur ni mauvaise odeur)
|
AIM-38A, J, J2 : dérivés des AIL-38 à trains non-rentrants.
|
AICA-38A, B, C : bi-ponts dérivés des AIL-38, suggérés par le what-if modeller Chernaya Akula
|
AICA-38D, E, F : versions biplanes du AICA-38B, redemandées par Chernaya Akula.
|
BdB-38 en configuration cargo et sans soute, BdB-38B : dérivés du AICA-38D imaginés par le what-if modeller Brian da Basher.
|
REN-38A, B, C : avions de course à huit mille chevaux et traînée aérodynamique réduite.
|
LFW-38A, B, C : ailes volantes Lockheed de course.
|
F3O-1, -2, -3 Lightnilina : hydravions à 1 coque et 1 flotteur, dérivés du Lightning.
|
F3O-4, -5, -6 Lighlina : autres hydravions dérivés du Lightning.
|
F3O-7, TBO-1, PBO-1 : autres hydravions, imaginés par le what-if modeller RAFF-35.
|
NO-1, -2 : hydravions d'entrainement à professeur au sec.
|
NO-1B, -2B : versions améliorées, pour que l'enseignant surveille mieux les élèves pilotes.
|
| – OO-1 : Lightning hydravion d'observation ; – SG-1 & SG-2 : ancêtres Lightning (imaginaires) du Rutan Skigull (véridique, si ici n'est pas un rêve) 
|
| – P-38T : dérivé Lightninguisé du P-48 Pelican, par le what-if modeller Lauhof52 ; – Dust Tactics Allies P-48 Pelican : avion imaginaire de Fantasy Flight Games ; – P-48A et P-48B Tophican : dérivés du Pelican par moi-même. 
|
OO-1-41, PBO-3 Lightrilina, PBO-2 : autres Lightings hydravions, asymétrique ou non.
|
ShaP-38A, B, C : triple Lightning conçu par Shapeways.com, et dérivés miens davantage compacts.
|
CAC Boomerang II, III, IV, V : dérivés à réaction du P-38, à partir d'une maquette inventive du what-if modeller Flyer.
|
Lighner, Regiolighner, Trancontilighner : avions de ligne Lightning plus ou moins grands, plus ou moins endurants.
|
Lightnistrelle I, II, III : dérivés Lightninguisés du Speed Pipistrelle dessiné par le what-ifer Zero-Sen.
|
McC-38A, B, C : dérivés de la Lightnistrelle II inspirés par une question du what-if modeller McColm.
|
Intercontilighner, PBO-4 M-Wing Hydrolightning : dérivés gentiments déments des Transcontilighner et PBO-1.
|
| – Noviplane II : version moderne délirante du Caproni Noviplano ; – SL-38 Simplightning : version simplifiée du bipoutre Lightning, en bouche-trou... 
|
F4O-1, -2, -3 : Lightnings marins à moteurs robustes.
|
F4O-1P, -2PP, -4 : autres dérivés du F4O-1.
|
| – F5O-1 Navining en vol et au sol replié : chasseur naval. – F5O-2 Biplane-Lightning : chasseur très manoeuvrable inspiré du F5O-1 replié 
|
ScaleORama SoR-38A, B, C, D Skightning : mixes de maquettes P-38 à échelles 1/72 et 1/144.
|
SoR-38D-1, D-2, D-4 : autres mixes d'échelles, avec petit cockpit non central.
|
SoR-38E-1, E-2, E-3 : encore d'autres mixes d'échelle.
|
P-51D-38, P-38J-82, P38J-38 : mélanges d'échelles et familles (Lightnings et Mustangs).
|
P-38K-38, P-38Del, P-38Del-2 : autre mix d'échelles et delta-Lightnings.
|
SoR-38F, G, H : mêlanges de Lightnings aux échelles 1/72 et 1/144.
|
SoR-38J, K, L : versions asymétriques et mistel des mixes d'échelle.
|
| – Tourist Lightning : version de loisirs sans gros nez canon ni gros moteurs – P-38-83 : version scale-o-rama de Ligntning avec modèles 1/72 et 1/144 – Floatning Mk.1 : hydravion envisagé par la Royal Navy, dans mes rêves (j'en ai vraiment rêvé : c'est véridique !) 
|
SoR-38M-1, M-2, M-3 : encore d'autres version à mix d'échelle.
|
SoR-38N-1, N-2, N-3 : versions mixtes avec petit modèle devant.
|
SoR-38O, P, Q : encore des délires sur le thème des échelles mélangées.
|
| – SoR-38R : planeur avec aile au 1/72, deux nacelles 1/72, une (demi) dérive au 1/48, zéro moteur/hélice. – Lightriplane : tricoque à trois ailes tandem et deux poutres de queue. – Lightnoviplane : triple Lightriplane, noviplan comme le vieil hydravion Caproni Noviplano, hyper-longue-endurance (capacité à boucler le tour du monde sans escale...). 
|
SoR-38S-1, S-2, S-3 : Lightnings construit à échelle 1 à partir de modèles à échelle mixte (72e/48e, 144e/72e, 144e/48e).
|
XF6O1, YF6O1, F6O1 : hydravions Lightnings à plans avant en V inversé.
|
SMO1, 2, 3 : SM signifie ici Sub Marine, bien sûr pas Sylvie Métailié.
|
QP-38, QP-38P, F7O1 : Lightnings à poutres très proches
|
F8O1, 2, 3 : versions de Sea-Lightnings biplaces (Twin-Lightnings) à flotteurs sous nacelles.
|
| – SoR-38T : drone à partir de P-38 aux échelles 1/72 et 1/144. – SoR-38U-1 et U-2 : mixes de P-38 aux échelles 1/48 et 1/72. 
|
| – SoR-38V : Lightning au 1/72 avec réacteurs d'appoint venant de poutres 1/144 tronquées. – SoR-38W : maquette 1/72 à roues 1/32, formant un hybride avion/voiture de course. – XF4O5 : croquis hypothétique à partir d'une ébauche de maquette par le what-if modeler DogfighterZen. 
|
XF4O6, 7, 8 : dérivés du XF4O5.
|
CAN-38A, B, C : Lightnings canards à moustaches.
|
CAN-38D, E, F : dérivés bipoutres, non plu' tripoutres.
|
SoR-38T-2, SoR-38X-1, SoR-38X-2 : dérivés-délire construits à partir de maquettes 1/32-1/72-1/144, ou bien 1 fois 1/72 et 2 fois 1/144 (de 2 façons différentes).
|
CAN-38G, H, J : dérivés canards inspirés par un cousin véridique signalé par le what-if modeller Mossie.
|
GRI-38A, B, C : intermédiaires entre le Gribovskii G-17 et le P-38.
|
| – SoR-38Y-1 : Sesquiplan à base de mélange d'échelle 1/48 et 1/72. – SoR-38Y-2 : Lightning normal à moteurs-poutres auxiliaires à échelle moitié. – SoR-38Y-3 : version du précédent mieux centrée. 
|
CAN-38K, L, M : dérivés du CAN-38G, mais abandonnant la configuration canard.
|
CAN-38N, P, Q : dérivés du CAN-38G, plus ou moins tripoutres.
|
| – F4O9 : sesquiplan à faible envergure pour porte-vions. – Burnelning : hydravion à flotteurs dessiné avec l'aide de la compagnie Burnelli. – SoR-38Z : maquette 1/72 à dérives 1/48 et canopées 1/144. 
|
| – F9O1 Lightcat : postulant au remplacement du Hellcat. – F9O2 Blomning : chasseur embarqué inspiré du Bv-141. – F9O2Z Twin-Blomning : version double du précédent. 
|
| – SoR-38X-3 : sesquiplan à base de maquettes 1/72 et 1/144. – CH-38A et B : Lightnings sesquiplans à grande corde d'aile. 
|
ADD-38A, B, C : transformation de Lightnings 1/72 avec poutres 1/144 tronquées en jets additionnels.
|
Push-38A, B, C, D : Lightnings bi-pousseurs (twin-pushers), en terminant par une version mixte à échelle partiellement demie.
|
| – SoR-38Z-1 Crazning : tripoutre sur base 1/144 + 1/72 – SoR-38Z-2 Madning : dérivé pire sur base 1/144 + 1/24. – SoR-38Z-3 Lunatning : version "folle" sur base 1/144 + 1/12. 
|
Zeppening : Lightnings dirigeable à partir de un modèle 1/24 et deux modèles 1/144.
|
AAA-38A, B, C : Lightnings 3-surfaces (semi-canards), les deux derniers avec échelles mixtes.
|
PPL-38A, B, C, D : Lightnings push-pull à échelle mixte 48e/72e ou sans stabilisateur.
|
Flying Ning, Flapning, Spirning : Lightnings à flotteurs dérivés de 3 maquettes hydravions inventées par le what-if modeller ericr.
|
2E-38A, 3E-38A, 2E-38B : Lightnings asymétriques multi-empennages (à changement d'échelle pour les deux premiers : 48e, 72e, voire 144e).
|
Mys-38A, B, C, D : Lightnings mystères fantaisie explorant les limites de la définition "bipoutre".
|
Dou-38A, B, C : Famille de dérivés issue d'un Double-Lightning.
|
Dou-38D, E, F : suite de la douce famille Dou-38.
|
TB-38D, E, F : tripoutres et quadripoutre complétant la panoplie des Lightnings.
|
Bis-38A, B, C, D, E : branche déviante de Lightnings étranges.
|
Bis-38A2, GN-38A Glazednozning, GN-38B : dérivés à train pantalonné.
|
PuPush-38A, B, C : Lightnings Push-Push, plus ou moins larges (plus ou moins grande autonomie).
|
Lockheeliner, Lockeeargo, Locheekarrier : mélanges de Lightnings à échelles 1/72 et 1/144, sérieux presque.
|
AJP-38A, B, C : Lightning Asymmetric Jet en trois versions.
|
| Mélanges de maquettes Lightning 1/48 et 1/144 : – CB-38 Tiny Engined : pentapoutre à gros cockpit et micro-moteurs. – CC-38C Cree-Cree : dérivé façon Colomban Cri-Cri imaginé par le what-if modeller Artoor_K. – CD-38B Big Tail : version à petits cockpits. 
|
LN.38A Loirning, LN.38B Nieuning, LN.38C Portning : Lightnings hydravions inspirés du Loire-Nieuport LN.10 (merci à ericr).
|
TDM-38A, B, C Lockheed Trident : avions peut-être mieux nommés que l'avion-fusée de la SNCASO.
|
TPT-38A Transport, BW-38A Big Wing, TPL-38A Triplane : Lightnings transportables par bateau à haute densité (merci à wuzak).
|
NoBiP-38A, NoBiP-38B, BiP-38R : configurations de Lightning aux limites de la définition "bipoutre" du what-if modeller steelpillow.
|
NE-38A, B, C : Lightning et Twin-Lightning à nez moteur(s).
|
NE-38D, E, F : autres dérivés, de tripoutre à bipoutre asymétrique.
|
UPP-38A, B, C : Lightnings quadriplaces sous-motorisés (underpowered P-38), à base de moteur 1/144 sur base 1/144 ou 1/72 ou 1/24.
|
AsP-38A, B, J : Lightnings asymétriques bimoteurs non-push-pull dessinés pour mon nouveau livre "Fantômes biscornus".
|
P-38BV, BVS, BVW, BVTL : Lightnings asymétriques monomoteurs dessinés aussi pour le même livre.
|
P-38C3A, C4, C3B : Lightnings asymétriques trimoteurs ou quadrimoteur, toujours pour le même livre.
|
SJ-38A, B, C : Lightnings monoréacteurs ancêtres des F-80, F-86, F-16.
|
TK-38D, E, F : Lightnings blindés supplémentaires (pas jolis...).
|
| – TK-38G, H : Lightnings blindés presque plu' avions hélas. – DL-38BT BigTailNing : modèle mixte 1/72 et 1/144 donnant une aile tandem façon Delanne. 
|
| – XP-76 Double-Lightning : maquette inventée par le what-if modeller Scotaidh. – YP-76 & P-76A : dérivés du XP-76 pour faire un triplet. 
|
| – BAN-38 Bananing : Lightning inspiré du P-61 Banane Volante génialement inventé par le what-if modeller Ericr. – BAN-38A & 38B : dérivés du BAN-38 plus réaliste ou moins réaliste encore... 
|
| – Polysorbate-380 Tween-Boom : intercepteur émulsifiant, transformant l'ennemi touché en "liquide et bulles". – CI-38A, B : Lightnings à voilure partiellement circulaire. 
|
Polysorbate-381, CI-38C et D : versions révisées des projets précédents.
|
BWI-38 BigWingning, POI-38A et B : Lightnings à grosse aile ou nez pointu.
|
NUK-38A Nuclening, 38B Girafning, 38C Banananing : Lightnings à réacteurs nucléaires et tentatives de mettre le pilote à distance de sécurité.
|
P-76B, C, D : dérivés du XP-76 de Scotaidh.
|
P-76FETT-1, -2, -3 : versions triple-queues du quadrimoteur de Scotaidh.
|
P-76E, F, G : encore des dérivés du modèle de Scotaidh.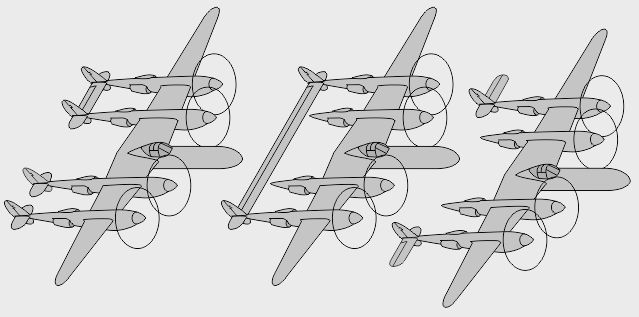
|
XP-76Z Twin-Double-Lightning, P-76Z Double-Lightning-Zwilling : versions redoublées du modèle de Scotaidh.
|
QP-76, YP-76Z : plus petit et plus gros dérivés du modèle de Scotaidh.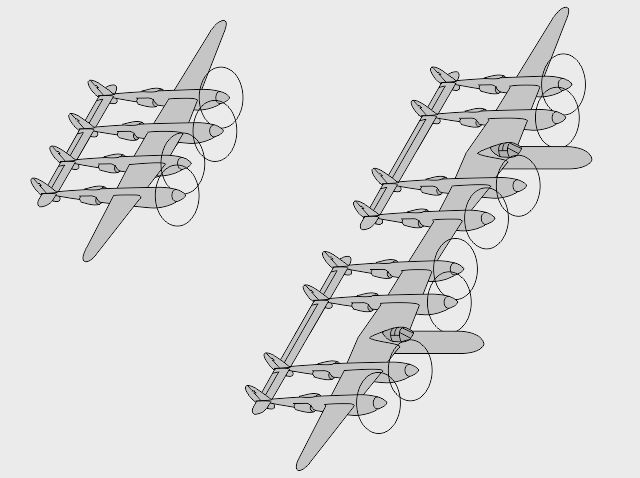
|
P-74Z-1, -2, -3 : dérivés/ancêtres des P-76Z en plus léger.
|
ASY-38A, B, C : Lightnings asymétriques dans une nouvelle direction.
|
TVB-38A, B, C Twin-Very-Boom : non, les Lightnings ne sont pas bifuselages (twin-fuselage) mais bipoutres (twin-boom), ouf, Tout Va Bien...
|
| – TVB-38D : version asymétrique mixte de A et B, suggérée par le what-if modeller Wuzak. – TVB-38E, F : forme bipoutrelle d'une autre façon, "standard" ou asymétrique. 
|
TWA-38A, B, C : Lightnings sans train d'aterrissage nasal (TW pour tail-wheels : roulettes de queue)
|
PAP-38, -38V, -38N : P-38 rejoignant la configuration du Nemeth Parasol
|
| – PAP-38J-1 : version jet parasol suggérée par le what-if modeller AXU. – PAP-38J-2, J-3 : Lightning jets deltas parasol et parasol-inverse... 
|
P-76L, N : versions à train fixe et marine du modèle de Scotaidh.
|
Mother Nature CHE-38A, B, P Lightolecula : molécules chimiques ancêtres préhistoriques (38 millions d'années d'âge, estimé) du Lightning – formule C1H5O2P2, avec parfois doubles et triples liaisons à électrons délocalisés.
|
P-38GB-1, -2, -3 : Lightnings inspirés du Granville Brothers GeeBee R, mais davantage délirants.
|
NPP-38A, B, C : NPP ne veut pas dire ici "Nombre le Plus Probable" mais No Pusher Propeller, pas d'hélice propulsive malgré un moteur central, grâce à engrenages et arbres moteurs.
|
Burnelli BuP-38A, B, C : Lightnings à aile habitée.
|
Mod-38A, B, C Modmod-elning : projets miens de maquette (model) Lightning "modifiée".
|
IcA-38, IpA-38, AbA-38 : modèles à surface alaire réduite pour gagner en vitesse, mais modérément véridiques d'après leurs codes (InCredible Aircraft, ImPossible Aircraft, ABsurd Aircraft).
|
WUZ-38 : dérivé du IpA-38 imaginé par le what-if modeller Wuzak, ici en vol horizontal puis transition pour atterrissage vertical.
|
WUZ-38 suite : autres configuration incroyables du précédent, notamment avec pilote tête en bas ou ailes pivotées.
|
| – TCO-38 : version VTOL suggérée par le what-if modeller The Chronic One. – WUZ-38 avec nouvel angle suggéré par le what-if modeller Ericr. – VZ-38 : autre version VTOL du P-38, sans poutrelles. 
|
AbeA-38A, B, C : ces avions (Aberrant Aircraft 38) sont peut-être parmi les premiers par ordre alphabétique, mais pas en tête des ventes...
|
CraPP-38A, B : ces Crazy Planes P-38 ont pour technologique raison d'être de faire n'importe quoi (en anglais, "to crap" veut dire "débiter des conneries")...
|
DTA-38A, W, D² : Lightnings à empennage doublé ("double simple", "double-V", "double-delta").
|
AS-38A, PR-38A, TBO-38 : dérivés de Lightning et Airspeed AS.31 ou Pond-Racer, et version bipoutre asymétrique.
|
P-38K-46A, -46B, -46C : Lightning s'inspirant du Mitsubishi Ki-46 III.
|
AxuP-38A, B, C : Lightning imaginaires dessinés par le what-if modeller AXU à partir de mes dessins, en mieux !
|
| Lightnings étranges, bizarres : – Fantasy Aircraft FaAP-38 (Apollo XXXVIII, LEM-3.8) – Funny Aircraft FuAP-38, triplace trinez pas sérieux – Unreal Aircraft UnAP-38 (Multiplane-38, MuP-38) 
|
ReT-38A, B, C : Lightning à moteurs tractifs arrière (Rear Tractive), à nez simple ou double.
|
CraPP-38C, D, E : dérivés des Crazy Planes P-38, les deux premiers étant demandés par le what-if modeller Wuzak, et le dernier : par les militaires pour d'obscures raisons (le "lancer de fleurs" ou quelque chose).
|
CraPP-38C-2, D-2, E-2 : versions selon précisions de Wuzak, après malentendus initiaux (avec ajout aussi de son détail "voiture volante" sur le D-2).
|
FWG-38A, B, C, D : Lightnings à ailes battantes et moteurs musculaires, dessinés par un ingénieur zoologiste, inspirés de chauve-souris, ptérodactyle, écureuil volant, papillon.
|
FWG-38E1, E2, E3 : Lightnings à ailes battantes inspirés d'hirondelle bifide.
|
PTL-38A, B, C : Lightnings à poutrelles (bipoutrelles pour les deux premiers, twin-beam plutôt que bipoutres, twin-boom).
|
AC-38A, B, C : Lightnings à cabine arrière (aft-cockpit), standard ou à aile tandem ou canard.
|
| – SL-38BL Lockheedus lightningii : hybride avion-animal inspiré de la limace siamoise volante Bolo du dessin animé Slugterra (adoré par mon fils de 7 ans). – XP-38TT-2 et TT-1 : versions quadipoutres à arrière bipoutre inspirées d'un modèle volant du what-if modeller Tonton42. 
|
VF-38A, B, C Vtolning : Lightnings à décollage vertical, Vertical Fighters pas aViation Fighting squadron (en Français : ADV-38 Adavning, Avions à Décollage Vertical pas Administration Des Ventes).
|
FS-38A, B Sausning : Lightnings soucoupes volantes.
|
FD-38A, B, C : Lightnings à aile-canal arrière ressemblant à un brevet Fredericks de 1969/72.
|
FD-38D, E, F "Horse Before the Cart" : versions channel-wing de Lightnings suggérées par le what-if modeller The Chronic One, avec "cheval devant le carosse".
|
STO-38A, B, J : versions STOL (à décollage court) du Lightning.
|
STO-38C, V, S : versions rejoignant un brevet bifide d'hydravion à empennage en V éclaté.
|
XFou-38, YFou-38 : F-38 veut peut-être dire 38e Fighter (chasseur), mais Fou-38 veut dire 38e Fourchette volante (pour les analystes aéronautiques sains d'esprit).
|
Fou-38A, B : versions construites en série, techniquement optimisées pour que Le Seigneur ait de quoi manger des patates géantes.
|
TiP-38A, B, C, D Tiny Lightning : projets de petites maquettes sur base P-38 sur étagère trop encombrée.
|
Finger-38A, T, HD : Lightnings à doigts multiples, jusqu'à 5 avec deux genres de pouces.
|
DDR-38A, B, C Dromedarning : Lightnings à bosse électronique façon dromadaire, ou bi-bosse façon chameau, avec éventuellement 4 pattes et dents...
|
He-1038A, B, C, D : Lightnings asymétriques inspirés de ma maquette Heinkel He-1041.
|
He-2038A, B, C : versions doubles des He-1038.
|
BOd-38A, B, C : Lightnings inspirés du Borel-Odier 1913, dit de dessin "audacieux".
|
PL.380A, B, C, D : à partir de poutres basses toujours, poutres-flotteurs cette fois, ces autres Lightnings rappellent l'hydravion Pierre Levasseur PL.200.
|
CG-38A, B, C : essais de centrage, suite à une invetion maquettiste de mon fils de 7 ans.
|
| – DRE-38 Dreamy Lightning : version rêveuse traversant un nuage orageux (Lightning veut dire Éclair). – ITA-38 Spatwing : version à jambes pantalonnées portant ailes (inspiré d'un dessin italien de 1936). – DH-38 Lightning Rapide : version inspirée du De Havilland Dragon Rapide. 
|
| – API-38 : vue en perspective à partir d'un mignon profil mis par Air-Pictures sur FaceBook. – FU-38 "1943" : maquette de Lightning caricaturé par Fujimi. – P-38Toon : modèle plus simple à verrière grandie. 
|
EH-38A, B, C : Lightnings quadricoptères inspirés du Ehang-184.
|
En l'honneur de ma grande petite nièce Clémentine, à coiffure joliment asymétrique, voisi les avions dissymétriques CLE-38, 38B, 38C Clementing.
|
QZ-38A, B, C : éléments de questionnement, pour construire une maquette inventive de P-38, sur base reçue pour Noël 2016.
|
MEL-38A, B, C : mélanges de maquettes P-38 Lightning et P-82 Twin-Mustang à la même échelle.
|
MEL-38D, E, F : autres mélanges de P-38 Lightning et P-82 Twin-Mustang.
|
MEL-38D-2, G, E-2, F-2 : encore d'autres mélanges de P-38 Lightning et P-82 Twin-Mustang.
|
P-38ANNW-1, 2, 3 (Asymmetric Noses & Nose-Wheel) : Lightnings bi-nez (sans canons), avec long support asymétrique de roulette de nez.
|
XP-38LR-1, 2, 3 : Lightnings à long rayon d'action (long range), remplaçant les trains principaux habituels par des réservoirs.
|
| – MCC-38D, E : dérivés du XP-38LR-1 d'après une suggestion du what-if modeller McColm, à lecture double. – MCC-38F : dérivé du MCC-38E à trains davantage habituels 
|
MCC-38G, H, J : autres dérivés après avoir vu le modèle "Wraith" source ayant inspiré les commentaires de McColm.
|
P-38SJ Stump Jumper, SJ-2, SJ-3 : Lightnings à train d'atterrissage inspirés du XB-26H Middle River Stump Jumper (merci au what-if modeller Wuzak).
|
P-38SJ-3J, -3P, -3S : versions du SJ-3 rendu moins incroyable, en restaurant le mode bimoteur, ou bipiston, ou symétrique non push-pull.
|
DouP-38A, B, C : dérivés du P-38SP-3S mais à train classique (codé comme double-pusher), avec éventuellement des hélices rapprochées engrenantes (probabilité d'accident inférieure à 95% : "validé" à risque alfa inférieur à 5% ! vive les validations par non-significativité, et meurent les pilotes...).
|
APL-38A, B, C, D : aucun rapport avec l'Aide Personnalisée au Logement, il s'agit de Abnormal Prone Lightnings à traînée aérodynamique réduiite (pilote couché et pas de dérives).
|
APL-38E Twin-Abnormal, APL-38F Abnormal Boom, APL-38G Twin-Abnormal-Boom : dérivés de l'APL-38D ramenant à la famille bipoutre.
|
XCr-38, YCr-38, Cr-38A : dérivés Lightnings d'un cousin de Spitfire inventé par Gibbage dans l'esprit Crimson Skies.
|
XKE-38, YKE-38, KE-38A : à partir d'un hydravion Lightning délirant à moi, modifications pour suivre les conseils du rêveur Kerick.
|
HCS-38A, B, C : hydravions Lightnings (normal, double, moitié) à aile semi-circulaire.
|
Ar-238A, B, C : Lightning modifié pas à pas pour ressembler à un Arado Ar-196.
|
WW-38A, B, C : prototypes conçus avec ma machine à remonter le temps pour inspirer le Fouga Gémeaux.
|
P-38F-91, Z-91, A-91 : dérivés Lightnings du Fairchild 91 présenté par le what-if modeller Axor.
|
ATK-38A, B, C : ancêtres Lightnings du biplan agricole Airtruk (ATK ne veut pas ici dire ATtacK !).
|
CTL-38A, B, C Catalinning : mixes de P-38 tronqués et base hydravion PBY Catalina.
|
ChA-38A, B, C Lightalina : autres mixes de P-38 et PBY Catalina, suggérés par le what-if modeller Chernaya Akula.
|
ChA-38D, E, F Twin-Lightalina : dérivés doubles du ChA-38A.
|
ChA-38G, H, I : autres dérivés du CH-38A, après clarification de Chernaya Akula expliquant son rêve.
|
EKP-38A, B : dérivés ékranoplanes du Lightning.
|
P-38ESM, P-38WI, P-38AP : Lightnings "Et si jamais", "What-if", "Almost Possible".
|
PEG-38A, B, C : premiers projets de construire un P-38 Egg Plane.
|
PEG-38D, E, F : autres projets de P-38 Egg Plane.
|
PEG-38G, H, I : encore d'autres projets de P-38 Egg Plane.
|
PEG-38J, K, L : versions jet des précédents.
|
PEG-38M, N, P : versions hélicoptères et à poutres scindées des précédents.
|
PEG-38Q, R : versions plus logiques du PEG-38P, donc moins amusantes...
|
Poison-38A (en croisière et en tir/injection), Poison-38B : avions-seryngues inspirée de l'invention géniale du what-if modeller Ericr.
|
SWR-38A, B, C : Lightning se transformant en Naboo Fighter (de Star Wars) - merci au what-if modeller Kerick pour cette suggestion.
|
SWR-38D, PEG-38S et T : autres dérivés des SWR-38 et PEG-38.
|
P-38K-46A, B, C : fruits des amours pacifistes entre un Mr Lightning et une Mlle Dinah.
|
PEG-38Z, Y, X : doubles Lightnings-oeufs.
|
PEG-38U, V, W : achèvement alphabétique de la famille des Lightnings-oeufs.
|
L-3800, 3801, 3802 : Lockheed Lightnings triréacteurs prouvant que le Lockheed TriStar ultérieur n'était pas une copie du Douglas DC-10.
|
L-3803, VFW-338, VFW-438 : autres jet-Lightnings, grands ou normaux.
|
L-3811, 3812, 3813 : à partir de l'idée exprimée par le what-if modeller Apophenia pour se rapprocher du L-1011 TriStar, ces 3 modèles finissent sur une version à cabines séparées, pour que les passagers riches ne soient pas "incommodés" par l'odeur des pauvres....
|
TJT-38-4, 38-8, 38-11 : tâtonnements avant de savoir combien de turbojets il faudrait par avion.
|
TJT-38-1A, 1B, 1C : jet-Lightnings monomoteurs divers.
|
RS-38, 38A, 38B : entrée Tophe dans le thème Beyond The Sprues "Soviet Red Star" (étoile rouge soviétique).
|
RS-38Z, 38BZ, Z1 : versions doubles des Red Star 38.
|
SM-38P-1, -2, -3, Serp i Molot (Faucille et Marteau) : en ce 1er Avril, avions massacreurs à code faisant tristement penser à Sylvie Métailié.
|
Para-38A, B, C : versions à aile parasol du Lightning étoile rouge.
|
Para-38D, E, F : versions de parade aérienne du Lightning étoile rouge (avec difficulté pour gérer l'atterrissage).
|
RS-38C, D, E : versions simples à double étoile rouge.
|
| – RS-38F : Lightning d'épendage agricole collectif, ou – hum – activité militaire liée (contre le Mal aussi). – RS-38G : Lightning en commun à décisions de pilotage collectives. – RS-38H : version trostskiste sans leader devant mais avec table ovale de discussion, à chaises défilantes pour position avant à tour de rôle. 
|
SRS-38C, B, A Sesquiing : Lightnings sesquiplans à étoile rouge.
|
RS-38J, K, L : autres Lightnings à étoile rouge.
|
RS-38M (croisière et attaque), RS-38N : intercepteurs armés d'étoile(s) rouge(s).
|
RS-3R-1, -2, -3 : Lightnings étoiles rouges à réacteurs.
|
YY-38A, B, C YinYangNing : avions bouddhistes, à propulsion nirvanesque "éveillée" commé etape ultime.
|
Wuzakheed YY-38D, E, F : versions de YY-38 dessinées à la demande du what-if modeller Wuzak.
|
KT-38A, B, C : chainons manquants entre le P-38 et le XF5U crèpe volante, à laquelle le what-if modeller PR19_Kit trouvait que ressemblaient les YY-38.
|
XXP-38A, B, C, D : naissance du P-38 à partir d'un projet sans queue.
|
PSL-38 Parasol Lightning L, S, Z : Lightnings à aile parasol en versions terrestre, marine, siamoise bicoque.
|
IEEP-38A, B, C : Lightnings dits "Internal Engines External Propellers" (moteurs internes hélices externes).
|
| – GOU-38A : Goudant Lightning biplan/sesquiplan, à ailes externes basses rétractables pour réduire la trainée aérodynamique. – GOU-38B : sesquiplan dérivé, de formule pré-Burnelli. – GOU-38C : version davantage délightninguisée (délaïtninn-guisée en Français académique). 
|
PTL-38A, B, APTL-38A : Lightnings à poutrelles, ou version asymétrique mono-poutrelle.
|
APTL-38B, C, D : versions asymétriques de Lightning encore monopoutrelles.
|
L-381, 382, 383 : Lightnings civils sans besoin de survitesse ni nez libre.
|
L-3874, 3874A, 3874B : dérivés Lockheed du Boeing 4574 (issu du vrai projet 574) de mon invention, sur une suggestion du what-if modeller wuzak.
|
L-3874C, D, E : même approche à partir du pseudo-Boeing 5574 – merci wuzak encore.
|
PCar-38A, B, C : versions cargos du P-38 Lightning, de plus en plus grandes (pour autonomie puis charge).
|
Precar-38, Trucar-38 en vol et sur route : transformation du Lightning en voiture volante.
|
PAL-38A, G, H : mélange de Lightning et d'hélicoptère Alouette inventé par le what-if modeller Ericr, et transformation en autogyre et puis hélicoptère (comme 80% Alouette au lieu de 20%).
|
PAL-38H-2, -3, -4, -5 : versions de Lightning-Alouette hélicoptère sans problème anti-couple.
|
PAL-38H-6, -7, -8 : versions plus ou moins asymétriques du Lightning-Alouette hélicoptère.
|
TriPo-38A, QuadriPo-38, TriPo-38B : versions à poutres excedentaires, au-delà du besoin (si besoin il y avait vraiment).
|
| – BiPo-38 : version monomoteur du Lightning asymétrique TriPo-38B. – P-38F-35 Lightning-2 : ancêtre chaînon manquant entre les Lockheed P-38 Lightning et F-35 Lightning II. – P-38FZ-70 Twin-Lightning-2 : version doublée du précédent, bimoteur comme un P-38 normal. 
|
QuadriPo-38Z, TriPo-38C, TriPo-38D : compléments aux Lightnings à minipoutre(s).
|
P-38F-189A, 189B, 189C : hybrides de P-38 et Fw-189 suggérés par le what-if modeller Wuzak (Fw-189 à poutres de P-38, P-38 à nacelle de Fw-189, P-38 à nacelle hybride).
|
P-38F-189A2, 189B2, 189C2 : comme les précédents sur base de Fw-189C.
|
Pet-38-1, -2, -3 Eclairs du Pharaon : dessins de machines volantes égyptiennes antiques (datés environ 1937 avant Jésus-Christ), ayant inspiré le dessin du P-38 Eclair d'Amérique (en 1937 après Jésus-Christ).
|
P-38EZ-3, -2, -1 : dérivés Lockheed du double Fw-189E de mon invention.
|
TTL-38A, B Tandem Twin Lightning : avions doubles l'un devant l'autre.
|
| – SBTP-38 Single-Boom Twin-Pod Reverse-Lightning : contraire du P-38 habituel, double autrement. – TBTP-38Z Twin-Boom Twin-Pod Zwilling-Lightning : version jumelée du précédent. – SBSP-38A Single-Boom Single-Pod Asymmetric-Lightning : version simplifiée asymétrique du SBTP-38. 
|
TBTP-38A, TBTriP-38Z, FBTP-38Z : versions jumelées complémentaires des précédents.
|
RN-38A, B, C Super-Lightning : prototypes de course pour la compétition de Reno.
|
STP-38A, B, C : ancêtres imaginaires du StratoLaunch.
|
| – RAS-38A : voiture de course fabriquée avec des pièces d'avion Lightning – les roues arrière décollent à haute vitesse pour diminuer le frottement. – RAS-38B : version bimoteur du précédent. – XP-38C : version à nacelle affinée et axes moteurs abaissés, d'après un profil de Apophenia. 
|
WT-38, 38A, 38B : maquette de soufflerie du P-38 et dérivés moins changés que les "vrais" Lightnings.
|
GT-38A, B, C : Lightnings de course suggérés par GTX_Admin (du site Beyond the Sprues), à partir d'un profil de Victor Archer ou d'un pilote couché.
|
GB-38R-1, -2, -3 GeeBeeNing racers : Lightnings de course à moteurs en étoile surpuissants.
|
GB-38G-1, -2, -3 : versions de GeeBeeNings davantage proches du GeeBee d'origine.
|
RN-38D, E : Lightnings de course hexamoteur et octomoteur.
|
RN-38Z, Z-2 : Lightnings de course à 16 ou 20 moteurs, transoniques !
|
Sch-38A, B, C : hydravions de course pour la coupe Schneider, monoplaces à 7 ou 8 moteurs.
|
Sch-38JA, JB, JC : versions jets des hydravions Lightnings de course pour la coupe Schneider.
|
Sch-38JD, JE, JF : versions améliorées (ou à turbofans double flux) des hydravions Lightnings à réacteurs.
|
Sch-38Z, Z-2 : hydravions doubles bicoques.
|
Sch-38D, E : hydravions Lightnings sans mégalomanie.
|
Sch-38F : triplan au contraire dément, avec 60 moteurs pour un seul occupant à bord.
|
EGP-38A, B, C : nouveaux Lightnings-oeufs imaginaires.
|
EGP-38D, Z, Z-2 : autres Lightnings-oeufs imaginaires.
|
| – XTF-38 Fanning : Lightning à turbofans modernes transsonique. – XX-38 Rocketning : version de Lightning supersonique à moteur fusée. – XY-38 Twin-Rocketning : version de Lightning bifusée hypersonique. 
|
IM-38C, B, A : intermédiaires entre l'IMAM Ro.57 bipoutre de mon invention et le P-38.
|
IM-38D, E, F : dérivés du IM-38B
|
F-38/3e, 3e1, 3e2 : Lightnings trimoteurs en vue de course aérienne entre pylones.
|
SF-38F Suomi Lightning : P-38 finlandais en camouflages d'été, d'hiver et de Noël.
|
JJ-38A, B, C : dérivés Lightnings de maquettes carton créées par mon fils Jacky-Jemsey, âgé de 8 ans.
|
| – MI-38W : Lightning inspiré du tri-pod MiG-0W que j'ai inventé, suite au conseil du what-if modeller The Chronic One pour transformer mon MiG-0M bi-pod. – MI-38X : version tridérive tripoutre suggérée par le what-if modeller Wuzak. – MI-38Y : interprétation tridérive bipoutre à empennage consolidé. 
|
MI-38Y-2, -3, -4 : versions à moteurs plus nombreux, demandées par le what-if modeller Tonton42.
|
MI-38Z, Z-2 : versions doubles des MI-38.
|
Super-Cargo-Lightning, Super-Ramjet-Lightning : hybrides avec structure P-38 collée sur un gros bidule central.
|
TLI-38A, B, C : doubles Lightnings inspirés par le P-81A Twin-Lightning du what-if modeller B29R.
|
TLI-38D, E, F : autres doubles Lightnings inspirés par B29R.
|
TLI-38G, H, J : nouveaux Lightnings tripoutres, mais monoplaces.
|
| TLI-38D, E, F : autres doubles Lightnings inspirés par B29R.
|
| – XT-38 Lightraining : délire à propos de la mention historique d'un projet avorté de T-38 Lightning biplace école. – YT-38 : Lightning d'entraînement côte à côte au lieu de tandem. – ZT-38 : version moderne à tandem décalé, inspirée de l'Alfajet. 
|
SCI-38A, B, C : Lightnings à moteurs mystérieux, top secret en 1946 (dessinés pour un thème de forum what-if sur science-fiction et rétro-futur).
|
SCI-38D, E : Autres Lightning à moteurs incroyables, à moitié ou en totalité.
|
XSCI-38F, SCI-38F : VTOL Lightnings à moteurs mystérieux, révolutionnaires (en version prototype et série).
|
XSCI-38G, YSCI-38G, SCI-38G : Lightnings mystérieux encore, top secret !
|
XSCI-38H, YSCI-38H, SCI-38H : Lightnings à moteurs bizarres mais en tout cas dangereux pour le pilote, visiblement.
|
CaR-38A, B, C : Lightnings canards de course.
|
NVBS-38A, B, C (No Visibility but Speed) : Lightnings de course presque aveugles.
|
AWa-38A, Z, M (Angular Waves Lightning, regular/Zwilling/Mistel) : Lightnings mystères à propulsion improbable.
|
AeP-38X, X2, A (Aerodynamic Push) : maquettes de test puis test motorisé, avant le Vrai Truc incroyable génial, mais imaginaire...
|
Mgn-38A, B, C : mystérieux Lightnings sans hélice ni flamme, Mgn peut vouloir dire Magnetic ou Magnesium mais ça n'explique pas bien...
|
PP-38W-1, -2, -3 : Lightnings à pilote couché, vainqueurs des courses de vitesse (sans réacteur).
|
R2-38A, B, C : Lightnings de course à propulsion mixte (Reno-2 ?), jusqu'à l'arrêt de la formule, trop jet.
|
XDSO-38, DSO-38A, B : Lightnings futuristes propulsés par doubles solénoïdes faisant travailler puissamment le champ électrique terrestre.
|
ZOO-38G, F, R : Lightnings sauteurs-planeurs à propulsion mystérieuse mais carburant Vitamines.
|
DiP-38A (ou Deep-38A), B, C Diamond Lightning : classieux avions diamants à technologie mystérieuse (extraterrestre ?), conçus après le tout premier incident Roswell, 1944, resté secret.
|
Pla-38A, B, C Plasma Lightning : avions à moteurs électriques sans hélice, activant les molécules d'air ionisées poir sustentation et propulsion.
|
ChP-38 en vol et au décollage : intercepteur prévu pour la défense ponctuelle des vignobles de Champagne.
|
Not-38 au décollage : intercepteur prévu pour la défense ponctuelle de la forêt Nottingham (de Robin des Bois).
|
SupElec-38A, B, C : Lightnings Supersoniques à moteurs Elctroniques (?), peut-être inventés par la promition 1938 de l'école SupElec.
|
RiP-38A, B Ring Lightnings : étranges avions à moteur(s) annulaire(s) de principe inconnu (c'est peu étonnant pour des avions qui n'existent pas).
|
UNK-38-1, -2, -3 Unknown Lightnings : avions apparemment rapides dont le moyen de propulsion reste indéterminé, peut-être lié aux dispositifs étranges à l'avant (Dieu seul le sait, ou bien le Diable...).
|
MoE-38A, B, C More-Engines-on-Lightning(s) : avions de course à moteurs additionnels sur montants ; faible autonomie kilométrique.
|
RD-38A, B, C Reduced Drag Lightnings : versions à trainée aérodynamique réduite.
|
PoD-38A, B, C Power Drill Lightnings : ces perceuses aériennes semblent dessinées pour percer le continuum espace-temps, afin de dépasser la vitesse de la lumière (à confirmer...).
|
FT-38A, B Flamethrower Lightnings : avions à propulsion lance-flammes aberrantes. Ou géniale ?.
|
LaLi-38A Laser Lightning : avion dérivé du principe de la voile solaire mais à source hyperlaser embarquée (la distance du récepteur est liée à la longueur d'onde des photons rouges).
|
XT-38A, B, C Miller Wheel Lightnings : avions à roues Meunier sans carburant (mouvement perpétuel), bipoutres et éventuellement asymétrique pour une grande raison technique : mes préférences personnelles, privilège de l'inventeur (X.T. pour Christ Toff est un mien nom d'auteur).
|
SLB-38A, B, C Seven League Boots’ Lightnings : ces appareils à Bottes de Sept Lieues se seraient situées dans le haut hypersonique : 34 km par saut ou par pas donc par seconde...
|
AFa-38A, B, C Air Fan Lightnings : s'il ne s'agit pas d'un malentendu en anglais entre ventilateur (air-fan) et réacteur double-flux (turbofan), il pourrait s'agir là d'appareils révolutionnaires (secrets).
|
PowDr-38 Power of Dreams : la position "couché sur le ventre, yeux fermés" permet la téléportation instantanée (vitesse infinie).
|
COA-38A, B, C Coal Lightnings : dérivés de P-38 à moteur à vapeur, brûlant proprement du charbon.
|
U-238A, B, C Uranium Lightnings : dérivés de P-38 à moteur nucléaire, n'émettant que de la vapeur nuageuse sans fumée, tout bon pour la planète ! (presque : avec déchets radioactifs 6 fois moins actifs dix mille ans après...)
|
F-138, -238, -338 Starfighter : dessins imaginant (en l'an 1952 dans mon délire) ce que serait le futur "missile Lockheed avec un pilote dedans", qui allait finalement s'avérer le XF-104 très différent.
|
LoBuBv-38, -41, -141 : projets pacifiques de 1939 par le groupe Lockheed-Burnelli-Blohm&Voss, imaginaires hélas.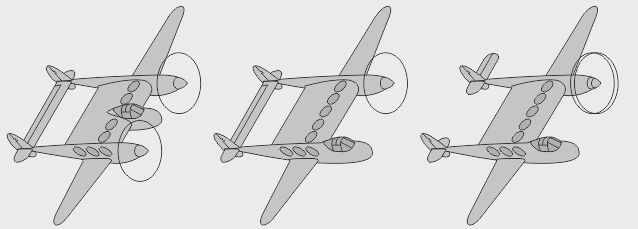
|
XHaP-38, YHaP-38, HaP-38A Harry Potter Lightnings : avions magiques tranformant les armes ennemies en fromage puant (pas pour jeter sur les pauvres populations innocentes, mais pour que les méchants abandonnent leurs avions affreux).
|
MT-38A, Z, B MicroTurbo Lightnings : avions VTOL/ADAV sanas ailes à réacteurs pivotants.
|
MB-38A, B, C Multiboom Lightnings : dérivés de P-38 déclinant l'abandon du fuselage unique.
|
RATO-38A, B, C Rocket Lightnings : dérivés de P-38 à décollage assisté par fusées
|
| RATO-38A, B, C Rocket Lightnings : dérivés de P-38 à décollage assisté par fusées
|
ASh-38 Airship Lightning : double-dirigeable pour passagers, lointain cousin du P-38.
|
WS-38A, B, C Woodstock Lightnings : dérivés de P-38 attribués à substances hallucinogènes illicites.
|
P-38M-6A, -6B, -6C HexaLightnings : P-38 à 6 moteurs et 6 poutres, pour faire simple (et tester pour trouver la meilleure façon).
|
| – ALIN-38 Lightning Airliner : jet de ligne à moteurs hauts comme le Fokker Vfw 614. – Psh-38X Lightning Pusher : ancêtre de l'ALIN-38, évitant de payer sur l'ALIN-38 un Copyright à Fokker. – Psh-38W : version navale initiale de Psh-38, justifiant totalement les hélices hautes, au sec. 
|
FCC-38 Cloud Carrying Lightning : avion invisible à étapes successives de camouflage dans le nuage qu'il emmène avec lui.
|
Mitsubishi J9M (= Ki-999) LightHero (prototype), Laitero (de série), Laitero Kai : copies de P-38 ayant abouti à l'avion lançant la bombe atomique sur Los Angeles la nuit de Noël 1944 (1,13 millions de tués, avec plein de bébés, encore "mieux" que la légende Hiroshima)... [Je n'aime pas du tout du tout les avions militaires].
|
STO-38JA, JB, JC ; Jet-Lightnings à performances STOL (ADAC : avions à décollages et atterrissages courts). STO veut ici dire Short Take-Off, pas Service du Travail Obligatoire.
|
CPC-38 Car Plane Compound ; mariage d'une autombile à un avion sans pilote, pour faire une voiture volante.
|
FC-38 Flyable Cat ; voiture pouvant décoller dans les airs (en cas de bouchons...) sans se rendre sur un aéroport.
|
AR-38 Area Ruled Lightning SST ; avion de transport asymétrique respectant au mieux la Loi des Aires.
|
Ecolo-38A, B, C : avions écologiques imaginaires – super-solaire, éolien (életrique rechargé par éolienne actionnée par le souffle des hélices et vent relatif), avion à pistons et carburant éthanolique (surnommé Pinard).
|
Lockheed-Leduc XLL-38, YLL-38, LL-38A : avions à statoréacteur/ramjet mixant les formules Lockheed P-38 et Leduc 021.
|
ANN-38A, B, C : Lightnings modernes à aile annulaire, pas de science-fiction mais (presque) véridiques....
|
WaB-38A, B, C Water Bomber Lightnings : dérivés pompiers volants du P-38. Réutilisables en avions à propulsion hydrogène (carburant léger mais requérant de gros volumes).
|
CDR-38A, B, C Charles de Rougé Lightnings : versions de P-38 à empennage en T avant expiration du brevet à ce sujet.
|
TJ-38A, B, C Tail-Jet Lightnings : versions de P-38 dessinées en 1963, après l'apparition de Caravelle, Mystère 20, HS Trident, DH125, Vickers VC-10, Boeing 727.
|
PuPu-38A, B, TwiPu-38A : versions de P-38 bimoteures simple corps, dessinées en 1941, après Fokker D-XXIII, Moskalyev SAM-13, Bolkhovitinov Sparka.
|
PuPu-38ZA, ZB, TwiPu-38B : versions doubles quadrimoteures double corps, préfigurant le Do-635.
|
XWP-38, YWP-38, WP-38A, Z, Z-2: versions ailes volantes des Lightnings.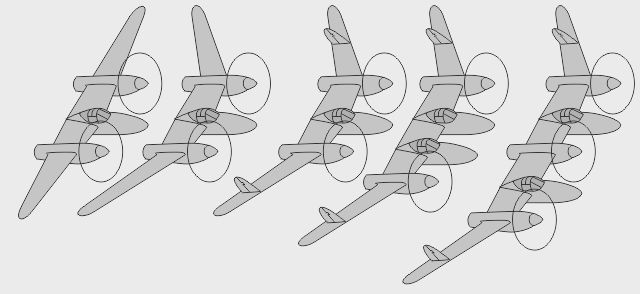
|
XB-38A, B, Z : ancêtres imaginaires du XB-44.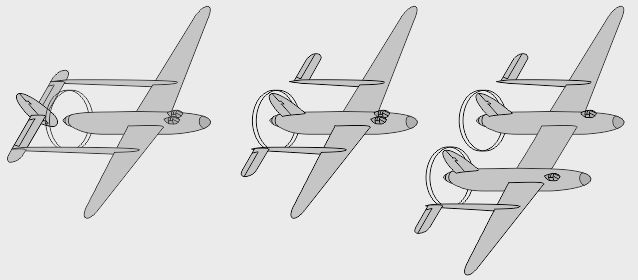
|
YB-38A, Z, Z2 : gros Lightnings imaginaires inspirés du XB-36.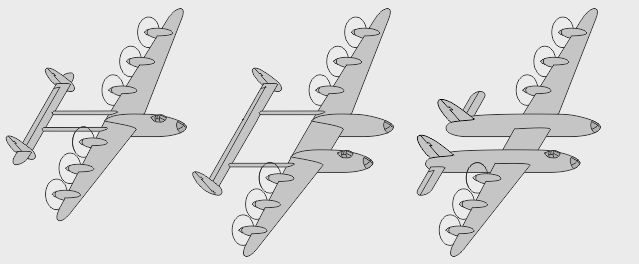
|
TFi-38A, Z, Z2 : Lightnings bidérives, monofuselage mais jumelé bien sûr.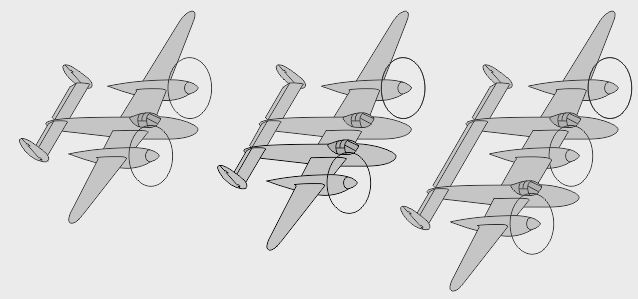
|
CRA-38A, B, C : Lightnings à hélices contrarotatives axiales, avec 2 moteurs axiaux (et arbres moteurs + engrenages éventuels).
|
FJ-38A, B, C : projets de Lightnings à 2 turbojets.
|
P-38/1m, /1m-A, /1m-B Single Engined Lightnings : projets de Lightnings monomoteurs tractifs à nez libre.
|
MPS-38A, B, C : Lightnings militaires pousseurs, imaginaires mais ce n'est pas grave.
|
XP-38P-55, YP-38P-55, P-38P-55 : versions de bi-Lightnings inspirées par le canard XP-55.
|
DON-38A, B, C : Lightnings inspirés par le Shavrov Donatsiya.
|
WD-38A, B, C : nouveaux Lightnings inspirés par les Willoughby Delta 8 et 9, à poutres portantes.
|
F38U1, U2, U3 : Lightnings inspirés par les Vought Corsairs à aile en W.
|
FEP-38X, C, R Four-Engined Lightnings : versions quadrimotrices, expérimentale/cargo/reconnaissance, créés à partir du modèle Constelightning imaginé par le whar-if modeller Captain Canada.
|
| – Lockheed L-022 Lightnin' : pré-projet (imaginaire) de P-38 à immense rayon d'action, grâce à deux petits moteurs V-770 pour le vol de croisière, les deux gros moteurs V-1710 ne servant qu'au décollage et pointe de vitesse éventuelle. – L-022T Trainer-Lightnin' : avion d'entrainement sans les gros moteurs. – L-122 Huge-Lightnin' : énorme version (ancêtre du L-130) à deux gros moteurs propulsifs (V-1710 ou V-3420), justifiant bien mieux les poutres que sur le futur (vrai) P-38. 
|
FAL-38A, B, C Falketning : croisements enbtre le Lightning et le Falke du DeviantArtist Rekalnus.
|
AiT-38A, B, Z Lightruk et Twin-Lightruk : hybrides de Lockheed Lightning et Benett/Waitomo/Transavia Airtruk.
|
RW-38A Multopning, HB-38 Brdtichning, WA-38 Aristoning : hybrides de Lightning avec les étranges Rheinflug Multoplane, Brditschka HB-23, Waco Aristocrat.
|
Lightnings dérivés de 3 avions bizarres : XC-138 Packning (du XC-120 Packplane), CL-138 Tilt-ning (du CL-84 Tilt-wing), Hosning (du Hosking Pitts).
|
S-38A Marauning, S-38Z-1 Twin-Marauning, S-38Z-2 Triplex-Marauning : Lightnings anachroniques dérivés du Spackman Twin-Marauder (modèle volant 1958 du what-if modeller PR19_Kit).
|
HH-38 Husning, HC-38, HHA-38 : dérivés Lightning du H-43 Huskie, en versions hélicoptère, avion, autogyre.
|
P-38E-1, E-4, E-2 : nouveaux Lightnings à nez moteur.
|
He-338Z, Y, X Zwilling Lightninks : P-38 modifiés à la mode He-111Z, et dérivés.
|
XC-238A à vide et plein, XC-238J : autres dérivés Lightning du XC-120.
|
P-38QF, P-38XF, P-76XF : Lightnings (et double-Lightning) quadridérives ou à dérives externes.
|
| – JuJu-38 hydravion à train aéroglisseur amovible (déployé ou rétracté en vol). [Merci à ma soeur Juliette, spectatrice du film Sully, ayant inventé cette posibilité sécuritaire, à illustrer] – Juju-38A amphibie plus simple. 
|
HY-38A, B, J : Autres hydravions Lightnings, pour le concours spécial des what-if modellers.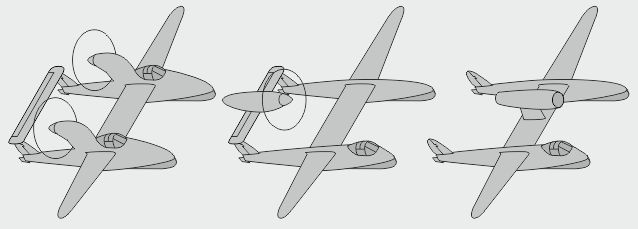
|
HY-38D, E, F : hydravions Lightnings asymétriques.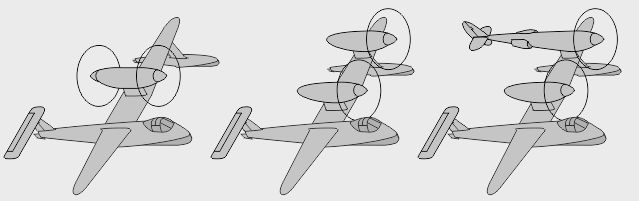
|
AST-38A, YAST-38, XAST-38 : chaînons manquants entre P-38 et un aéronef imaginaire d'un vieux numéro Amazing STories (aucun rapport avec Antibiotic Susceptibility Testing)
|
MTI-38A, B, C : Lightnings multi-niveaux (multi-tiers) inspirés par un dessin de principe par le what-if modeller McColm.
|
Pat-38A, P, Z : projets de maquette dans une nouvelle romantique que j'ai écrite.
|
SimP-38A, B, BB, J : depuis un projet de maquette "P-38 simplifié" jusqu'au "triple-bipoutre" inventé par mon jeune fils de 8 ans Jacky.
|
SimP-38C, D, E, F : dérivés simples (à poutres simplifiées) mais avec moteur(s) quand même.
|
SimP-38G, Z, Z-2 : variations sur le même thème des poutres simplifiées.
|
HJ-38A, B, C Hydrojet Lightning : dérivés de P-38 biréacteurs et plu' vraiment bipoutres.
|
HJ-38D, E, F : variantes d'Hydrojet Lughtning.
|
InMe-38ZA, ZB, ZC Intermeshing Propellers Double Lightnings : maquettes de Lightning à hélices engrenantes (ne tournant pas en vrai).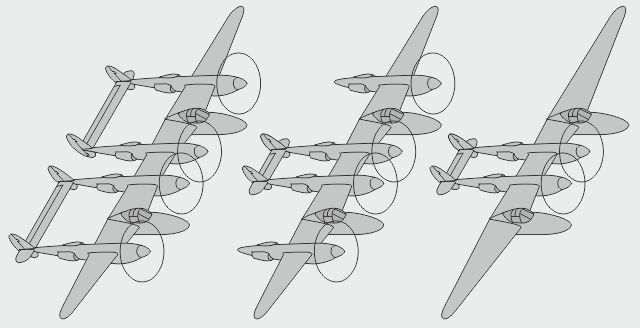
|
InMe-38AA, AB, AC Intermeshing Propellers Asymmetric Lightnings : dérivés asymétriques.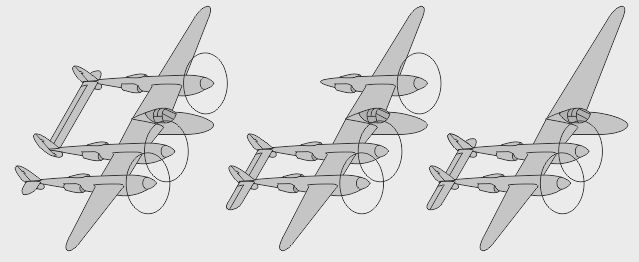
|
COMP-38 : biplan composite, support marin, avion porté.
|
BPF-38A : témoins de faisabilité pour mon projet de maquette Boulton Paul F-122B sur base Unicraft P.122
|
Lightn'jet A, B, C (asymmetric, biplace, courte envergure) : Lightning-jets de 1946
|
Lightni-jet A, B, C : dérivés optimisés des précédents.
|
P-38SW Super Woman, S-38SW-3, P-38SW-1 : Lightnings à aile en flèche (Swept Wing) de Curtiss XP-55, bipoutre ou tripoutre ou monofuselage.
|
Boulton-Paul BP.38A, B, Z Britning : synthèse entre le Bouton-Paul P.99 et le P-38, puis dérivés.
|
Lockherschmitt Lo-163B, C, D : dérivés Lightning du Me-163B fusée.
|
ScorPion-38 à 3 étapes de sa transformation (merci au what-if modeller Ericr pour l'idée de scorpion à base d'aéronef).
|
P-38FW Fightning, FW-2, FW-3, FW-4, CA : autour du thème Lightning Flying Wing (Aile Volante), voire canard pour un peu de stabilité quand même.
|
P-38E4-A Bigning, E4-B, E4-C : quafrimoteurs Lightnings simples.
|
P-38T-4 Tandning, T-6, T-6B : Lightnings polymoteurs à ailes tandem.
|
P-38T-6C, T-6D, A-6D : dérivés invraisemblables du P-38T-6B (suggestions du what-if modeler wuzak).
|
P-38U-6A, B, C : dérivés sages du P-38T-6B.
|
P-38-2A2, -2B2, -2C2 : puzzles ("bipoutres" ou pas ?) imaginés suite à une question du what-if modeller wuzak.
|
| – XMP-38 : monopoutre prototype – XMP-38Z = XBP-38V : bipoutre par doublement vertical (à dangereuses hélices engrenantes) – YBP-38V : bipoutre vertical final 
|
XMP-38Z-2, XMP-38Z-3, YMP-38Z : versions dérivées des précédents
|
YBP-38A, YBP-38B, YBP-38Z : versions dérivées du YBP-38V
|
| Maintenant, 10 images extrapolées de mon petit livre "Pacifique en paix 1941-45". Gee-Bee-38, Dji-Bi-Kai, GB-38F : avions de course façon Lighnting, avec moteur en ligne, ou moteur en étoile, ou en ligne à radiateur annulaire. 
|
Line-38, Suta-38, Mixte-38 : bimoteurs à motorisation diverse.
|
Warok-38, Taka-38, Dewa-38 : monomoteurs à refroidissement divers.
|
P-38W Korser, Ki-338M, WuM-38 : avions à dièdres d'ailes divers.
|
Bi-38-1, -2, -3 : avions biplaces de plus en plus puissants.
|
J-38-1, -2, -3 : avions à réaction divers.
|
Pi-38-141, P-38PP, Multi-38 : Lightnings asymétriques.
|
P-38-59, Ki-238, Ki-238-Kai : Lightnings à moteurs latéraux et hélice arrière.
|
Hyd-38A, B, C : Lightnings à flotteurs divers.
|
BB-38, Ki-338B, Ki-338C : Lightnings divers à verrière avant.
|
P-38-IVA, IVB, IVC : Lightnings quadruple-corps, complétant ma classification des bipoutres (1:bifide, 2:bifuselage, 3:triple-corps).
|
Delta-38A, B, C Delta Booms : Lightnings à poutres en triangles.
|
| - P-38W Impossible Lightning : maquette que j'ai construite, échelle 1/72. - P-38W-2 : dérivé imaginé par le what-if modeller salt6. - P-38W-3 : version double du précédent, redevenant bipoutre. 
|
| - L-322/2 Lightning 2 : vue cavalière d'un profil à queue de Bronco trouvé sur Alternate History.com. - L-322/2B : version biqueue en T-T. - L-322/2A : version asymétrique optimale. 
|
L-322/3 Lightning 3, /3B, /3A, /3C : dérivés compatés de la version 2.
|
| - Marcel Dulong Flying Circus : tripoutre compact inspiré du P-38. - Glying Dircus : version bipoutre. - Hlying Eircus : version plus aérée. 
|
FC-38A, B, P : chaînons manquants entre Flying Circus et P-38
|
J-38A, B, C : depuis la construction 3D de mon fils Jacky, des dérivés presque réalistes...
|
J-38A', B' : versions améliorées par Jacky constructeur...
|
DIL-38A, XDIL-38, YDIL-38 : représentation d'une caricature de Dilou, et chainons manquants depuis le vrai P-38.
|
| – BNP-38A : bi nacelle-poutre (twin "pod ans boom") – BN-38B : bi-nacelle (twin pod) – BP-38C : bi poutre-pure (twin "genuine boom") 
|
XF38U-1, YF38U-1, F38U-1 : autres chainons manquants entre P-38 et XF5U-1 crèpe volante.
|
XF39U-1, YF39U-1, F39U-1 : versions à moteurs centraux.
|
38 & 40 Lightning Street : maisons réalisées à partir de carcasses P-38, à coté de la rivière.
|
XP-38S, YP-38S, P-38S-5 : évolution depuis le Lightning vers un quasi-Mustang bipoutre bifide.
|
Yar-38A, B, C, D : Lightnings inspirés d'un brevet Yarmorkine..
|
LeP-38A, B, C : Lightnings inspirés d'un brevet Lepoix..
|
LeP-38D, E, F Weird Lightning : autres Lepoix Lightnings étranges..
|
Pent-38A, B, C Pentagon Lightning : dérivés P-38 de la construction que m'a offert mon fils de 9 ans, pour la fête des pères 2018.
|
PLD-38P, L, D : nouveaux hybrides de P-38, Levasseur PL-200, Dornier Schneider 1928, à flotteurs-poutres porte-dérives.
|
J38F, J39F, J40F : hybride de Lightning et Grumman Duck (à flotteurs coques inclassables), puis dérivés terrestres.
|
DorP-38A, B, C : ancêtres Lockheed du Dornier Do-28.
|
DorP-38D, E, F : autres variations ramenant presque à la normale.
|
Spitning Mk.1, 2 : hybrides de Lightning et Spitfire, pour rendre le P-38 "davantage British" (pour le concours RAF des what-if modellers).
|
Spitning Mk.3, 4, 5 : versions sans aile tandem, plus sages/légères.
|
Spitning Mk.6, 7, 8 : à partir de 2 Spitfires avec un coeur de P-38, jusqu'à un quasi P-38 de retour.
|
AC-38-1, -2, -3.: Lightnings jouets à air comprimé (pas de moteur mais grande vitesse !)
|
Pat-38B, C, D : Lightnings inspirés de brevets (patents) Walsh, Girodin, Lorfeuvre.
|
Lightito Mk.1,2, 3 : Lightnings en bois s'inspirant (de plus en plus) du De Havilland Mosquito.
|
Whirlning Mk.1,2, 3 : Lightnings s'inspirant (de plus en plus) du Westland Whirlwind.
|
SPe-38A, B, C : Lightnings imaginaires issus d'un brevet Spehler de 1941.
|
SPe-38T, U, V : versions hydravions imaginées par le what-if modeller tonton42, justifiant les hélices hautes astucieusement.
|
| - SPe-38W : modification entre SPe-38T et U, imaginée par le what-if modeller wuzak (moteur central et engrenages vers hélices latérales). - Doc-38A : schéma de Lightning inspiré du livre de propagande franchouillarde "La Seconde Guerre Mondiale/Mes P'tits Docs Histoire". - Doc-38B : réinterprétation du Doc-38A expliquant l'absence de casseroles devant les hélices. 
|
ERI-38H-500, H-200, H-300 : maquette du what-if modeller ericr mixant P-38 et Hughes 500, et chaînons manquants.
|
ERF-38H-500, H-200, H-300 : en s'inspirant des ERI-38H, ces modèles remplacent la base Hughes 500 par une Alouette 2. Argumentaire technique : c'est pour faire joli.
|
ALO-38A, B, C : autres Lightnings ayant débouché sur la formule Alouette 2, côté poutres.
|
Lightpire Mk.1, 2, 3 : hybrides de Lightning et De Havilland Vampire.
|
Essai ExB-38 : Lightning à boulons explosifs (Explosive Bolts, avec Boom = boum et poutre) pour larguer la queue et réduire la trainée (augmenter la vitesse, ou se crasher).
|
Horsning, Lancasning, Metning : versions Lockheed des Horsa, Lancaster (reco), Meteor.
|
WUZA-38A, B, C : versions propulsives suite à une idée du what-if modeller wuzak.
|
KI-38A, B, C, D : dérivés d'un dessin mystérieux de mon fils Jacky, 9 ans.
|
KI-38B-2, C-2, D-2 : versions plus sûrement bipoutres des précédents.
|
SuWi-38A, B, C, D : Lightnings dérivés d'un livre pour enfants "Super-Wings" où je n'ai pas trouvé de bipoutre mais une aile volante bidérive.
|
SuXi-38A, B, C, D : versions jets des précédents.
|
SuXi-38A', B', C', D' : versions à quatre réacteurs demandées par le what-if modeller tonton42, merci.
|
SuVi-38A, B, C, D : versions monomoteur à hélice de nez, n'ayant plu' guère de raison d'être bioutre.
|
SuVi-38E, F, G : versions allongées suggérées par le what-if modeller wuzak.
|
SuVi-38H, J, K : versions à poutres en bout d'aile suggérées par le what-if modeller wuzak.
|
SuVi-38L, M, N : versions crées par le what-if modeller steelpillow.
|
SuTi-38B, A, C : versions biplanes à poutres en bout d'aile basse.
|
Tan-38A, B, Z : versions à aile tandem avec poutres en bout d'aile arrière.
|
P-38XA-10, 38YA-10, 38A-10A : hybrides de P-38 et A-10 inspirés du Lightning Hog de Donald Yatomi.
|
HS-38A High Speed Lightning, HS-38B, HS-38C : dérivés de P-38 à haute vitesse.
|
CLAS-38A, B, C, D Puzzle-Lightnings : cas difficiles à classer, entre bipoutre et aile volante bidérive.
|
P-38V-3420A, B, C Double-Engine-Lightnings : P-38 monomoteurs remplaçant les deux V-1710 par un V-3420.
|
P-38V-3420ZA, ZB, ZC Double-Engine-Twin-Lightnings : P-38 à double moteur jumelés.
|
P-38V-6840A, B, C Triplex-Lightnings : P-38 triples à deux doubles moteurs.
|
P-38V-6840D, E, F : autres P-38 triples à deux doubles moteurs.
|
P-38V-6840G, H, J : P-38 jumeaux à deux doubles moteurs.
|
P-38E-6 & E-6L 6-engined Lightning, P-38AUD Asymmetric Upside-Down : versions à moteurs décalés verticalement.
|
WOW-38C, B, A Lightning Flyer : hommage Lockheed à l'ancêtre Wilbur & Orville Wright Flyer.
|
P-38TJ-3, YP-38TJ-3, XP-38TJ-3 Turbojet Lightning : étapes du développement pas à pas d'un P-38 triréacteur.
|
| – P-38S-80 : Lightning inspiré du Sukhoy Su-80. – P-38WD : Lightning inspiré d'une maquette "P-38 wonderduck" à queue cassée et micro-hélices. – Pap-38NF : Lightning inspiré d'un long film "numéro 2" (sur 3 ? donc non fini ?) décrivant le montage d'un Papercraft P-38J. 
|
P-38S-81, -82, -83 : dérivés divers du Lightning S-80.
|
| – P-38TA-2 : Lightning inspiré du gros Kerbal Angel II ("P-38-T"). – P-38TA-1 : version sans réacteurs du précédent. – P-38TC : version petite, "standard", du TA2. 
|
CF-38C, D, E Canuck Lightnings : P-38 inspirés d'un Mustang à verrière de CF-100.
|
CT-38A, B, C : dérivé du Cobi-Toys P-38 et chaînons manquants.
|
UR-38A, B, C : ancêtres Lockheed imaginaires de l'Uber taxi tripoutre.
|
BEL-38A, B, C : ancêtres Lockheed imaginaires de l'Airbus Beluga.
|
SAM-38A, B, C : dérivés bimoteurs Lockheed du Moskalyev SAM-9 Strela.
|
MOS-38A, B, C : ancêtres (?) Lockheed du Moskalyev SAM-4 Sigma (en fait la séquence n'est pas historiquement MOS-38/SAM-4/SAM-9/SAM-38 mais SAM-4/SAM-9/SAM-38/MOS-38, les deux derniers groupes étant imaginaires).
|
R-38A, B, C Four-Engine Lightning : avions de reconnaissance à très long rayon d'action inspirés du P-38.
|
R-38D, E, F Axial Big Lightning : versions à moteurs non latéraux, sans asymétrie en cas de panne.
|
R-38G, H, J Lightning Quadrimoteur : versions autres encore, de gros quadrimoteur Lightning.
|
R-38K, L, M Lightning Rear Push : versions à nombreux moteurs arrière.
|
R-38N, P, Q Weird Lightning : versions inspirées des He-177, Bv-141, DL-10.
|
R-38R, S, T Twinfuselage Lightning : versions à deux grosses structures latérales.
|
R-38U, V, W Pylon Lightning : versions à moteurs à distance.
|
R-38X, Y, Z : derniers quadrimoteurs pour finir la série alphabétique.
|
BPW-38A, B, C : dérivés Lightning d'un composite Bouton-Paul/Westland, avec le what-if modeller wuzak.
|
| – FBL-38 : maquette Lightning tripoutre de Frank Barillaro. – LBP-38 Lighting Bolt Pusher : maquette Lightning propulsif de Craig Salters. – LBQ-38 : version modifiée mienne du LBP-38. 
|
GLA-38A, YGLA-38, XGLA-38 : origine Lockheed imaginaire d'un projet de G.Lafon en 1945.
|
XGLA-38B, YGLA-38B, GLA-38B : Lightning bipoutres inusuels, vertical ou horizontal bifide.
|
GLA-38Z, Z-2, Z-3 : Zwillings (jumeaux siamois) des avions précédents.
|
GLA-38Z-4, Z-6, Z-5 : autres doubles étranges de la même famille Lafon/Lockheed.
|
NAP-38A, B, C, D, E : dérivés Lightning d'un projet Napier de 1946.
|
B-38W, YB-38W, XB-38W, PB-38W : astronef Edklingon B-38 Wing (source Star Wars mixée à kit P-38) et chaînons manquants aériens. Datation virtuelle : 2035, 2005, 1975, 1945.
|
TuJ-38A, B, C, D : Lightnings à turbojets, initialement ailes volantes puis redevenant bipoutres.
|
XTTJ-38, YTTJ-38, TTJ-38A Twin TurboJet Lightning : évolution d'un Lightning à réacteurs centraux.
|
| – TW-38 au décollage et en croisière : nouveau Lightning à aile basculante (tilt wing). – TR-38 : Lightning hélicoptère trirotor. 
|
Lokichi E38L1 Lightnink, E38L2, E38L3 : Lightnings hydravions fusées inspirés de ma maquette de Aichi E31A1.
|
| – P-38 CM Comet Moth Lightning à ailes battantes relevées et abaissées (inspirées de papillon bifide). – TJ-38 : hélicoptère Lightning avec rotor à réaction (tip-jet). 
|
Bf-338A, B, C : Lightnings inspirés d'un Bf-110 trimoteur du what-if modeller ericr, à moteurs en ligne et en étoile.
|
HEL-38A, B, C : Lightnings hélicoptères à dispositif anti-couple tractif (comme le Fairey Gyrodyne).
|
| – P-38X-114 Ekranoplightning : hydravion à effet de sol inspiré du RFB X-114. – Harrining : ancêtre du Harrier, au décollage et en croisière. 
|
P-76S-1, S-2, S-3 Several Seat Double Lightning: versions extrapomées de la maquette P-76 du what-if modeller scotaidh.
|
| – P-38WW Water Wheel Lightning (ou World Wide) : P-38 cyclocoptère avec roues à aubes, en test (perdant) contre la voie hélices. – SWi-38 Single Wheel Lightning : version cyclogyre avec une seule roue à aubes (n'ayant jamais volé). 
|
Zero Length Launch Lightnings (ZeLL-L) : P-38 à décollage fusée sans roulage.
|
| – P-38X-15 : Lightning bifusée pour voler à Mach 7. – BV-38 Lightnip : Lightning basse vitesse multiballon dirigeable (airship). – MAS-38 : Lightning à sustentation par effet Magnus. 
|
FaW-38A, B, C : Lightnings dérivés plus ou moins lointains du principe FanWing.
|
| – P-38CW : nouveau Lightning à aile canal (Channel Wing). – P-76C : Double Lightning push-pull semi-canard. – P-38 NACA : appareil de test alaire trouvé sur alternatehistory qui semblerait l'ancêtre du Lockheed Swordfish. 
|
P-76D, E, F : variations sur le thème des Super-Lightnings surpuissants.
|
P-38CW-4, P-76Z, P-38Z-76 : multiplications des P-38CW et P-76.
|
| – P-38CW-4+ : quadrimoteur à aile canal et meilleur centrage massique. – P-38CW-1 : monomoteur bi-Lightning à aile canal. – P-38 HoT : Lightning à queue-maison (Home Tail). 
|
P-38H-21, H-210, H-219 Luhu : "ancêtres Lockheed" du Heinkel He-219 Uhu.
|
FAB-38A, B, C : Lightnings brésiliens (Fab ne veut pas dire Fabrication ni Fabuleux mais Força Aérea Brasileira).
|
He-638A Luhu, He-638B, C, D : dérivés Lightnings de ma maquette He-619 Uhu.
|
PTAK-38 au décollage et en croisière, PTAK-38Z : dérivés Lightnings de la maquette PTAK-30 du what-if modeller Dizzyfugu.
|
Ju-38B, Ju-38A Stukning, Ar-38A : dérivés Lightnings du Ju-87 Stuka et son concurrent Ar-81.
|
P-38AM-1, -2, -3 : Lightnings AsyMétriques construits en série (dans mes rêves).
|
PG-38 Piggie (décollage et croisière), PJ-38A, B : Lightnings bijets à réacteurs Pegasus ou classiques.
|
PHH-38A Lightnocopter, -38B, -38C : hélicoptères Lightnings à 2 rotors séparés.
|
VT-38 (au décollage et en croisière), TT-38 : biréacteurs axiaux dans la famille Lightning.
|
| Les vrais Lightnings de photo-reconnaissance sont codés F-4A, F-5A à F-5G, mais voici les imaginaires F-4Q, F-5Q, F-5R, F-5S. Note: F ici ne veut pas dire Foto (photographie) ni Fighter (chasseur) mais Fantasy/Fun/Fabulous/Fake (fantasie/amusement/fabuleux/faux ou fou). 
|
| Les P-38 Lightning étaient les Lockheed Model L-22, L-122, L-222, L-322, L-422, le dérivé XP-49 était le L-522, mais il convient de compléter : – L-622 : version à cockpit pressurisé, ici imaginée avec canopée hémisphérique solide, – L-722 : pas décrit, on peut imaginer un modèle spécial à refroidissement amélioré (avec hélices intégrées), – L-822 : version navale, peut-être à ailes pliantes mais ça ne se voit pas en vol, ici dessiné en version petite pour ascenseur de porte-avion. 
|
L-922, L-1022, L-1122 : derivés Twin-Lightning du L-722 Lightning.
|
DH-38.88A, B, C : intermédiaires entre Lightning et DH-88 Comet.
|
P-238 Dual Lightning, P-338 Triplex Lightning, P-438 Half Twofold Lightning : composites divers.
|
N.438 (en croisière ou au décollage), N.438Z : ancêtres Lockheed (imaginaires) du Nord N.500.
|
Bv-038A, B, C : ancêtres Lightning du Bv-141 asymétrique.
|
S.38A Minining, S.38G, S.38J : ancêtres (à hélice/planeur/à réaction) Lockheed du SIPA S.200 Minijet.
|
AW-38A Annular Wing Lightning, AW-38B, AW-38C : P-38 à ailes annulaires, sans lien avec Armstrong Whitworth.
|
PXX-38 Rocket Lightning : missile piloté, ancêtre des X-3 et F-104.
|
P-38X-54, X-55, X-56 Lightnoose : mixes entre P-38 et XP-54 Swoose Goose.
|
MWV-38A, B : Micro-Winged Vertical Lightnings.
|
HR-38A, B, C Blacklight : ancêtres du SR-71 autre avion Lockheed, supersoniques à hélices (Highspeed Recon Lightnings).
|
LAA-38A, B, C Lightning Avion Anormal (Lightning Abnormal Airplane) : la configuration bipoutre étant plutôt usuelle, l'originalité demande davantage d'audace.
|
Bv-038D, E, F : Lightnings push-pull inusuels (peut-être parce qu'imaginaires).
|
F-1038, 1039, 1040 Starlight : intermédiaires entre le F-38 Lightning et le F-104 Starfighter (demandés par le what-if modeller steelpillow).
|
| Véridiques P-38 présentés dans le magazine Le Fana de l'Aviation Hors Série n°63 : – F-5G : dernier dérivé photo du Lightning, – P-38-H2X : dérivé radar biplace construit en quelques exemplaires, – Pathfinder : dérivé éclaireur du Lightning. 
|
| Dérivés civils présentés dans le magazine Le Fana de l'Aviation Hors Série n°63 : – NX25Y : avion de course créé par la J.D.Reed Co, – NX61121 Teterboro Special : avion de course piloté avec relatif succès, – Lightning Spartan : modèle employé par une société de services canadienne. 
|
| Lightnings à très gros nez imaginaires : – BoP-38A : inspiré des Boeing Phalcon/EC-18B/Aria, – Liou-38T : inspiré de l'Ilioushin 76T, – Shg-38 : inspiré du Shenyang J-5 (ou MiG-17F). 
|
X-608/L7, /L8, /L9 : dérivés doubles des propositions pré-Lightnings à configuration non-bipoutre.
|
| Autres Lightnings inspirés du Fana de l'Aviation Hors-Série n°63 : – X-608/L4 : véridique préprojet ayant abouti au vrai Lightning, – X-608/L10 et /L11 : versions asymétriques hélas oubliées en vrai par Lockheed. 
|
P-38BD-5A, B, C Bedening : mélanges entre des Lightnings et des microscopiques Bede BD-5.
|
P-38P-51D, B, BB : appareils pour tester aile de Mustang au demi, imaginés par le what-if modeller wuzak.
|
AMag-38, AWAC-38A, AWAC-38B : autres Lightnings imaginés par le what-if modeller wuzak, avec anneau anti-magnétique, ou radar moderne, ou radar ancien.
|
TUt-38A, B, C Turret Lightning : P-38 de reconnaissance à tourelles d'observation (imaginés par les what-if modellers wuzak et PR19_Kit).
|
BBs-38A, B, C Stork Lightning : Lightnings cigognes apporteurs de bébés (légende véridique en 1941-45 mentionnée par le what-if modeller wuzak).
|
ETB-38A, B, C Engine Test Bed Lightnings : P-38 pour test de turbine, énorme ou/et petite (imaginés par le what-if modeller wuzak, façon B-17 et Lincoln).
|
ETB-38D, E : dérivés pentamoteurs du Lightning ETB-38A.
|
| Lightnings de "récupération en vol" (suggérés par le what-if modeller wuzak) : – FUL-38A : avec système de récupération surface-air Fulton (attrapant un fil entre individu au sol et ballon en altitude), – FST-38A : satellite Film Recovery System attrapant parachutes (de descente de film satellitaire) en vol, – FST-38Z : version doublant les chances d'attraper le parachute. 
|
GF-38A, B, C : ancêtres Lightning du Virgin Atlantic Global Flyer (suggérés par le what-if modeller wuzak).
|
BipP-38A, B, C : Lightnings bipoutres biplans.
|
SesP-38A, B, C : Lightnings sesquiplans (à un plan et demi), suggérés par le what-if modeller wuzak.
|
SesP-38A-2, B-2, C-2 : sesquiplans opposés, à demi-aile basse.
|
XF-38F-12, G-12, H-12 : Lightnings testeurs pour la pointe avant du gros XF-12 Rainbow (idée du what-if modeller wuzak).
|
| Lightnings à base tripoutre : – P-38Dr-1 Dreidecker Lightning : triplan simple proposé à l'Allemagne du Baron Rouge, – P-38Hx-6 Lightning Exaplane : version double triplan en tandem, – P-38Nv Lightning Nonaplane : Lightning nonaplan (9-plans) proposé à l'Italie du Caproni Noviplano. 
|
BCC-38A, XBCC-38 Balloon Cable Cutter Ligntnings : coupeurs de cables contre ballons de barrage, réaliste à la He-111H ou intuitif erronné.
|
| Nouveaux Lightnings souhaités par le what-if modeller wuzak : – P-38PLC Power Lines Cutter Lightning : avion coupeur de fils électriques (en rase-mottes), – BKD-38 Beer Keg Delivery Lightning : transporteur de futs de bière ("c'est bon pour le moral" selon les généraux). 
|
ARo-38B, A, C Avion-Robinet : Lightnings extincteurs de forêts en détresse (inspirés d'une maquette [non bipoutre] du what-if modeller ericr).
|
ProPil-38B, A, C Prone Pilot Lightning : dérivés de P-38 à pilote couché et sans roulette de nez.
|
DBz-38A, B, C : Avions doubles avec porteur et élément mobile (principe inspiré de projets Daimer-Benz, à la demande du what-if modeller wuzak).
|
TxE-38A, B, C : Lightnings trimoteurs à moteur tractif central haut.
|
TTL-38C, D : versions à 5 axes de Tandem Twin-Lightning.
|
RK-38A, B, C : quadrimoteurs fusée de la famille Lightning.
|
GL-38A, B, C Glidning : planeurs Lightning, à aile de plus en plus pure.
|
CP-38A, B, C : Lightnings monomoteurs canards.
|
CP-38D, E, F : version asymétriques des précédents, demandées par le what-if modeller wuzak.
|
Pipi-38B, A, C : ancêtres Lockheed du Taurus G4 Pipistrelle, pilotés en France par Monsieur Condom (le nom de l'avion ne fait pas du tout sourire les Etasuniens, alors que le nom du très sérieux pilote leur parait ridicule, importable – tout est relatif...).
|
| DM-38 : Lightnings à poutres spéciales de la famille franco-philippine Ditchon-Meunier : – DM-38JJ-1 : créé pour mon fils Jacky Jemsey, – DM-38JJ-2 : créé pour mes neveux Julio et James, – DM-38JJ-3 : créé pour mon petit neveu Jaden Job. 
|
P-38Bo-390A, B, C : hybrides de P-38 Lightning et de projet Boeing 390 Flapjack.
|
DLa-38A, B, C Delanne Lignting : P-38 à ailes tandem et motorisation accrue.
|
PéPé-38A, B, C : P-38 à base tripoutre.
|
PTB-38A, B : tripoutres à poutre centrale arrière.
|
PTB-38C, D : dérivés à cockpit arrière suggérés par le what-if modeller wuzak.
|
PTB-38E, F, G, H : dérivés à aile centrale droite ou absente, suggérés par le what-if modeller wuzak. 
|
PTB-38J, K, L : versions asymétriques, suggérées par le what-if modeller wuzak.
|
Prof-38A, B, C : versions asymétriques à profil droit identique au P-38 Lightning standard.
|
PSU-38A, B, C : aucun rapport avec le Parti Socialiste Unifié ou le Paris Sport Universitaire, il s'agit du 38e Poursuiveur (chasseur terrestre) américain (étasunien) à moteurs SUrélévés, pour avoir un train d'atterrissage petit/solide.
|
PSU-38D, E, F : versions à puissance accrue.
|
| – Veeblefitzer Ve-211E Blitzen : inventé par le DeviantArtist Jimbowyrick1 – P-38Ve, Vf, Vg : intermédiaires entre le précédent et le P-38 standard 
|
DTP-38A, C, B Double TailPlane : Lightnings à empennage horizontal double (aucun rapport avec le vaccin Diphtérie-Tétanos-Polio).
|
| – RAZ-38A : Lightning imaginé par le what-if modeller wuzak, à empennage au format Rasoir de sécurité multilame. – PX-38X, V : Compléments Lightnings à empennage complexe/multiple. 
|
| – RAZ-38B : dérivé du A suite à clarification par le what-if modeller wuzak. – RAZ-38C : ajout à la famille des Lightnings multi-empennages. 
|
TriL-38A et B TriLightning, QuaL-38A QuadLightning : déivés de P-38 à moteur(s) sur l'arrière en complément.
|
MonoL-38A, B, C MonoLightning : dérivés allégés des précédents.
|
BeBe-38A, B, C Belly to Belly Lightning : accollements de deux P-38 d'après une idée du what-if modeller Weaver.
|
BeBe-38D, E, F Shaft and Gear Lightning : autres P-38 à 4 moteurs actionnant deux doublets d'hélices contrarotatives.
|
P-38Zv-1, -2, -3 Zvezda Stand Lightning : maquettes possibles employant 4 supports détournés au lieu d'un seul pour présentation en vol, et le résultat à 8 jambes n'est même pas "avion" mais "objet étrange"...
|
LPL-38A, B, C Lateral Pilot Lightning : dérivés Lightning d'un montage Lego de Jon Hall.
|
AAA-38A, B Lightning À Avant Allongé : multimoteurs tractifs tripoutres.
|
PAV-38A, B, C Lightning à Pilote Avancé : visibilité améliorée, au point de devenir tripoutre.
|
|
– Oxford Brick-block P-38 Lightning : jouet simplifié à monter soi-même (pour les "+ de 7 ans") – Batplane Lego P-38 : version fantaisie du super-héros Batman – Batplane "Real" P-38 : chainon manquant entre le précédent et le vrai P-38. 
|
SpBw-38A, B, C Steelpillow Batwing : dérivés suggérés par le what-if modeller SteelPillow.
|
SpBw-38D, E, F : versions à 1-2-3 poutres.
|
P-38VQ, GP-38VQ, XP-38VQ : famille imaginée à partir d'une photo mal interprétée de VQ Warbirds.
|
ATra-38 : version Lockheed du projet AVA Air-Train.
|
ATra-38A, B : dérivés Air-Train moins énormes.
|
SPw-38A, B, C, D : Lightnings en flèche sans queue (arrière) requis par le what-if modeller Steelpillow.
|
Wk-38A, B, C : nouveaux Lightnings dessinés à la demande du what-if modeller wuzak.
|
Los-38A, B, C : Lightnings à aile losange.
|
SPw-38E, F, G : dérivés des précédents suggérés par le what-if modeller Steelpillow.
|
Wk-38D, E, F : autres Lightnings dessinés à la demande du what-if modeller wuzak.
|
Wk-38G, H, J : encore d'autres Lightnings dessinés à la demande du what-if modeller wuzak.
|
Wk-38K, L, M Lightning X-wing : P-38 à aile en X demandés par le what-if modeller wuzak.
|
Wk-38MZ-1, -2, -3 : dérivés doubles redevenant bipoutres.
|
PIF-38A, B, C Propeller In Fuselage : versions à hélice intégrée dans l'avant de fuselage.
|
PIF-38D, E, F : variantes à hélice intégrée dans le fuselage.
|
PIF-38G, H, J : versions suggérées par le what-if modeller wuzak.
|
PIF-38K, L, M : nouvelle demande de wuzak, riant des malentendus (créatifs !) précédents...
|
NS-38A, B, C Ninja Star Lightnings : P-38 à voilure en forme d'étoile Ninja.
|
|
– WD-38W Wall Decor Lightning : objet 3D trouvé sur Internet – WP-38W : version imaginée un peu plus bipoutre du précédent – WT-38W Wood Toys Lightning : modèle en bois trouvé sur Internet – WP-38X : version davantage P-38 mais reprenant le nez plat, pour des phares ici 
|
OV-38A Broncning, OV-38B, C : dérivé (ou ancêtre OV-8) imaginaire de l'OV-10 Bronco, et versions monoplaces.
|
Jones IP-38A Ionic Propulsion Lightning, IP-38B, C : versions de P-38 à moteur (électrique) ionique, dessinés pour une nouvelle romantique à moi.
|
|
– FT-38F Fatty Lightning : mignonne caricature 3D trouvée sur Internet – JL-38J : Lightning imaginé par l'historien alternatif Just Leo – FG-38F Paper Model : maquette en papier de planeur Lightning trouvée sur le site Fiddlers Green 
|
Toyriffic_Gobot Bolt (vertical et horizontal), TGB-38B : robot humanoïde en forme de P-38 (debout au décollage puis en vol), et version davantage "avion P-38".
|
RA-38A Racer Lightning, RA-38B, C, D : avions de course Lightning, à trainée aérodynamique réduite et puissance accrue, au delà du raisonnable/volable.
|
XF-438, YF-438, F-438A Phantom Lightning : dessins à partir d'une photo trouvée sur Facebook par un what-if modeller.
|
SNEH-38A, B, C : Lightnings modifiés Sans Nez Entre Hélices, pour une bonne raison en final, le point de vue panoramique touristique.
|
SEL-38A, B, C : Single Engined Lightnings (monomoteurs) moins lourds que les P-38 "normaux".
|
WH-38A, B, C : Rotodyne Lightnings suite à une demande du what-if modeller wuzak.
|
Cocani 38A, B, C : dérivés Lightnings d'un projet de Luigi Colani.
|
Ferry 38A, B, C : modes de transport maritime de Lightnings à remonter à l'arrivée.
|
TL-38A Twin-Lightning, B pour pilotes gauchers, C Triplex-Lightning : dérivés de P-38 à pods additionnels.
|
P3D-38GD, D, G : Lighnting construit par imprimante 3D en 2 pièces, aptes au vol avec un peu d'imagination (sans demi-pilote mais radio-commandées)...
|
|
– F³S²-38A Fan Fold Foam Standoff Scale P-38 : petite réplique en mousse – F³S²-38B : version assez similaire de P-38 "vrai" (à petite verrière et dérives intégrées). – F³S²-38C : version monomoteur asymétrique pour grande hélice 
|
Funder & Lightnings (et P-38 monomoteurs associés) : modèles jouets radio-commandés inspirés du P-38 à partir de 2005 (par YarSmythe ?) 
|
|
– Tailspin Models Micro RC P-38 : jouet radiocommandé représentant un Lightning en plan. – General Hobby P-38-52 RC : autre avion téléguidé presque fidèle sauf petites casseroles d'hélice. – GH-38A : Lightning imaginaire reprenant les petites hélices avec un moteur central et engrenages. 
|
|
– P-38 Foam Toy : petite réplique de Lightning en mousse déformable (rotative). – FmT-38B : essai de torsion à ailes vers le bas. – FmT-38A : Lightning presque normal mais à poutres "tournées". 
|
| Lightnings à moteur Napier Dagger suggérés par le what-if modeller wuzak (24 cylindres en ligne en H refroidis par air) : – NaD-38A : version test avec un moteur restant normal. – NaD-38B : version principale bi-Dagger. – NaD-38C : version allégée (asymétrique), 1 seul Dagger suffisant. 
|
NaE-38A, B, C : modifications de ND-38 avec refroidissement amélioré (suggéré encore par wuzak) et hélices contra-rotatives.
|
WUC-38A, B, C Weird UnderCarriage Lightnings : P-38 à train d'atterrissage bizarre, inspirés par le P-38 FX-816 Henanxifbm et le SNCASE SE.100.
|
Ki-438A, B, C Lightinah : enfants d'un mariage entre un P-38 Lightning et une jolie Ki-46-III Dinah.
|
| Mise sous mon angle de différentes sources :. – ET-38 : "cartoon caricature" de Lightning trouvée sur Internet chez etsy.com. – McF-38 : dessin du caricaturiste Jean Barbaud dans un album "Lieutenant Mac Fly". – FaT-38 : modèle radio-commandé de"Fatty Lightning" (gros et gras P-38). 
|
FI-38A, B, CVL-38A : Lightnings à dérives (fins) spéciales et dérivé civil.
|
A-38 d'un nommé Danel Rolph sur Art Station (DRA-38 ?), et dérivés miens.
|
Caricature iStock Funny Fighter Jet Plane (FFJP-38 ?), et dérivés miens.
|
| Mise sous mon angle de différentes sources :. – WP-38 : Neatoshop Wolf P-38. – AB-38 : dessin du caricaturiste Philippe Abbet P-38. – SPy-38 : caricature Sparky P-38. 
|
WTF-38A, B, C Wing Tip Fin Lightnings : P-38 à dérives en bouts d'ailes.
|
WTF-38D, E, F : autres P-38 à dérives en bouts d'ailes.
|
SW-38A Swept Wing, SW-38B Super Woman, SW-38C South Wales : famille de Lightnings à aile en flèche pointue.
|
TriS-38A, B, C : Lightnings à 3 surfaces (ou canard dérivé) à hélices intégrées aux poutres.
|
WZ-38A, B, C : Lightnings demandés par le what-if modeller wuzak, avec moteurs dans les poutres et hélices contrarotatives axiales.
|
WZ-38A-2, B-2, C-2 : versions canards redemandées par wuzak, clarifiant un malentendu.
|
VHW-38A, B, C Vey High Wing Lightnings : dérivés de P-38 à aile loin au-dessus des poutres, comme imaginé par le what-if modeller tonton42.
|
SaD-38A, B, C Lightning turned Vampire : interprétations de la minuscule maquette 1/700 du what-if modeller SanDiego89 ayant déguisé un P-38 en Vampire.
|
DRL-38A, B, C : Lightnings hélicoptères à doubles rotors latéraux.
|
Phoe-38A, B, C : essais de constructions de Lightning à partir de ruines (inspirés par le film "Le vol du Phoenix").
|
Phoe-38AZ, BZ, CZ : versions doubles (bipoutres à nouveau) des précédents, s'avérant incroyablement réussis.
|
XTT-38, YTT-38, TT-38A : élaboration pas à pas d'un trimoteur tractif à deux postes de pilotage.
|
Lockheed-Bell FM-38B, C, D Airacning : nouveaux mélanges Airacuda-Lightning.
|
| – PBV-38A : dessin à partir d'une caricature de Papy Boum Voodoo 34. – PBV-38Z-1 : avion double pour comparaison au triste véridique – PBV-38Z-2 : pur jumeau siamois pour rétro-comparaison 
|
Foo-38A, B, C Footning : hybrides de Lightning et d'un brevet Foote d'autogyre (US D209252), suggérés par le what-if modeller steelpillow.
|
PR-38Z-1, -2, -3 Double-Pond-Rasning : versions doubles de l'hybride entre Lightning et Pond-Racer.
|
P-38S-55, -66, -77 : hybrides de Lockheed P-38 et Savoia S-55, Savoia-Marchetti SM-66 et SM-77 (aucun lien de ces codes avec Sylvie Métailié...).
|
P-38S-55N, -66N, -77N : versions des précédents à moteur de nez.
|
P-38S-567sto, -22, -00 : autres versions apparentées aux précédentes.
|
P-38EE-1, -2, -3 : hybrides de Lightning de chez Lockheed et English Electric, à partir d'une photo montage vue sur Facebook.
|
P-38SA-567 Low cost, -54 Minimum Price, -76 Different : versions Asymétriques des P-38S semi Savoia.
|
P-38SF-567, -54, -76 : versions monoflotteurs (Single Float) monocoques des bicoques précédents.
|
DH-38Q, R, S : quadrimoteur trouvé sur Facebook avec marquage DH (truqueur photo), et dérivés miens.
|
P-38SF-54C, P-38S-54C, P-38SF-01 : versions à asymétrie compensée par dérives obliques, ou à asymétrie sans moteur latéral.
|
P-38SF-02, -03, 03T : variantes du -01 avec 2 ou 3 moteurs comme les Savoia 55, 66, 77.
|
P-38S-0F Flying Wing, -0C canard, -0M Multiple rear booms : options initiales pour le P-38S.
|
WE-38 Welsh Lightning : expliquation d'une ruine sur plage galloise : l'érosion étant symétrique, la ruine asymétrique implique(rait ?) une source asymétrique !
|
WE-38A, B, C : versions extrapolées de la ruine WE-38 différemment, ramenant au P-38 pesque normal.
|
PP-38PP, PQ, PR : Lightning push-pull aperçu en photo truquée sur FaceBook (avec refroidisseurs sur poutres étonnament loin des moteurs), et 2 autres dérivés envisageables.
|
P-38S-0M-3, P-38S-0M-3T, P-38S-0F-3 : versions additionnelles trimotrices du Lockheed-Savoia.
|
P-38S-3ST-1, -2, -3 : versions de Lockheed-Savoia à queue unique centrale.
|
P-38S-PECP-1, -2, -3 Pusher Engine Cockpit Pod : versions à cockpit intégré au groupe moteur propulsf central.
|
P-38T-55, -66, -77 : versions de bicoques modernisés sans poutrelles.
|
TpTr-38A, B, C : Lightnings tripoutres biplans à ailes décalées.
|
BpTr-38A, B, C : versions bipoutres asymétriques des précédents.
|
KindPNG WW2 Fighter, WW37, WW38 : Retranscription réorientée d'une image trouvée sur Internet, et chainons manquants.
|
P-38S-21, -51, -87 : hybrides de P-38 et bicoques Savoia 55, inspirés en même temps des Savoia 21, 51, 87.
|
P-38S-64, -65, -93 : hybrides de P-38 et bicoques Savoia 55, inspirés en même temps des Savoia 64, 65, 93.
|
TBPP-38A Turboprop Lightning, TBPP-38B, TBJT-38A Turbojet Lightning : versions de P-38 à turbopropulseurs ou turboréacteurs.
|
XP-38J-21A, B, C : dérivés Lightning d'un Saab J.21 repensé par l'IPMS Stockholm et le what-if modeller Chernaya Akula.
|
| – SEP-38A Single Engine Lightning : monomoteur asymétrique bipoutre sur base P-38. – SEP-38F : version équilibrée à Fenestron anticouple en bout d'aile gauche. – SEH-38 : hélicoptère bi-Fenestron sur base P-38. 
|
| – DéP-38 : jouet "Lightning en dépron" en photographie sur Internet. – Swa-38 : "swappable P38" (à moteurs échangeables ?) dessiné sur Internet. – Matjey Pmj-38 : "P-38 pusher MJ semi-profile" aussi dessiné sur Internet (et construit avec film de vol radio-commandé). 
|
| – UFd-38 Unfolded Lightning : origami déplié (à plat) conçu par Robin Kearney. – Fdd-38 Folded Lightning : le même, plié pour avoir du contrôle en lacet (présence de pseudo dérives, en V ou WW inversé). – F-38DD : version intermédiaire entre le précédent et un "vrai" P-38. – F-38DE : idem moins compact, plus proche encore du P-38. 
|
| – FTe-38 Flite Test Lightning : famille de P-38 radiocommandés (Flite se prononce comme Flight, c'est comme si on disait Vohle Dèçay pour Vol d'Essai). – FTi-38 FT-inspired Lightning : version dérivée, interprétée à partir de photo à un stade inachevé. – FFF-38 : autre modèle volant, dit Fan Fold Foam (mousse en éventail). 
|
| – Jimbo Cactaur P-38 : principe architectural d'un P-38 en légo montré sur Internet. – Gramho P-38 : étrange Lightning mixé à deux F4U Corsair, sur site Gramho.com en thème FliteTest 2019. – P-38F-4U : simplification monoplace du type Gramho. 
|
| – Jimbo Cactaur P-38 : principe architectural d'un P-38 en légo montré sur Internet. – Gramho P-38 : étrange Lightning mixé à deux F4U Corsair, sur site Gramho.com en thème FliteTest 2019. – P-38F-4U : simplification monoplace du type Gramho.
|
| – Instagram P-38 : autre P-38 légo montré sur Internet (chez Gramho.com en thème Warbird). – IGMP-38 : P-38 très transformé pour se déguiser comme le légo précédent. – IGP-38 : P-38 presque normal inspiré du précédent. 
|
Misu-38A, B, C Lightning Misunderstanding : silhouettes imaginaires expliquant l'apparence d'une petite image, en fait faussée par un pavé de démarrage vidéo, malentendu.
|
P-38SC-1, -2 : hybrides de P-38, hydravions Savoia et Cant.
|
ZwiP-38A, B : jumelage (zwilling) de P-38, asymétriquement.
|
ZwiP-38C, D, E : autres zwillings P-38 mais symétriques.
|
Hau-38A, B, C : bipoutre dessiné par Jon Hauser en 1944, et chainons manquants montrant qu'il s'agissait d'un Lightning.
|
CGV-38A, B, C Canard Good Visibility Lightning : dérivés de P-38 à vue dégagée vers devant et le bas tout en ayant un empennage avant, inspirés du moderne XL-507 de TheXHS sur Deviant Art.
|
| – XOR-38 : découpage de feuille pour Origami Lightning amélioré (par rapport à celui de Robin Kearney). – YOR-38 : pliage plié finalisé. – OR-38A : "vrai Lightning" (imaginaire) à queue en pliage. 
|
BaFo-38A, B Back-and-Forth-Lightning : push-pulls dérivés du P-38 en regardant vers l'avant et l'arrière.
|
BJt-38A, B, C Boom-Jet Ligntnings : versions de P-38 avec turboréacteurs à l'arrière.
|
PAsy-38A, B, C Pursuit Asymmetric Ligntnings : asymétriques peu solides dérivés d'un plan tronqué de P-61 par OmerCybokou.
|
DJ-38A, B, C : interprétations minimalistes d'un plan avec certains traits peu visibles (imaginés manquants) [plan DJ-38 d'OmerCybokou].
|
RP-138, 238, 338 Rocket Lightnings : versions à moteur fusée, de plus en plus rapides.
|
RP-438, 538, 638 : versions améliorées à moteur fusée.
|
B-38P-38, -39, -40 : dérivés (purement Lightning) d'un photomontage mélangeant B-17 et P-38.
|
| – LH-38 Temco Long Horn Article 36 : maquette quadriplace de Sport16ing présentée sur Deviant Art. – LH-38A Medium Horn : version plus asymétrique visuellement mais moins asymétrique sur le plan du couple de renversement des hélices. – LH-38B Short Horn : version encore plus asymétrique, redevenant bipoutre. 
|
| – LPg-38 Lightning Painting : création de genredleader sur Deviant Art. – P-38 Sketch: dessin au trait de Jester1 sur Deviant Art. – P-38 Render : image 3D de Tony Torius sur Deviant Art. 
|
| – P-38 IS Insane Lightning : dessin de Insane Samantha sur Deviant Art. – P-38WL White Lightning : P-38 inspiré du P-61 II White Widow dessiné par Pixel Pencil sur Deviant Art. – P-38XX : dérivé P-38 du 6XX Mosquito dessiné par Tomzoo sur Deviant Art. – P-38XY : évolution du XX transformé de tripoutre en bipoutre. 
|
| – P-38 ADAV : Lightning VTOL à soufflantes alaires inspirées du Gabriel's Lance Bomber par Dalilean sur Deviant Art. – La-38-LO : P-38 dessiné par Sabeda sur Deviant Art. – HF-38 Heritage of Flight : dessiné par SearinoxDragonofFire sur Deviant Art. 
|
| – ProP-38 : Lightning avec second poste avant pour pilote couché ("prone"), comme sur un Meteor présenté par le what-if modeller wuzak. – ProP-38A Assis : version modifiée pour que le pilote avant trouve la place de s'asseoir. – ProP-38B : monoplace à pilote couché mais avec pare-brise quand même. 
|
| – XPR-38 : Lightning à ailes en W et radiateurs centraux inspiré du Expiramental Plane par UnknownJester sur Deviant Art. – P-38' Lightning-2 : vue 3D générée par 1301232 sur Deviant Art. – Chibi Lightning : dessin caricature par JesseMG sur Deviant Art. 
|
| – Kenisi Lautern 2 : dessin inspiré d'un Lightning sur Deviant Art. – Kenisi Lautern 1 : dessin push-pull davantage éloigné d'un Lightning, sur Deviant Art. – P-38KL : ma synthèse des deux dessins précédents. 
|
| – EED-38 : montage Lego d'ErenErakhardDraws sur Deviant Art. – NSL-38 : autre Lego par ToaBanshee nommé Nano Scale Lego P-38, sur Deviant Art. – NSP-38 : "vrai" P-38 à nacelle centrale de NSL-38. 
|
| – LLS-38 Lightning's Last Strike : épave/ruine de P-38 accidenté, dessinée par Forked Tailed Devil (diable à queue fourchue, surnom du Lightning) sur Deviant Art. – LLS-38R Renewal : reconstruction presque complète du précédent, réparé. – LLS-38S Simple Lightning : reconstruction moins aboutie, sans second moteur disponible, en acceptant/gérant l'asymétrie (avec résilience ou proactivité, dirait-on aujourd'hui). 
|
LLS-38T-2, -3, -4 Twin wrecks : reconstructions à partir de deux épaves, avec 2 ou 3 ou 4 moteurs.
|
P-38S-55R, -77R : versions modifiées des Lightnings-Savoia.
|
Carg-38C, B, A : dessins inspirés du Cargauto imaginé par le délirant (gentiment) Omer Cybokou.
|
Carg-38CZ, AZ : versions doubles des précédents.
|
P-38 Hippolite, Hi-38A, B : modèle volant monomoteur appelé P-38 car bipoutre et versions un peu plus Lightninguisées.
|
JB-38A, B, C : Burnelli Jet Lightnings.
|
| – P-19 Half Lightning : demi P-38 présenté/imaginé par War Thunder (19 = 38/2). – P-19Z : forme double du P-19 pour redevenir bipoutre (Z = Zwilling = Jumeau). – YP-57 : adjonction d'un module P-19 à un P-38 presque standard (57 = 38+19). 
|
P-19T, P-57T : dérivés des précédents avec appariement longitudinal en plus.
|
P-19TB, P-19TB-2, P-57TB : versions bipoutres de certains parmi les précédents.
|
| – Tac-38 : Bijou "P-38 Tackette" aperçu sur Internet (the Air Force Museum Store). – Sim-38 : sorte deP-38 simplifié dessiné par LinaBean sur Deviant Art. – Sim-38B : chaînon manquant entre le précédent et le vrai P-38. 
|
| – FWPP-38 : Aile volante push-pull, version Lightning d'un dessin (DL 328 par Daniel Hernández Martín) trouvé sur ArtStation. – TBPP-38A, B, C : dérivés bipoutres du précédent. 
|
| – Mix-38A : inspiré d'un dessin ("A-10, P-38, F4U Mashup" par Donald Yatomi) trouvé sur ArtStation, ici en version davantage Lightning. – Mix-38B : version retrouvant deux poutres arrières. – Mix-38C : transformation redevenant globalement bipoutre. 
|
| – Mix-38B-2 et -3 : modifications du Mix-38B suggérées par le what-if modeller wuzak. – Mix-38B-4 : modificarion du Mix-38B-3 pour retouver une configuration bipoutre, non tripoutre. 
|
| – Mix-38B-3A : passage en mode "pylone avançant" du Mix-38B-3, à la demande du what-if modeller wuzak. – Mix-38B-3B : version encore plus avançante, même en vue cavalière à fausses verticales inclinées. – Mix-38B-4B : version bipoutre du précédent. 
|
| – SPt-38 : inspiré d'un dessin ("Split Tail" par Adam Baines) trouvé sur ArtStation, ici en version Lightning (à poutres en titane résistant aux gaz brûlants ?). – SPt-38A : version à stabilisateur. – SPt-38B : version bimoteur au lieu de trimoteur. 
|
| – RAR-38 Rocket Airplane Racer : inspiré d'un dessin (par Hiro Nakano) trouvé sur ArtStation, ici en version Lightning. – RAR-38A, B modifications rapprochant un peu du Lightning standard. 
|
XSTE-38, YSTE-38 : à la demande du what-if modeller wuzak, intermédiaires entre avion P-38 et astronef Star Trek Enterprise (imaginé comme agrandissement d'un STE-38).
|
XP-388 Pusher Prototype F.L.O.P., P-388A, P-388Z : à partir de la maquette inventée par le what-if modeller buzzbomb, des dérivés asymétrique et double ont été ajoutés.
|
Sgr-38A Distanzing, B, C : à partir du moderne projet Sager 06 Distanz (sur Art Station), dérivés P-38 à aile portée par poutre.
|
BPO-38B, A, C, D : binacelles (bipods) dérivés (façon Lightning) de l'UR-544 de TheXHS sur Deviant Art.
|
| – F-5-0-2Z Hornet : maquette hybride de demi P-38 et Buffalo mise sur Facebook par Keith Thomas Locke – F-5Z : version double. – F-5Y : version semi-double. 
|
MBx-38A, B, C : transition entre une boîte aux lettres de jardin dite Lightning et un vrai petit modèle radio-commandé.
|
SWk-38A, B, C : modèles Stipa-Wuzak intermédiaires entre les boîtes volantes précédentes et le prototype Stipa-Caproni véridique (auquel le what-if modeller wuzak dit qu'elles ressemblent).
|
CaB-38A, B, C Canard Boom Lightnings : tripoutres et bipoutre avec poutre avant portant plans canards.
|
| – CaB-38C2 : amélioration du C en enlevant les radiateurs sur le fuselage sans moteur. – CaB-38CZ : version double. – CaB-38CA : version asymétrique avec la place restante pour le dessin ("bouche-trou"). 
|
CaB-38Z-1, -2, -3 : dérivés des canards doubles précédents.
|
OC-38A, B, C : étapes pour créer un triplan à réaction asymétrique, suggéré par l'aéromodéliste Omer Cybokou.
|
| – Bon-38 : modèle volant d'un nommé Bokkinen. – FSA-38 : extrapolation d'un profil caricaturé par Flying Shamrock Art. – Slo-38 : version Lightning d'un modèle volant vu sur site Slowfly. 
|
Maq-38A, B, Z : projet de maquette que j'envisage de créer au 1/144.
|
P-38BSE, BSE-3, BSE-2 Booms Separate from Engines : versions imaginables à réception du kit 1/144 en pratique.
|
ELP-38A, B, C Engine on Little Plane : autres Lightnings à moteurs séparés des poutres, différemment.
|
JoP-38A, B, C, J : dérivés envisagés suite à une remarque du whatif modeller JoeP.
|
P-38F-7CF : version davantage Lightning du dessin "7F Coop Flyer" (vu sur Deviant Art), et dérivés P-76F, P-38F-7C.
|
XP-38L-153A, B, C : ancêtres Lightning des Lockheed L-153-8, L-153-11 (et L-153-99 asymétrique inventé par moi-même).
|
XP-38W-189 Lightwulf, 189A, 189B : hybrides de P-38 et Focke-Wulf Fw-189 Uhu.
|
| – XP-38W-5 : planeur tricycle à nez court. – XP-38W-189C : P-38 à poutres-moteurs de Fw-189. – XP-38W-189D : idem avec une seule poutre de Fw-189. 
|
XP-38W-189E, 189F, 189G : doubles de P-38 et Fw-189, trimoteurs bistabilo et monostabilo, bimoteur.
|
XP-38W-189H, 189J, 189J-2 : autres versions de doubles P-38/Fw-189, avec réacteur(s) éventuel(s).
|
XP-38W-189K, 189L, 189M : encore d'autres versions de Fw-189 mixé à un stock de P-38.
|
Lockheed X-608, L-22, XP-38 : dessins préliminaires débouchant sur le premier prototype Lightning.
|
XPCH-38, YPCH-38, PCH-38A : Lightningà bizarres à Poutres Contournant les Hélices.
|
XPCH-38B, YPCH-38B, PCH-38B : autres P-38 similaires.
|
XPCH-38C, YPCH-38C, PCH-38C : encore d'autres versions à poutres évitant les hélices propulsives.
|
| – P-38AD : statue de ArtDecoCollection sur Internet. – Custom CC-38A : dérivé de P-38 dans la collection Crimson Skies. – FTD-38L Forked Tail Devil : caricature dessinée par Jez Tuya. 
|
SNR-38A, B, C : dérivés Lightning du modèle volant Itek Super Nova RC.
|
| – AWP-38 : dessin trouvé par un ami sur Internet (sans noter l'adresse) qu'il appelait "un curieux P-38" ("A Weird P-38" ou "A Strange P-38"). – AWP-38B : chainon manquant avec le P-38 classique. – AWP-38C : version à nez davantage habituel mais rapprochant les poutres car micro-hélices. 
|
| – Dustygriffin DG-38 : dessin trouvé sur Internet, bougé sous mon angle personnel. – IaP-38 : dessin de Ian Peacock pour Sarik Hobbies, bougé aussi. – FDM-38 : dessin de Fandom.com, bougé aussi. 
|
| – Doo-38 : dessin de CaptainDoodlebob sur Drawception, bougé sous mon angle personnel. – FA2-38 : dessin Art-1942 de Fandom. – XFA2-38 : chainon manquant entre le précédent et la source P-38. 
|
| – FA3-38 : dessin Art-1943-2 de Fandom, bougé sous mon angle personnel. – FA3-38B : dessin Art-1943-3 de Fandom. – P-38FA : vrai Lightning reprenant des idées de Fandom. 
|
QU-38A-1,-2, -3 : étapes de construction de mon hypothétique maquette Quatning.
|
PP-3838X, Y Doublightning : maquettes envisagées à partir de deux petits P-38 à échelle 1/144.
|
P-38CR, CR-2, CR-3 : dérivés légers du CR-38PA asymétrique. CR-38C, P, PA : Lightnings cargo ou à passagers inspirés par le Conroy SkyMonster.
CR-38C, P, PA : Lightnings cargo ou à passagers inspirés par le Conroy SkyMonster.
|
| – LinP-38A : équivalent Lightning d'un Avro Lincoln de test moteur. – LinP-38B : équivalent Lightning d'un prototype de patrouilleur Lincoln australien. – NC-138A : équivalent Lightning d'un NC-135A de la mission Burning Light. 
|
Northrop T-38P, R, T Lightalon : chainons manquants entre le P-38 et le T-38 Talon.
|
P-38T ³-1, -2, -3 : Lightnings d'entrainement à pod(s) triplace(s).
|
|
YB-38 Fortning, YB-38A, B, C : versions très Lightning du Boeing XB-38 Flying Fortress (B-17 à 4 moteurs de P-38). (Le dessin m'ayant inspiré est un B-17 bipoutre/aile-volante : "Flying wing bomber by Yury Milovidov on Deviant Art") 
|
| Le what-if modeller Scotaidh ayant trouvé sur FaceBook un étrange dessin de B-29 bidérive bimoteur sans ailes externes (FBk-29 ?) : – FBk-38 : correspondant Lightning du FBk-29. – FBk-38A : versionn à nez "davantage Lightning". – FBk-38B : version Boeing comme réinventant un B-38 à partir de la base FBk-38. – FBk-38Z : version bifuselage du précédent (avion de reconnaissance à endurance accrue, sans bombes). 
|
| – O-38T : chainon manquant entre le Douglas O-38P et le Lockheed P-38. – XU-38P : ancêtre du Schweizer RU-38 Twin-Condor. – A-38P : chainon manquant entre le P-38 et le Beechcraft A-38 Grizzly. 
|
| – C-38P : ancêtre Lightning du biréacteur Gulfstream C-38 (longtemps après le Douglas C-38, comme le C-5 a été postérieur au C-141). – X-38P : ancêtre Lightning de la navette Scaled X-38 Crew Return. – H-38P : ancêtre Lightning du Sikorsky H-38 Short Tail. 
|
XC-38,YC-38, YC-38Z : chainons manquants entre le premier C-38 (Douglas DC-2) et le P-38.
|
XP-38BP-146,YP-38BP-146, P-38BP-146 Boutonning : ancêtres de l'ADAV Boulton Paul P.146.
|
| – P-38KZ KaZoNing : Lightning dérivé d'un Black Widow dessiné par les jeunes Kai et Zoé, petits-enfants de l'aérophile Omer Cybokou. – XP-38KZ : prototype testant la nacelle prévue. – YP-38KZ : autre prototype aidant à la mise au point des ailes asymétriques complexes. 
|
Awe-38A, B, C, D : dérivés Lightning d'un étrange avion vu sur TheAwesomer.
|
LL-138A, B, C, D : chaînons manquants entre l'astronef Inthert LL-109 Exploration Craft (sur HelloBricks) et le P-38, "prouvant" que le Lightning a une origine extraterrestre.
|
Fig-38A, B, C, D : chaînons manquants entre le Fighter 8-2014 de Jon Hall (sur BrickNerd) et le P-38, "prouvant" que le Lightning est d'origine Légo.
|
KD-38A, B, C : chaînons manquants entre le Kenins 25ZS Douglas (sur SecretProjects.co.uk) et le P-38, "prouvant" que le Lightning est d'origine lettonne et bipoutre axiale.
|
YBy-38A Yellow Belning, YBy-38B, -Z : Lightnings inspirés d'un avion imaginaire (monopoutre) baptisé "Yellow Belly", vu sur FaceBook.
|
AX-38A, B, C Lightning Express : Lightnings inspirés du projet octamoteur Christmas Aerial Express.
|
| – RB-38A : dessin très inspiré par The Ratty Bat (la chauve-souris miteuse) de Christian Pearce. – RP-38B : version un peu davantage Lightninguisée. – RB-38L : version très Lightning à hélices + jets (pistons et réacteurs). 
|
ACL-38A, Z, Y : Almost Classical Lightnings : Lightning presque classique, et doubles ramenant vers la comparaison au cas normal.
|
DZ-38A, B, C : dessin Cartoonish P-38 Lightning de David Zuren, et hybrides avec le vrai P-38.
|
MD-38A, B, C : Lightnings inspirés d'un dessin de Martin Dahl (nom incertain, peu lisible).
|
MD-38AP, CP : versions des précédents avec des phares pour vue de nuit (détail présent sur la source de Martin Dahl).
|
KN-38A, B, C : Lightnings inspirés d'un dessin de Kyriakos Ntatidis sur ArtStation.
|
| – Yug-38A : Lightning inspiré d'un "Jet-like Trainer" yougoslave de 1991 à hélice carénée. – Yug-38B : version trimotrice monoplace du précédent, bien plus proche du standard P-38. – Gru-38 : version Lightning.d'un projet Grumman Tribody de 1978 
|
MnT-38A, B, C : Lightnings à train d'atterrissage monotrace.
|
MnT-38D, E, F : autres Lightnings monotraces, à dérives basses.
|
|
MnT-38D, E, F : autres Lightnings monotraces, à dérives basses.
|
Ho-138A, B, C, P : ancêtres du Horten Ho-229 ayant débouché sur le P-38, "découverts" avec l'aide d'un Ho-229 de Rob Caswell sur Deviant Art.
|
XPP-38 Push-Pull Lightning, YPP-38, YPP-38B : dérivés de famille Lightning autour d'un dessin trouvé sur Internet (sur Facebook sans citer l'adresse source).
|
DH-38D, E, F Turret Photoshop Lightnings : P-38 à tourettes, inventés comme trucages photos par David Holmes sur Facebook.
|
DH-38G, H, P-38DaHo : compléments des précédents.
|
DH-38J, P-38DavH, P-38Davi : autre Lightning truqué par David Holmes, et dérivés miens.
|
DH-38K, P-38DHZ, P-38DHZ-3 : encore un Lightning truqué par David Holmes, et mes dérivés bifuselages.
|
CBd-38B, A, Z CardBoard Lightnings : Lightnings en carton à base trouvée sur pinterest/s4series.com.
|
P-38Re-1, -2, -3 : Lightnings inspirés d'Airspeed AS.31 et d'une image de pusher bipoutre trouvée sur Facebook.
|
NV-38A, B, C : Lightnings à nez vitré.
|
L-722B, C, D : Lightnings à hélices propulsives intégrées (dans les poutres), inspirés d'un modèle aperçu sur Facebook.
|
ToK-38A, B, C : Lightnings inspirés du modèle Tomahawk Kaiju d'Albert sur brothers-brick.com.
|
BZ-38A, B, C, D : chainons manquants entre le P-38 et un dessin d'avion bizarre trouvé sur Facebook.
|
SaC-38A, B, C : Lightnings tripoutres à dérive centrale inspirés d'un dessin "Satan's Cigar" aperçu sur Facebook.
|
SpP-38A, B, C : Lightnings inspirés d'un modèle réduit fabriqué avec 2 bougies d'allumage (spark plugs) formant poutres, vendu par etsy.com.
|
BriM-38A, B, C : dessins inspirés du jouet Brickmania P-38 Lightning.
|
Amb-38, FiFi-38, O-38P : Lightnings prioritaires de secours ambulancier, pompier, policier.
|
P-38SA-1, -2, -3 : Lightnings de la police de Los Angeles inspirés par le Spectrum SA-550 du what-if modeller Dizzyfugu.
|
J.38A-1, -2, -3 : hybrides de Lockheed Lightning avec Saab J.21, et P-38 ressemblant au planeur précédent.
|
J38W1, J38W2, J38W3 : hybrides de Lockheed P-38 Lightning avec Kyushu J7W Shinden (= "Magnificent Lightning" en anglais).
|
| – J.38SP : amélioration du J.38A-1 imaginée par le what-if modeller steelpillow. – J.38W : version canard du J.38A-1 inspirée du J38W3. – J.38X : version de Saab Lightning "trisurface". 
|
| – OH-38A : maquette du what-if modeller Ericr à nacelle P-38 devant corps d'hélicoptère Hughes 500 OH-6 Cayuse. – OH-38B : hélicoptère ailé avec rotors engrenants. – OH-38C : dérivé triplace birotor prudent et avec hélice tractice pour aller plus vite. 
|
PP-3838Z, ZZ Twin-Doublightning : versions doubles de PP-3838Y.
|
Limàl-38A, B, C : versions Lightning de l'avion-sous-marin du livre "L'Incroyable Machine À Liberté" (K.Saunders/M.Ottley).
|
OH-138A, B, C : avions P-38 à nacelle panoramique de Hughes 500 OH-6 Cayuse.
|
Py-38A, B, H : Lightnings à poutres sur pylones.
|
DM-38A, B, C, D : Lightnings dérivés d'un asymétrique dessiné semble-t-il par Damon Moran à la façon Crimson Skies.
|
Sti-38A, B, C : chainons manquants entre P-38 et Stinson A, à pare-brise incliné vers l'avant.
|
TaL-38A, B, C : chainons manquants entre P-38 et un dessin de gros avion sans queue (TailLess).
|
P-333888, P-33338888, P-33338888B : dérivés des précédents suggérés par le what-if modeller Omer Cybokou.
|
J'ai terminé de rédiger et illustrer un petit livre sur la diversité des avions Lightning (et Zero).
|
XFac-38, Fac-38A, Fac-38B : version P-38 d'un avion canard Légo (ou autres briques plastiques) vu sur Facebook, et dérivés à poutres grossies mais sans mitrailleuses.
|
JH-38A, B, C : versions Lightning bâties autour d'une création Fe-47 Rapier de John Hall sur Hellobricks.com.
|
GD-38A, B, C : versions Lightning bâties à partir d'une création de Gregory Dees sur Neon Seed Studios 2013.
|
FK-38A, B, C : versions Lightning bâties à partir d'un jet bipoutre aperçu sur FaceBook.
|
XP-38B-599, YP-38B-599, P-38B-599 : dérivés Lightning du projet quadrimoteur bipoutre à grand empennage Boeing 599.
|
XP-38E-300, YP-38E-300, P-38E-300 : dérivés Lightning du projet octomoteur tripoutre sans dérive Junkers EF300.
|
GV-38A, B, C : dérivés Lightning du projet hexamoteur bicoque Gilbo V-64 Airseaplane de 1928.
|
CELP-38A, B, C : Lightnings à moteurs centraux entrainant des hélices latérales par arbres de transmission et engrenages (Central Engines Lateral Propellers).
|
LECP-38A, B, C : Lightnings à moteurs latéraux entrainant des hélices centrales par arbres de transmission et engrenages (Lateral Engines Central Propellers).
|
TriC-38A, B, C : Lightnings tri-cockpits.
|
TriC-38D, E, F : Lightnings tri-cockpits complémentaires à hélice pousseuse.
|
DouD-38A, B, C : versions Lightnings d'un dessin d'avion étrange vu sur FaceBook, en remplaçant les énormes mitrailleuses par des dispositifs-mystères (Double Device).
|
RW-38B, C, D : versions Lightnings du "Blade 328 de Richard Wright sur Artstation" (RW n'est pas ici "Real World", monde réél...).
|
FA-38A, B, C, D : versions Lightnings du "Fly attack de Waldemar-Kazak sur DeviantArt".
|
FA-38E, F, G : versions Lightnings de l'autre élément du même tableau.
|
PTw-38A, B, C, D : versions Lightnings d'un dessin aperçu sur Pinterest/Twitter, aile volante ou bipoutre ?.
|
IPR-38A, B, C : versions Lightnings d'un photo-montage de B-17 biplan à hélices engrenantes (intermeshing propellers) de moteurs différents, presque impossible "en vrai" sans crac-boum rapide.
|
ReSu-38A, B, C : Lightnings de "Recce & Surveillance" avec trois membres d'équipage, 1 pilote assis et 2 observateurs allongés.
|
P-38Fw-189A, B, C : Lightnings inspirés de Focke-Wulf Fw-189 et conseils des what-if modellers Dizzyfugu et PR19_Kit.
|
CExt-38A, B, C : Lightnings à plans canards externes inspirés d'une image aperçue sur FaceBook.
|
CTG-38A, B, C : Lightnings dérivés du Phantom A184 de Cutangus sur Deviant Art, lu avec erreur prenant la transparence pour asymétrie.
|
SX-38A, B, C : Lightnings dérivés du tripoutre canard SXB-355 Trident de The XHS sur Deviant Art.
|
Per-38A (F4U-38 Corsning),Per-38B, C : Lightnings dérivés du bipoutre double-tracteur TR-4 Hawker Perregrine de DevilDalek sur Deviant Art ; les canons mitrailleurs sont ici remplacés par des sprays de parfum floral.
|
XPK-38A,B, C : Lightnings dérivés du canard pousseur avant XPlain Mk 1.
|
ExR-38A,B, C : Lightnings dérivés d'un dessin aperçu sur Facebook, à moteurs en étoile entraînant hélices distantes contrarotatives via engrenages et arbres de transmission.
|
ExB-38A,B, C : Lightnings dérivés d'un dessin aperçu sur Facebook, cargo très militaire transporteur de char d'assaut, ici rendu civil.
|
RFFE-38A,B, C : Lightnings surprenants (Radiators Far From Engines) dérivés d'un plan de Comiso90 sur ww2aircraft.net.
|
RFFE-38D,E, F : autres Lightnings de la même famille.
|
ACD-38A,B, C Airacudning : Lightnings à nacelle motrice de Bell YFM-1 Airacuda.
|
ZB-38A,B, C : Lightnings multi-push-pull dérivés d'un photomontage de XB-42 à 12 hélices vu sur Facebook.
|
ZB-38A-2,B-2, C-2 : dérivés asymétriques des précédents.
|
BJB-38A,B, C : Lightnings dérivés d'un immense biplan à réaction vu sur Facbook (BJB = Big Jet Biplane).
|
FCB-38A,B, C : Lightnings dérivés d'un dessin tripoutre symétrique, ou bipoutre asymétrique, vu sur Facbook.
|
ISL-38A,B, Z, C, D, Z2, E, Z3, Z4, Z5, Z6, Z7 : grande famille Lightning inspirée par la petite famille des Britten-Noraman Islander et Trislander.



|
WTP-38A,B, C : chainons manquants ente le Wagner Twin Tri-Pacer (à hélices presques engrenantes) et le P-38 Lighting.
|
UAS-38A,B, C : chainons manquants ente le drone Thales UAS-100 et le P-38 Lighting.
|
DHP-38A,B, C : représentation sous mon angle habituel d'un trucage photo de David Holmes sur Facebook, et 2 dérivés cousins.
|
DHP-38D, E, F : dérivés à réaction des précédents.
|
DBL-38A, B, C : dérivés bipoutres du double Lightning tripoutre.
|
PolyP-38A, B, C : dérivés quadripoutres de Poly-Lightning.
|
QE-38A, B, C : autres quadrimoteurs (Quadri-Engine) Lightning.
|
QE-38D, E, F : autres quadrimoteurs Lightning, à moteurs cette fois axiaux (sans asymétrie si un est coupé, ou deux-trois...), push-pull-push-pull ou push-push-pull-pull.
|
QE-38G, H, J : autres quadrimoteurs Lightning, à formule canard ou ailes tandem.
|
DBL-38D, E, F : dérivés push-pull (pousseur-tracteur) du DBL-38A.
|
DBL-38G, H, J : versions quadrimoteurs des précédents.
|
PBv-138A, B, C, A', B', C' : versions améliorées par Blohm und Voss du P-38. 
|
DPFW-38A, B, C : Lightnings intermédiaires entre les formules "aile volante binacelle" et "bipoutre".
|
QH-38A, B, C : Lightnings inspirés d'un Quadri-Hélice (à deux hélices intégrées) aperçu sur Facebook.
|
TOO-38A, B, C : Lightning-toons (de dessin animé) sur la base d'un vieux dessin "piggyback" d'autrefois, vu sur Internet.
|
XBQ-38, YBQ-38, BQ-38A, BQ-38Z : Lightnings dérivés d'un dessin jet biqueue vu sur pinterest.
|
SCV-38 Camco V-Lightning : dérivé du véridique prototype Slingsby Camco V-Liner (avion publicitaire des années 1960).
|
SCV-38A, B, C : dérivés non-publicitaires du SCV-38
|
QF-38A, B, C : dérivés Lightning d'un astronef quadrifusée vu sur Facebook.
|
|
– IL-38A : dérivé Lightning d'un avion semblant impossible à faire atterrir (Impossible Landing). – IL-38B : dérivé avec tentative de solution par train très très bas (et besoin d'immense échelle pour que le pilote monte à bord). – IL-38C : dérivé avec tentative de solution par crochet devant attraper un cable fixé solidement au-dessus du sol (inspiré du parasite XF-85 Goblin). 
|
XP-38P-188, YP-38P-188, P-38P-188 : dérivés Lightning du projet Blohm und Voss P.188-4 à ailes à flèche composite (ou flèche complexe).
|
SA-38B-6, -7, -8 : nouveaux dérivés Lightning (après les SA-38A-6 etc.) du SA-386 de TheXHS sur DeviantArt.
|
SA-38C-6, -7, -8 : dérivés du même mais avec avec dérives externes et moins de poutres.
|
KAM-38A, B, C : inspirés du Nihon Kogata K-16 Kamo, ces Lightnings sont des planeurs canards.
|
DieP-38A, B, C : Lightnings inspirés d'une maquette dite de famille "Dieselpunk", avec un axe central porte-hélice verticalement loin des poutres.
|
DieP-38D, E, F : modifications de DieP-38C sans axe central porte-hélice.
|
DieP-38G, H, J : autres modifications encore du DieP-38C.
|
|
– UNO-38 Patriciavion : avion sauveur de l'humanité, dans une de mes nouvelles du recueil "Ma copine Tortue" Tome 27. – TJP-38A, B : ancêtres monoplaces beaucoup plus petits (Twin Jet Pursuit). 
|
|
– KB-38A Koboldning : dérivé Lightning d'un dessin canard multipoutre "Kobold" sur Deviant Art. – KB-38B, C : dérivés davantage Lightninguisés. 
|
XP-38F-261, YP-38F-261, P-38F-261 : grands Lightnings dérivés du projet Focke-Wulf Fw-261, avec poutres externes et quadrimoteurs ou hexamoteurs.
|
P-38F-261A, B, C : dérivés de YP-38F-61 à grande envergure pour la haute altitude (à la demande du concepteur-fantaisie Omer Cybokou).
|
TrTp-38A, B, C : P-38 à triple stabilo (triple tailplane) vu sur Internet en montage photo, et dérivés monostabilo puis bipoutre.
|
DPP-38A, B : P-38 inspiré par un Dieselpunk aircraft 3D vu sur sketchfab.com, et dérivé simplifié. (Punk en Anglais peut vouloir dire minable ou mal foutu...)
|
TPA-38A, B, C : P-38 asymétriques à deux hélicesins (Twin Propeller Asymmetric)
|
|
– XP-38P-77 : replacement d'un gros moteur Allison V-1710 par un micromoteur Ranger V-770 (comme sur le micro-chasseur XP-77). – YP-38P-77 : remplacement du second moteur pour réduire encore la puiisance et le prix. – P-38P-77 : version monomoteur (asymétrique) "vraie" concurrente du Bell XP-77, Cheap Lightning (P-38 bon marché) 
|
|
– XP-38P-70 : replacement d'une partie de Lightning par version 70% en taille, et moteur V-770 allant avec. – YP-38P-70 : version bi-V-770 avec tout à 70% sauf le pod habitacle, "Mini Lightning". – P-38P-70 : version avec pod réduit aussi (et désarmé), Micro Lightning. 
|
PST-38A, B, C : Perfume Spray Toys 38, jouets dispensateurs de parfums en nébulisat, reconversion pacifiste de drones massacreurs à énormes canons.
|
BPTM-38A, B, C : Lightning inspiré d'un dessin BiPoutre TriMoteur vu sur Facebook, et chainons manquants vers le "vrai" P-38.
|
XTRT-38, TRT-38A, B : tâtonnements autour du concept Turret-Lightning (à tourelles), militaire-canons ou civil-touristique.
|
|
– A-038 Swift Lightning : version Lightning simple du A-076 Swift Woman, dessin tripoutre (VTOL à moteurs basculants) vu sur Internet. – A-038B : version davantage Lightiniguisée. – A-138 : version inspirée aussi du A-147 Big Beatrix, du même dessinateur apparemment. 
|
XA-038Z, XA-038BZ, XA-238 : versions doubles des précédents, sans codage 38+38=76.
|
P-38PPA, PPA-2, PPA-3 : famille inspirée de mon prohjet de maquette aberrante, pour sourire.
|
RSS-38A, B, C : famille Lightning inspirée d'un dessin de science-fiction sur Deviuant Art : scifieart10000 Recon SSTO.
|
RSS-38Z, Z-2, Z-3 : dérivés du RSS-38A.
|
RSS-38Z-11, Z-12, Z-13 : dérivés du RSS-38Z redevenant bipoutres.
|
LV-38A, B, C : dérivés du brevet LVG 316693.
|
P-38A-234, 235, 236 : Lightning inspiré par l'Arado Ar-234, et dérivés à partir de là.
|
Pulp-38A, B, PushP-38 : Lightning avec moteur(s) sur pylône
|
ATF-38A, B, C : Lightnings dérivés d'un dessin d'AsTroneF trouvé sur le Web (Pinterest/Photobucket)
|
DGK-38A, B, C : Lightnings dérivés d'un dessin d'astronef se référant au magazine Hobby Dengeki
|
WEp-38A, B, C : Willoughby Epsilon Lightnings dérivés des Willoughby Delta 8 et 9 à poutres portantes (lifting booms)
|
WEp-38D, E, F : dérivés du WEp-38C
|
CavP-38A, B, C : maquette de Lightning monomoteur asymétrique construite par le what-if modeller Caveman fin 2021, avec 2 dérivés ici ajoutés.
|
JTB-38A, B, C : version Lightning d'un dessin vu sur Facebook, et dérivés liés.
|
JTP-38A, B, C : version sans réacteur des précédents.
|
PEx-38A, B, C : Lightnings à Poutres EXternes inspirés d'un dessin moderne d'avion bipoutre vu sur Facebook.
|
CP-38X, Z, Y : Lightnings inspirés du projet Galasso CP.12.
|
P-38PPZ, PPZ-2, PPZ-3 : dérivés doubles, tripoutres, des P-38PPA.
|
TSN-38A, B, C : Lightnings escomptés transoniques, avec réacteurs et pilote ou non.
|
P-38M-8, M-88, M-44 : Lightnings dérivés du planeur Makhonine Mak-8, avec un petit air de Willoughby Delta F (poutres portantes).
|
|
– PRT-38 : version Lightning d'un dessin aperçu sur pinterest, désigné Project R. – PRT-38C : version du précédent ressemblant à un Vought F7U Cutlass à hélice. – PRT-38Z : version double mais peut-être quadripoutre. 
|
|
– P-38-X Blitz Light : maquette du what-if modeller Scotaidh, à moteurs Daimler-Benz DB 605 (d'origine Messerschmitt ?) et verrière semi-bulle (d'origine MiG ?). – P-38-X1 : version asymétrique monopoutre du P-38-X. – P-38-X2 : version asymétrique monomoteur du P-38-X. 
|
Bk-38A, B, C : dérivé Lightning d'un dessin aperçu sur FaceBook, et chaînons manquants avec les vrais P-38.
|
AlEx-38A, B, C : Lightning stylisé dessiné sur des chaussettes Ali Express, et chainons manquants vers le P-38 classique.
|
|
– Boe-38A Boeingning : énorme dérivé de Lightning inspiré d'un projet Boeing aperçu sur le site pinterest. – Boe-38B : Lightning de taille normale inspiré du précédent, avec petits moteurs externes. – Boe-38C : version su précédent à 3 moteurs normaux sur l'axe central. 
|
Tmo-38A, B, C, D : dérivé Lightning d'un dessin trimoteur aperçu sur FaceBook, et autres de cette sous-famille.
|
EgA-38A, B, C, D : dérivé Lightning d'un dessin dit Moran Vaderwaffe TIE, et autres de cette sous-famille.
|
P-38B-25A, B, C : dérivé à côté Lightning accru d'un trucage photo "B-25 + P-38" vu sur FaceBook, et dérivés encore davantage Lightninguisés.
|
WWA-38A, B : dérivés Lightning d'un dessin "imaginaire WW2" bifide à ailes tandem de artist-19845 sur DeviantArt en 2021.
|
DPu-38A, B, C, D (Double-Pushning) : dérivés Lightning d'un dessin bi-pousseur vu sur FaceBook.
|
XDoF-38, YDoF-38, DoF-38A Dogfightning : prototypes puis série de version asymétrique à trajectoires incroyables en évolutions tournoyantes.
|
P-38L-049 Lightnellation, P-38L-149, P-38L-249 : Lockheed Lightnings P-38 inspirés de la série Lockheed Constellation (L-049 à L-1649).
|
P-38L-349, P-38L-449, P-38L-549 : autres Lockheed Lightnings P-38 proches de Lockheed Constellation.
|
F3B-38A, B, C : dérivés Lightning d'un dessin de motoplaneur F3B vu sur diagram.com.
|
CSt-38A, B, C : dérivés Lightning d'un dessin dit "Crimson Storm" sur pinterest.com.
|
RCH-38A, B : dérivés Lightning d'un dessin Ryui C-130 Hercules à ailes tandem vu sur pinterest.com.
|
RCH-38C, D : dérivés jumelés du RCH-38B.
|
RCH-38E, F, G : dérivés simplifiés du RCH-38B.
|
BPE-38A, B, C : Lightnings bi pods externes.
|
VL-38A, Z, L : Lightnings (civils) inspirés d'un dessin de Jimbowyrick1 sur Deviant Art : Veeblefizer-Lasagnia VL-31A "Maximus" Bomber.
|
XVR-38, YVR-38, VR-38A : Lightnings à centre bipoutre doublement justifié, inspirés d'un dessin vu sur pinterest.com, de pbs.twimg.com.
|
BVP-38A, B, C : Lightnings inspirés du Blohm und Voss P.192.
|
XL-51-36, -37, -38 : Lightnings inspirés du dessin THEXHS XL-515 sur DeviantArt.
|
CMG-38A, B, C : Lightnings inspirés d'un dessin asymétrique de dérivé Nakajima B5N (Kate) sur pinterest.com par Catmanedgarnehring.
|
CMG-38A-2, B-2, C-2 : versions doubles des précédents, perdant ou non leur asymétrie.
|
XC-54-36, -37, -38 : Lightnings inspirés du dessin THEXHS XC-542 sur DeviantArt.
|
XL-33-36, -37, -38 : Lightnings inspirés du dessin THEXHS XL-333 sur DeviantArt.
|
|
BiP-BiP-BiP-BiP ! – B4-38A Oloa : bipoutre biplan bipousseur bipale. – B4-38B Olaa : bipoutre biplace bi-pare-brise bi-patron. – B4-38C Ooao : bipoutre bipointe bipantalon bi-position d'aile. 
|
XH-40-37, -38, -38B : Lightnings inspirés du dessin THEXHS XHC-409 sur DeviantArt.
|
Pet-38A, B, C : Lightnings inspirés du dessin tonton42 Petadou-3 imaginaire.
|
P-38P-170A, B, C : Lightnings inspirés du projet Blohm und Voss P.170.
|
CEV-38A, B : CErfs Volants Lightnings (du Centre d'Essais en Vol ? du Curé de l'Eglise du Village ?).
|
|
DIY-38 : bricolages Lightnings (Do It Yourself) inspirés d'avions construits par diverses personnes postant sur pinterest.com : – 38-PPP : ) tripoutre à Poutres Porte Profondeurs. – 38-TIC : propulsé par élastique. – 38-PlaCa : planeur canard tripoutre. 
|
BvP-138A, B, C : Lightnings inspirés de l'hydravion bipoutre trimoteur Blohm-und-Voss Bv-138.
|
SBi-38A, B, C : Lightnings inspirés d'un jouet-avion dit Spinny Bird.
|
Pie-38, -38Z, -38A, -38P : famille Laïtenaingue, à la suite des monomoteurs (XP-34,) P-35, P-36, P-37 réinventant le P-38.
|
Sy-38A, B, C : chaînons manquants entre le P-38 et le Synergy Aircraft Synergy.
|
|
P-38 à base de Fw-189 : – P-38F & Fw-189B : maquette du what-if modeller ericr en 2022. – P-38FFF-189 : copie miroir par Tophe2022 (moi-même) – OPF-38 : version d'observation un peu comme le Fw-189. 
|
|
P-38 imaginés à partir d'un profil très foncé de Ausairpower.net : – AusP-38-1 : pas de moteur ni stabilo visible. – AusP-38-2 : mention de queue double. – AusP-38-3 : mention de motorisé. – AusP-38-4 : mention de monoplace. 
|
|
Lightnings pirates et contrebandiers (pirates and smugglers) : – Pir-38 : modèle en forme de drapeau pirate, pour un film Disney envisagé. – Smu-38 : ADAV (VTOL) de contrebande, et proposé au Service Médical d'Urgence Régionale (atterrissage sur toits d'hôpitaux). – Smu-38 en vol de croisière : avec basculement des soufflantes pour propulser. 
|
|
– Smg-38 : autre Lightning "crèpe volante" (ADAC, STOL) pour contrebandiers (SMuGglers) ou officiellement pour la ville de Bacolod, cité du sourire (SMilinG). – Smg-38A : version de série du Smg-38, employant des carcasses pas chères de P-38. – Smg-38 dépouillé : reste du Smg-38 après avoir transféré les éléments "crèpe volante" sur le Smg-38A. 
|
ORCA-38A, B, C : Lightnings inspirés de l'ékranoplane à 10 places ORCA-100 (ou Kassatka-100, ce qui veut dire Orque 100 en Russe).
|
SA-51-36, -37, -38 : Lightnings inspirés du dessin THEXHS SA-512 sur DeviantArt.
|
SDem-38A, B, C : Lightnings quadripoutres et bipoutres inspirés de l'ekranoplane Sea-Demon.
|
BuT-38A, B, C : Burning-Tail Lightnings aberrants se brûlant la queue, inspirés d'un dessin (vu sur Pinterest) ressemblant à un Heinkel He-162 bimoteur à jets écartés.
|
BuT-38D, E, F : autres Burning-Tail Lightnings, insistant dans la mauvaise direction...
|
BuT-38BT, DT, FT : autres Burning-Tail Lightnings encore, mais avec turbopropulseurs.
|
SA-49-36, -37, -38 : Lightnings inspirés du dessin THEXHS SA-498 sur DeviantArt.
|
CoAx-38A, B, C : Lightnings quadrimoteur et bimoteurs coaxiaux>
|
|
Triples Lightnings (Tripnings) : – Trp-38A, B : quadripoutre et bipoutre à nez central masqué. – Trp-38C, D : quadripoutre et bipoutre à solidité moindre.  
|
XSP-38A, B, C : Sesquiplightnings, nouveaux sesquiplans (= avec une aile et demie) ayant les moteurs en position haute, moins facile pour l'entretien mais avec moins de problème de garde au sol (donc court train d'atterrissage solide).
|
Bü-38, -138, -141 : dérivés Lightning du dessin Buttermilch 142 (Babeurre 142 en Français) de tonton42.
|
Bü-141Z-1, -3, -2 : diverses versions doubles symétriques de l'asymétrique Bü-141.
|
|
– CT-38 : hydravion triplan dérivé du CT-37 pirate du dessin animé Tale Spin de Walt Disney. – CT-38M : version monoplane. 
|
Go-138, -238, -338 : Lightnings dérivés d'un projet Gotha.
|
YP-38A, B, C : Lightnings dérivés d'un dessin Cutangus d'Avril 2018 (de gauche à droite : tripoutre-bipoutre-bipoutre).
|
CuP-38A, B, C : Lightnings dérivés du dessin Cutangus Model 191B de Mai 2016, ADAV assis sur la queue (VTOL tailsitter).
|
SKF-38A, B, C : Lightnings dérivés du dessin Strurmkartoffen (avion guerrier menaçant nommé "purée de pommes de terre", humour...) d'Omer Cybokou.
|
SKF-38A-2, B-2 : dérivés des précédents sans oublier le petit stabilo externe à l'avant des poutres du tripoutre.
|
P-38Z-2, -4, -6 : bi-Lightnings jumelés (Zwillings) à 2 ou 4 ou 6 moteurs.
|
XATm-38, YATm-38, ATm-38A : tripoutres puis bipoutre Lightnings à Ailes Tandem.
|
Tuy-38A, B, C : Lightnings à énormes tuyères ancestrales, derrière turbopropulseurs ou turboréacteurs.
|
P-38PJ, YP-38PJ, XP-38PJ : Lightning bifide à poutres-pulsoréacteurs et prototypes de faisabilité avant.
|
Flg-38A, B, C : nouveaux Lightning fantaisie à forme de drapeau (flag) pirate, mais vus de l'avant.
|
PSid-38A, B, C : autres Lightning fantaisie à forme de drapeau pirate, mais vu de côté.
|
CBJ-38A, B, C : Lightnings à réacteur en poutre centrale (Central Boom Jet), inspirés du SF-523 de THEXHS sur Deviant Art.
|
CBJ-38D, P, R : versions de CBJ-38B/C modifiées avec symétrie, 1 turboPropulseur à hélice (Propeller), 2 moteurs-fusées (Rocket).
|
ERC-38A, B, C : versions inspirées par la maquette du what-if modeller (pataphysicien ?) Ericr d'un hybride de Morane MS 230 et Potez 452.
|
BRo-38A, B, C : versions inspirées par une image d'avion Bristol Rock sur site pinterest.
|
SPB-38A, B, C : versions inspirées d'un hydravion du livre Speedbirds (concernant une coupe Schneider modernisée).
|
HWi-38A, B, C : versions Lightning sans grande dérive (et gouvernail) mais à plein de winglets partout, inspirées d'un dessin d'avion moderne par Kiril Nadtotshiy (Kyrill Nadtochiy) sur ArtStation. HWi est le code pour Hyper-Winglet.
|
KS-38A, B, C, D : maquettes Lightning avec mélange d'échelles 48e et 72e, KS étant pour Kit Scale.
|
HIn-38A, B, C, D : Lightnings à Hélice Intégrée (en fuselage-poutre), comme chaînons manquants avec un dessin vu sur FaceBook.
|
|
Compléments aux précédents, se rapprochant encore davantage de la source, qui était un hydravion : – VW-38 : hydravion à queue en V et aile en W (avec moteurs VolksWagen ??). – FP-38 : hydravion (à flotteurs : FloatPlane) sans V ni W mais même hélice intégrée. – PL-38A : hydravion bi-flotteurs-poutres sans hélice intégrée (proche du Levasseur PL.201). 
|
|
Groupe de Lightnings sans dérive : – LV-38 : les ailes volantes en flèche n'ayant pas besoin de dérive, faire ceci vers l'avant et l'arrière. – DI-38 : la dérive intégrée à l'arrière de la nacelle est inspurée de l'Airspeed AS.31. – TA-38S : inspiré par les modernes dessins d'avion piste de décollage "PanSpatial" de Tom Alfaro sur Art Station 
|
|
Autre groupe de Lightnings sans dérive "normale" : – PR-38F : hydravion à gouvernail mis sur le mat entre nacelle et flotteur (PR F = Pylon Rudder Finless). – SR-38F : avion à gouvernails mis sur les jambes pantalonnées de train d'atterrissage (SR F = Spats Rudders Finless). – VeB-38 : dérives vers le bas pour protéger l'hélice en cas de cabré excessif au sol (VeB = Vers le Bas). 
|
FFB-38A, B, C : Lightnings hydravions à coque sans dérives (Finless Flying Boat). Faible bras de levier pour les gouvernails...
|
XL-45-36, -37, -38 : Lightnings inspirés du dessin THEXHS XL-454 sur DeviantArt.
|
XL-15-36, -37, -38 : Lightnings inspirés du dessin THEXHS XL-153 sur DeviantArt.
|
Dy-38A, B, C : chainons manquants entre le SpeeDactyl (avion-oiseau télécommandé) et le P-38 Lightning.
|
TB-338A, B, C : Lightnings inspirés par le Kalinine TB-3.
|
SA-33-36, -37, -38 : Lightnings inspirés du dessin THEXHS SA-332 sur DeviantArt, avec aile centrale épaisse pour résevoirs (un peu la formule Burnelli).
|
SB-33-36, -37, -38 : variantess des précédents, surtout pour que les jets ne se brûlent pas la queue.
|
As-38B, C, D : Lightnings asymétriques justifiés par une même raison technique, la fantaisie... (sans danger si non construits non pilotés).
|
As-38E, F, G : Lightnings asymétriques beaucoup plus sérieux, dirigés par un impératif technique commun : la rêverie (ces "avions rêveurs s'imaginent avoir été dessinés par moi, ils sont fous ces avions !"). Hum.
|
SA-41-36, -37, -38 : Lightnings inspirés du dessin THEXHS SA-41 sur DeviantArt.
|
SF-23-36, -37, -38 : Lightnings inspirés du dessin THEXHS SFT-238 sur DeviantArt.
|
|
Nouveaux P-38 Lightning à réaction : – P-38-jet : photomontage de DH (David Holmes ?) sur Facebook. – P-38-J1a : version asymétrique monomoteur. – JDD-38 : projet Jet-Driven-Devil de Frank Whittle en 1944 (aucun rapport avec le Journal Du Dimanche...). 
|
Tur-38A, B, C : autres Lightnings à turboréacteur(s). Le C a une dérive gauche en titane résistant au chaud.
|
XP-380A, B, C : prototypes de New Lightning, à moitié pour essais.
|
P-380A, B, C : versions finalisées de New Lightning.
|
P-38P-170E, F, G : versions de Lightning à moteurs en étoile plus proches de la source Bv P.170.
|
P-38P-170H, K, L : autres Lightnings dérivés de Bv P.170, à partir d'images de maquettes que j'ai truquées pour sourire (rendant bipoutre le tripoutre P.170).
|
LCR-38A, B, C : Lightnings avec arrière central long (Long Central Rear, sans relation avec la Ligue Cimmuniste Révolutionnaire, hum). De gauche à droite : tripoutre, bipoutre, bipoutre.
|
CiS-38A, B, C : Lightnings inspirés d'un dessin à aile Circulaire du livre Speedbirds. Le dernier est quasi bipoutre (à poutres portantes, façon Willouhby Delta).
|
P-38B-58A, B, C : Hustnings hybrides de P-38 Lightnings et B-58 Hustlers.
|
TSAC-38A, B, C : Lightnings à réaction dérivés de l'Avro Canada TS-140.
|
XP-3851A, B, C : hybrides de P-38 Lightning et P-51 Mustang, à construire en maquettes peut-être.
|
YP-3851A, B, C : combinaisons des pièces restantes après avoir construit chacun des XP-3851A, B, C.
|
YP-3851AB, AC, BC : combinaisons en une seule maquette des pièces restantes après avoir construit deux des XP-3851A, B, C.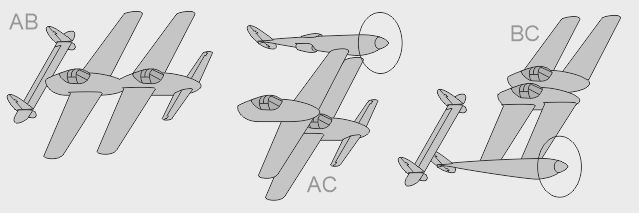
|
XP-3851D, E, F : autres hybrides de P-38 Lightning et P-51 Mustang, à construire en maquettes peut-être.
|
XP-3851G, H, J : autres mêlanges encore de P-38 Lightning et P-51 Mustang, à construire en maquettes peut-être.
|
XP-3851A-2, A-3, C-2 : finalisation des XP-3851A et C.
|
XP-3851AC-4, -5, -6 : trois possibiltés avec pièces restantes après avoir construit les A-3 et C-2 à partir de 2+2 kits.
|
PLR-38A, B, C : nouveaux Lightnings à réaction, à Poutres Loin des Réacteurs.
|
JC-38B, C, D : nouveaux Lightnings à réaction, à Jet Central (pas de relation directe avec Jésus-Christ, même si pilotes chrétiens autorisés à bord).
|
EKPL-38A, B, C : Lightnings dérivés d'une maquette d'ékranoplan.
|
XRB-38A, B, C : Lightnings à nacelles jets de RB-45 Tornado, inspirés par un Acro Shackleton à 6 moteurs du what-if modeller McColm.
|
AH-38A, B, C : Lightnings inspirés par un aéronef/astronef de Andrew Hodgson sur ArtStation.
|
GM-38, SO-38, He-138 : Lightnings-jets inspirés par Gloster Meteor, Sud-Ouest Trident, Heinkel 162.
|
DO-38A, B, C : Lightnings inspirés par le projet Douglas 1240.
|
|
Eléments d'avion double à la Mercury-Mayo : – GroP-38 : composite d'un P-38 presque normal portant une réplique à échelle 50% – Peti-38 et Gro-38 : avion porté s'étant séparé en vol de son porteur. – Zoom sur le Peti-38 : pour mieux en aprécier l'étrangeté. 
|
JBP-38A, B, C : P-38 Lightnings à réaction biplans et dérivé.
|
CAMB-38A, B, C, D, E, F : P-38 Lightnings inspirés d'un avion à double empennage inventé par le Concept Artist Maks Belinsky sur ArtStation.
|
CAMB-38G, H, J : autres P-38 Lightnings à double empennage peu-arrière/très-arrière.
|
CAMB-38K, L, M : encore d'autres P-38 Lightnings à double empennage, plus ou moins.
|
CAMB-38N, P, A, R : suite sur le même thème.
|
PTL-38E, F, G : Lightnings planeurs à poutrelles.
|
FD-38G, H, J Skipning : Lightnings inspirés du dessin FD.2 Skipper par AST21 sur ArtStation.
|
FD-38G-2, H-2, J-2 : versions canards des précédents, peut-être davantage proches du modèle.
|
Mya-38A, B, C : dérivés Lightnings du projet Myassishtshev M-55RD.
|
|
"Histoire" du PIL-38 (pas Ilyoushine Il-38 May... mais Primary International Lowcost aircraft): – XPIL-38 : le 1er espion avait dit "copié sur notre P-38", le 2e : "4 réacteurs et aile en flèche". – YPIL-38 : le 3e espion a dit "avec turboprops". – PIL-38 : la photo du final a montré 4 turboprops aile droite, moins cher sans doute. (En "vrai", le patrouilleur Il-38 n'avait aucun rapport avec le chasseur bipoutre Lockheed P-38, il ressemblait à un avion de ligne Lockheed L-188 Electra, comme le Vickers Viscount aussi ; la confusion est intervenue avec le Myassishtshev M-4 Bison, dit sur des boîtes de maquettes Revell "Bombardier Soviétique Il-38" puis 'Il-38 Bison", rêveusement mais inexactement...) 
|
Riz-38A, B, C : dérivés Lightnings d'un astronef créé par Cesar Rizo.
|
E-38R, S, T : dérivés Lightnings d'un AWACS à radôme créé par Cesar Rizo.
|
MQ-38A, B, C : dérivés Lightnings d'un Mosquito tripoutre dessiné par Tomzoo sur Deviant Art.
|
EE-238A, -138A, -138B : hybrides entre mes anciens mixes de Lightnings, Lockheed + English Electric, avec le double-Lightning vertical dessiné par Tomzoo sur Deviant Art.
|
TSC-38A, B, C : Lightnings biplaces canards (Two-Seat Canard) inspirés par une création de Christophe Pattou sur ArtStation.
|
|
– QF-38E-3 : drone Lightning trimoteur (3 Engines). – QF-38E-2 : version bimoteur. – QF-38T : version assise sur la queue (Tailsitter). 
|
|
– F-38Asy : Lightning compact légèrement asymétrique (moteur droit reculé pour éviter les hélices engrenantes). – QF-38B-3 : drone Lightning tripoutre. – F-38B-3 : version pilotée (à bord, pas à distance) du précédent. 
|
BurP-38A, B, C : Lightnings P-38 sur base d'un biréacteur Burnelli à fuselage porteur.
|
XP-38X, Z, Y : projet de couverure pour mon futur livre sur la formule P-39 de motorisation (avec arbre tournant entre les jambes).
|
P-38S-10, P-38TS, P-38MS : projet de chapitre P-38 dans le livre mentionné ci-dessus.
|
Fun-38A, B, C : projet de "Fun Lightning" télecommandé de Omer Cybokou (et 2 dérivés : tripoutre et monopoutre).
|
|
XP-38V2, YP-38V3, LeVraiP-38, LeVraiP-38Z ; XP-38V1, XP-38V3, LeVraiP-38 à canopée intégrée, LeVraiP-38Z à canopée intégrée :
vues en perspective tirées des profils dans mon nouveau petit livre "les top-chasseurs étaient tous bipoutres asymétriques". 

|
WIG-38T, U, V : dérivés Lightning d'un appareil à effet de sol étasunien (Wing-In-Ground, ékranoplane).
|
HPi-38A, B, C : Lightnings asymétriques avec empennage à moitié en H, à moitié en Pi (ou tabouret).
|
Bron-38A, Z : dessin d'une sorte de brontosaure volant (ou banane volante ?) trouvée sur FaceBook, déclinée en version double Zwilling trimoteur.
|
Bron-38A², Z² : version "expliquée" des précédents, avec réacteurs nucléaires radio-actifs abimant un peu tout.
|
SM-138A, B, C : Lghtnings inspirés d'un Stuka Messerschmitt imaginaire (SM : atroces initiales, effectivement massacreuses d'innocent...) aperçu sur FaceBook.
|
SM-238A, B, C : correction des précédents après découverte d'un plan 3-vues de Jimbowyrick1 sur DeviantArt.
|
SM-338A, B, C : correction des précédents avec solidification pour soutenir le poids arrière.
|
XB-238, YB-238, B-238A : Ancêtres Lightnings (imaginaires) du Northrop B-2A moderne (de 1989).
|
JPF-38A, B, C : Lightnings inspirés d'un dessin sur ArtStation de Jean-Paul Fiction.
|
JPF-138A, B, C : Lightnings inspirés d'un autre dessin sur ArtStation de Jean-Paul Fiction.
|
L.38-38A Tripning, B, C : Lightnings inspirés du vieux Lloyd 40.08 Triplane.
|
Elaboration progressive du Cari-38B caricaturé. 
|
CAA-38A, B, C : Lightnings inspirés d'une caricature de Carlos Alonso Art (https://www.carlosalonsoaviationart.com/cartoon).
|
| Asymétriques logiques : – XP-38Y-0, CSSIE-38 : Control on a Single Side Is Enough! – XP-38Y-1, SEIE-38 : a Single Engine Is Enough! – XP-38Y-2, TEIB-38 : "Two Engined" Is Better! 
|
HE-38A, B, C : Lightnings inspirés d'un modèle volant télécommandé Air Hogs Hawk Eye Blue Sky, aile volante bidérive sesquiplane plutôt que bipoutre ?
|
HE-38A-2, B-2, C-2 : versions vraiment bipoutres des précédents.
|
K-38D, E, F : hybrides de DB-38A et Kalinine K-7.
|
Lock-and-Voss P.338A, B, C : contrairement aux P.238 qui s'inspiraient des Bv P.208/209 (et P.210), ceux-ci s'inspirent plutôt du Bv P.215 (et P.212.03).
|
VC-38A, B, C : Lightnings inspirés d'un modèle réduit volant sans dérive pour Vol Circulaire (aucun rapport avec le Viêt-Cong).
|
IN-38A, B, C : Lightning inversé à poutres centrales, moteurs centraux, équipage latéral, et puis dérivés monomoteur et trimoteur.
|
P-381, GP-381, P-38, GP-38, XP-3838A, B, C : Bases puis premiers essais pour faire des XP-3838 purs Lightnings doubles inspirés des XP-3851 semi-Mustangs. 
|
YP-3838A, B, AB, AC : dérivés bi-Lightnings des YP-3851.
|
XP-3838D, E, F : dérivés bi-Lightnings des XP-3851 D à F.
|
XP-3838G, H, J : dérivés bi-Lightnings des XP-3851 G à J.
|
XP-3838A-3, C-2, C-3 : dérivés bi-Lightnings des XP-3851 A-3 et C-2.
|
XP-3838AC-4, AC-5, AC-6 : dérivés bi-Lightnings des XP-3851 AC-4 à AC-6.
|
XP-3838AC-4Z, AC-5Z, AC-6Z : dérivés doublés latéralement des XP-3838 AC-4 à AC-6.
|
XP-3838AC-6Z-4, -3, -2 : autres dérivés doublés du XP-3838 AC-6
|
XP-3838ZZ ZwiZwiLigntning, XP-3838ZZ-2, ZZ-3 : dérivés re-doublés du XP-3838AC-5Z.
|
TU-438A, B, C : dérivés Lightning du projet Tu-442 (Heavy Lift Transport) à aile annulaire ovale ou ovalaire.
|
Li-3800, 3801 : dérivés P-38 du projet Ligntning-1000 Hercules (heavy lifting cargo plane).
|
Li-3800+, 3801+ : dérivés des précédents avec davantage de réacteurs à la demande d'Omer Cybokou.
|
XB-438A, B, C : Lightnings apparentés au Martin XB-48 à 6 moteurs et à sa version (du truqueur DH) à 16 moteurs.
|
DL-38D, E, F Lightlanne : dérivés du DL-38A Delightning (anciens hybrides Lightning-Delanne à ailes tandem).
|
DH-538, 638, 738 : dérivés Lightning d'un truqage photo de bimoteur Mosquito devenu quadrimoteur.
|
TT-38PW avec divers appariements : dérivé Lightning du projet USAF Tip-Tow (qui employait 1 B-29 central et 2 jets F-84 externes largables).
|
|
– LC-38PO : d"après profil caricaturé par Laurent Chassard sur site "Patte d'ours" (sans Liquid Chromatography, mon ex-métier 1984-2018...). – Deg-38 : Lightning à ailes externes en Dégradé (résultat pas Dég-ueulasse...) – NSu-38 : Lightning à 2 nez superposés. 
|
XTB-38, YTB-38, TB-38P : réinvention du Lightning comme bipoutre monomoteur tractif (puis dérivé push-pull).
|
PP-38P, PP-38P-2, PP-38P-3 : entre un Lighntning push-pull à moteurs en étoile et la formule Dornier PP de 1944.
|
PP-38PZ, PP-38P-2Z, PP-38P-3Z : versions doubles des précédents.
|
|
– BouM-38 : Boutons de Manchette P-38 Lightening. – PoC-38 : Porte-Clef P-38. – Col-38 : "Collectible" P-38. 
|
PinS-38, PinT-38, PinU-38 : dérivés Lightning d'un Pin's sans moteur apparent, comme planeurs trinez.
|
P-38SQ-1, -2, -3 : deux caricatures de P-38 chez TeePublic.com pour Bugs Bunny monté dessus (+ synthèse).
|
|
– PKt-38 : Lightning simplifié suite à recommandation du what-if modeller PR19_Kit (nez standardisés même sans besoin d'hélice centrale). – PKt-38A : version trimoteure avec 3 nez moteurs identiques avec hélices partout cette fois. – PKt-38B : version monomoteure du précédent. 
|
|
– Fi-238A : Lightning inspiré d'un double Fi-156 canard par Midhat Kapetanovic sur Artstation. – Fi-238B : dérivé à train rentrant. – Fi-238C : version rapetissée. 
|
|
– YM-38 : dérivé Lightning d'un quadrimoteur tripoutre canard dessiné par Yury Milovidov pour DeviantArt. – YM-38B : dérivé rendu bipoutre. – YM-38C : dérivé rapetissé asymétrique. 
|
XP-38B Whirlstar, YP-38S Starshooter, Photographer : inventions de profils par le what-if modeller Zero-Sen en 2011, 2011, 2014.
|
|
– P-51Z Lightstang : invention de profil par le what-if modeller Zero-Sen en 2012 (à base P-82 Twun-Mustang peut-être plutôt que P-51 Mustang). – P-47Z ChainBolt : invention de profil par le what-if modeller Zero-Sen en 2011. – Hil-38A : invention type cartoon animé de Cal Grondahl pour le Hill Aerospace Museum chez pinterest. 
|
FWB-38A, B, C : dérivés Lightning s'inspirant d'un "Front Winch Bumper" (Pare-chocs de Treuil Avant) fourni par Google Images dans une recherche d'avions.
|
RCP-38A, B, C : dérivés Lightning de jouets radio-contrôlés (ou pour vol circulaire), Voodoo (R.Wooten 1961), LaGata (L.Trajaola 1959), Yegad (E.Portz 1965).
|
SM-44-37, -38, -39 : Lightnings inspirés du dessin THEXHS SM-447 sur DeviantArt, entre bipoutre et aile volante complexe.
|
A-38A, B, C : Lightnings inspirés du dessin cthelmax A38 Lightning Bomber sur DeviantArt.
|
SXB-33-36, -37, -38 : Lightnings inspirés du dessin THEXHS SXB-335 sur DeviantArt, en version coloriée de manière gentillette pour effacer bombes et canons.
|
XL-29-36, -37, -38 : Lightnings inspirés du dessin THEXHS XL-299 sur DeviantArt.
|
UC-38A, B, C : Lightnings asymétriques pour vol circulaire (Control Line ou U-Control).
|
XL-24-36, -37, -38 : Lightnings inspirés du dessin THEXHS XL-241 sur DeviantArt, avec aile entre circulaire et ovale.
|
P-38HR, HR-2, HR-3 Half-Radial Lightnings : versions avec un moteur en étoile (pour satisfaire la marine, la maintenance) et un moteur en ligne (pour satisfaire l'armée, la performance).
|
| Silent Lightnings : – P-38W-4 Flying Wing Lightning : maquette de P-38W cassée par déménagement (perte de poutres, queue, moteurs). – P-38W-5 (P-38W-4Z): dérivé double du précédent. – P-38W-6 (P-38S ?) Simplified Lightning : reconstruction partielle de maquette, bien Lightning bien bipoutre symétrique mais sans moteur à envergure modérée (what-if). – P-38W-7 (P-38W-6Z) : dérivé double du précédent, tripoutre. – P-38W-8 : dérivé bipoutre du précédent. 
|
|
– P-38W-9 : projet de maquette suggérée par le what-if modeller scotaidh, installant le groupe push-pull du P-38W sur le plan de profondeur (mais l'hélice avant trop large coupe les poutres). – P-38W-10 : version imaginaire si les 6 pales d'élice étaient tronquées. – P-38W-11 (P-38W-10Z) : dérivé double du précédent, tripoutre. 
|
EPm-38A, B, C : dérivés d'une maquette inconnue de EP-modélisme à cocardes françaises (aucun rapport d'EPm-38 avec l'expression "Et Puis Merde !").
|
EPm-38D, E, F : dérivés d'une maquette inconnue de EP-modélisme à cocardes soviétiques.
|
EPm-38G, H, J : dérivés d'une maquette inconnue de EP-modélisme à cocardes ± étasuniennes.
|
Myst-38A, B, C, D : mystères de classification aéronautique entre aile volante et bipoutre, pour un jet-Lightning sans stabilo.
|
TeB-38A, B : dérivé du photomontage de double P-38 tête-bèche par David Holmes (vu sur FaceBook)
|
CoS-38A, B, C : dérivé d'une vue peu claire de Skydrift Condor (aucune relation entre ces CoS-38 et les géloses CoS Columbia Sheep agar).
|
BiNé-38A, B, C : Lightnings bi-nez français (d'après le code).
|
VST-38A, B, C : Lightnings dérivés d'un VTOL Stealth Transport Concept de Rodrigo Avella chez pinterest.
|
MiT-38, 38A, 38B : Lightnings dérivés du Micronautix Triton, avec vue panoramique avant pour les passagers (aucun rapport entre ces MiT-38 et le Massachusetts Institute of Technology).
|
HASP-38C, B, A : Lightnings dérivés du drone solaire Apus Duo (en catégorie High Altitude Solar Powered).
|
P-3888A, B, C ; D, E, F ; G, H, J : Lightnings inspirés de ma maquette P-5456 (XP-54+XP-55+XP-56) cassée et reconstruite.  
|
P-3888Z, Z-2, Z-3 : diverses versions doublées par effet mitoir du P-3888E.
|
UFO-38A, B, C : dérivés Lightnings à aile circulaire d'un drone façon soucoupe volante de la compagnie Corporate Jet Solution (UFO signifie OVNI en Anglais, Unidentified Flying Object).
|
DH-138A, B, C : dérivés Lightnings quadrimoteurs radiaux d'un photomontage de David Holmes avec un B-24 Liberator canard.
|
ChT-38A, B, C : dérivés Lightnings d'un "module lunaire" bipoutre dessiné par Chris Thompson sur ArtStation.
|
WLT-38 : dérivé Lightning d'un jouet VTOL Coolsky WLtoys XK X450. Ici en 3 modes : décollage vertical, accélération horizontale, croisère horizontale.
|
P-38PB, PB-2, PB-3 : Lightnings Pod and Booms (Nacelle et Poutres) symétrique ou asymétriques.
|
|
– P-38FB : Lightning Fuselage and Boom (Fuselage et Poutre) asymétrique. – P-38BB, BB-2 : Lightning Boom and Beam (Poutre et Poutrelle) asymétriques, avec pilote à bord ou non. 
|
| L’USNavy ayant utilisé des P-38 (F-5 de reconnaissance) comme FO-1, imaginons les dérivés, voulus sans moteur à refroidissement liquide et plus petits (des F2O à F9O atyant déjà été envisagés plus haut) : – F11O (à moteurs à pistons refroidis par air), – F12O (à turboréacteurs), – F13O (à turbopropulseurs). 
|
P-38A-2000, -2011, -2022 : Lightnings inspirés d'un grand modèle radiocommandé à plan canard annexe portant 4 hélices pousseuses (donnant ici Lightning de l"an 2000 etc.).
|
| Lightnings tripoutres à poutres en bouts d'ailes tandem : – IE-38 : dérivé de l'Inter-Ex 2012, – OM-38A : dérivé d'un avion d'Ondrej Mitas, – OM-38B dérivé d'un autre avion d'Ondrej Mitak, moins utilitaire semblant viser davantage d'esthétique. 
|
IE-38B, C, A : dérivés imaginaires bipoutres, symétriques ou asymétrique, du plus ou moins véridique tripoutre IE-38.
|
TG-38A, B, C : Lightnings inspirés d'un modèle réduit volant en bois dans un film YouTube de tyoukogatalabo intutulé 20091122 SSFC.
|
MCT-38G-1, -2, -3 ; MCT-38P-1, -2, -3 : transcriptions vectorielles à base P-38 des dessins manuscrits dans le recueil romantique "Ma Copine Tortue" tome 29, nouvelle "Ce dessin a une histoire".
|
MRF-38A, B, C ; Lightnings à poutre de nez MRF (Meteorological Research Flight), redevenant bipoutre plus ou moins après coup. De gauche à droite : 2 poutres de nez (et 2 poures arrières), 2 poures sur 2 nez (et 2 poutres arrières), 2 poutres de nez (et 2 poutres au total). Suite à discussion avec le what-if modeller AeroplaneDriver et son projet de bipoutre/tripoutre Vampire-MRF, inspiré de l'Hercules-MRF véridique (monopoutre, lui, "triste").
|
MRF-38A-2, B-2, C-2 ; variantes des précédents (pour complément taxonomique, rien à voir aec la météo), compte tenu du fait qu'une perche ne portant pas d'élément d'empennage n'est pas forcément appelée poutre.
|
|
– LEP-38 : Lightning à Aile Épaisse (sans aucun lien avec Lycée d’Enseignement Professionnel). – SGo-38A, B : dérivés Lightning fusée et turboprop de l’astronef Space Gooose vu sur Pinterest. 
|
PoB-38A Pair of Booms, PoB-38B, PoB-38C : Lighning télécommandé ultra-compact et dérivés quadripoutres.
|
Be-1038A, B, C : Lighnings dérivés du Beriev Be-103.
|
Vam-38A, B, C : Lighnings imaginaires interprétant des mots mystérieux du what-if modeller zenrat s à propos d'un Vampire canard.
|
WN-38A, B, C : Lighnings sans nez (Without Nose) avec diverses motorisations (ou sans moteur).
|
DH-438Q-1, -2, -3 : Lighnings dérivés d'une nouvelle image Facebook de DH truqueur photo talentueux.
|
DH-438QA-1, -2, -3 : autrse onterprétations (asymétriques) des précédents, l'effet conique rendant incertaine l'attribution de dérive du fond à un moteur.
|
DH-438QB-1, -2, -3 : encore d'autrse interprétations (asymétriques) cette fois avec empennage jointif.
|
Tab-38A, B, C, A-2, B-2, C-2 : Lightiings avec volets d'équilibrage des ailerons (balance tabs). 
|
DAL-38A, B, C : Lightiings à Dérives ALaires semi-poutres (sans rapport avec Droit Au Logement). |
AK-38A, B, C : Lightiings inspirés du Lisa Airplanes Akoya et de la lecture erronnée que j'ai faite d'une photo réduite initiale, croyant à un bipoutre asymétrique. |
|
– PV-38H-1, -2 : Lightnings amphibies inspirés du Meekins Privateer, dont la première vue que j'ai aperçue masquait le stabilisateur. – EE-38M-49 : asymétrique ancêtre Lockheed du quadrijet biplace English Electric Twin-Lightning Mk.49 que j'ai imaginé ailleurs. 
|
EKR-38A, B, C : Lightnings dérivés d'un ekranoplane présenté comme modèle réduit sur pinterest.fr.
|
PCr-38A, B, C : Lightnings inspirés du tout petit bimoteur Colomban Cri-Cri. (Ce Pursuit CRi-cri n'a aucun rappoert avec la Polymerase Chain Reaction d'analyse ADN ou ARN.)
|
EKN-38A, B, C : autres Lightnings à petits moteurs avant, inspirés d'un projet d'ékranoplane présenté sur pinterest.fr
|
No-38A, B, C : Lightnings inspirés du Northrop N-59A/P.D.1053 (vrai ou imaginaire) présenté sur SecretProjects.co.uk.fr
|
GLo-38A, B, C : énormes Lightnings inspirés de la version bicockpit du Douglas XC-74 Globemaster. On peut dire aussi qu'il s'agit de XC-74 pétrentuisé (P-38-isé, mot d'Omer Cybokou sur FaceBook, merci).
|
TD-38A, B, C : dérivés Lightnings d'un avion à ailes tandem vu sur FaceBook, avec moteurs en bouts d'aile.
|
DA-38D, E, F : Lightnings dérivés d'un avion fictif dessiné sur Deviant Art.
|
FV-38A, B, C : Lightnings ancêtres (imaginaires, fantaisie) du Rockwell XFV-12.
|
GN-38Q, R, S : Lightnings dérivés d'un dessin Nakajima G555N-2 Super-Shinzan de jimbowyrick1 sur DeviantArt.
|
XCP-38G, YCP-38G, CP-38G : Lightnings cargos dessinés pour un thème "Logistics" (logistique) des what-if modellers.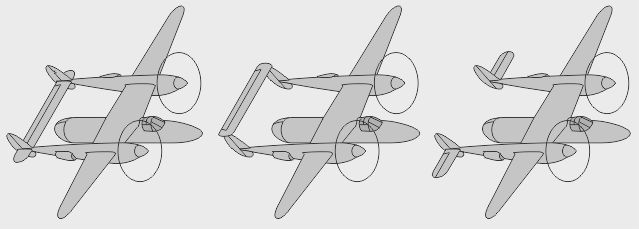
|
XCP-38H, YCP-38H, CP-38H : Lightnings cargos sans stabilo arrière.
|
XCP-38J, YCP-38J, CP-38J : Lightnings cargos à réaction.
|
CP-38G-20, CP-38K, CP-38K-10 : Lightnings cargos dérivés pour abaisser l'aile, et éventuellement devenir tripoutre.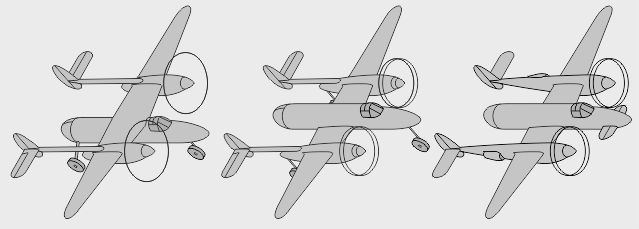
|
XCP-38K, YCP-38K, XCP-38CC : Lightnings cargos asymétriques (avec demi-aile gauche : haute, et demi-aile droite : basse), et quadrimoteur inspiré d'un dessin du what-if modeller Captain Canada.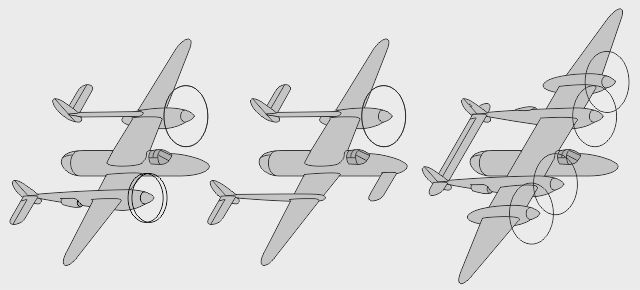
|
XCP-38L, YCP-38L, CP-38L : autre Lightning cargo asymétrique, utile, avant suppression de son asymétrie par doublement et améliration de visibilité.
|
XCP-38M, XCP-38N, YCP-38N : Lightnings cargos avec soute porteuse façon Burnelli, ou asymétrie encore différente.
|
CP-38P, CP-38Q-1, CP-38Q-2 : Lightnings cargos façon Burnelli/Horten et tripoutres (long et court, solides).
|
De haut en bas, CP-38R-1 et CP-38R-2 : Lightnings cargos à soute détachable au sol, façon Fairchild XC-120 Packplane (de gauche à droite : complet, aéro détaché, soute détachée). 
|
Savoia-Marchetti SM-3838, 3839, 3840 : Lightnings prototypes inspirés du dessin Savoia Cigno jet sur le site beyondthesprues (aucun rapport avec le Stade Malherbe de Caen Football but yeah ni avec Sylvie Métailié snif snif bouhouhou…).
|
XCP-38S, YCP-38S, CP-38S : Lightnings cargos disSymétriques, pour charges spéciales (à imaginer...).
|
CP-38T-1, T-2, T-3 : Lightnings cargos Twins et Tandem.
|
CP-38T-4, T-5, T-6 : autres Lightnings cargos Twins, à fuselages ± externes.
|
CP-38J-2, -3, -4 : nouveaux Lightnings cargos à réaction.
|
CP-38S-11, -12, -13 : versions double ou partiellement doubles des YCP-38S et CP-38S.
|
CP-38T-4, T-5, T-6 : Lightnings cargos Twins et Tandems à la fois.
|
VeF-138A, B, C, D : Lightnings challengeant les limites de la définition "bipoutre", inspirés du Veeblefitzer Ve-F-138 TriLightning Fighter de Jimbowyrick1 sur DeviantArt.
|
XP-38P-67, YP-38P-67, GP-38P-67 Moonlight : Lightnings inspirés du MC Donnell XP-67 Moonbat.
|
AAS-38H, P, T : dérivés Lightnings d'un projet asymétrique Rock Island Arsenal "Aerial Artillery System" (ici en versions Helicopter, Pusher, Tractor).
|
RIA-38H, G, T : dérivés Lightnings d'un projet Rock Island Arsenal peut-être nommé RIA (ici en versions Helicopter, Glider, Tractor).
|
CP-38R-1Z plein, moitié-plein, vide : dérivé double du CP-38R-1.
|
MyH-38A, Z, Z-2 : dérivés Lightning d'une machine mystère (peut-être hydravion monoplace) aperçue sur pinterest.fr.
|
MyH-38B, Z-3, Z-4 : dessins corrigés sur la base de la même source.
|
NNTP-38A, B, C : illustration sur base Lightning d'un projet hypothétique du what-if modeller 63cpe à base de 2 poutres de Noratlas, 1 T-28 Trojan, 1 Pa-25 Pawnee.
|
NNTQ-38A, B, C ; NNTR-38A, B, C : toujours sur base Lightning, versions révisées du projet "North American Airtruk" du what-if modeller 63cpe à base de Noratlas, T-28 Trojan, Pa-25 Pawnee.

|
NNTR-38A, B, C : étapes suivantes du projet de 63cpe, dessinées en version P-38.
|
NNTS-38A, B, C : étape encore après du projet de 63cpe, en version P-38.
|
PBJ-38A, B, C : dérivés Lightning en 2022 du dessin B-5-001 Juliénas de tonton42/OmerCybokou en 2011.
|
PBJ-38D, E, F : chaînons manquants entre le PBJ-38C et le P-38 standard.
|
XPB-38A, B, C : Lightnings modernisés dérivés d'un dessin d'escorteur avec projet de bombardier avancé.
|
CP-38S-1, 2, 3 : mélanges de pièces Lightnings cargos aux échelles (scale) 1/72 et 1/144.
|
CP-38S-3Z, Z-2, Z-3 : doubles jumellés/zwillingués du CP-38S-3.
|
DAF-38A, B, C : dérivés Lightnings d'un dessin (de Deviant Art ?) aperçu sur FaceBook.
|
Ares-38A, Z, Y : dérivés Lightnings d'un projet Coroflot Ares wing, un des nombreux avions différents nommés Ares.
|
Ares-38A-2, Z-2 : dérivés des précédents avec davantage d'hélices, à la demande de l'internaute Omer Cybokou.
|
SWKt-38A, Z, Y : dérivés Lightnings du jouet SIG Wonder Kit.
|
P-38P-1238, P-38P-138, P-38P-38 : chaînons manquants (missing links) entre supersonique Hawker P.1214 et P-38.
|
BC-38A, Z, Z-2 : dérivés Lightnings du dessin Batcraft de l'internaute Omer Cybokou (Tonthon42).
|
WA-38A, B, C : dérivés Lightnings d'un projet Westland-Agusta à rotors basculants.
|
FJt-38A, B, C : dérivés Lightnings d'un dessin d'avion à réaction imaginaire (Fantasy Jet) montré sur pinterest.
|
AQ-38A, B, C : dérivés Lightnings du projet Aqualines Ekranoplane basque.
|
XCP-38U, YCP-38U, CP-38U : Lightnings cargos à moteurs centraux push-pull.
|
SM-46-36, -37, -38 : Lightnings inspirés du dessin THEXHS SM-466 sur DeviantArt.
|
Cu-281, -381, -481 : dérivés Lightnings des dessins Cutangus Cu-181A sur DeviantArt.
|
XC-49-36, -37, -38 : Lightnings inspirés (en beaucoup plus petit) du dessin THEXHS XC-492 sur DeviantArt, genre d"énorme jet-Burnelli à fuselage porteur.
|
CP-38V-1, V-2, V-3 : Lightnings cargos étonnamment sans porte arrière (bipoutres car avec tuyère centrale).
|
Cu-38B, A, C : Lightnings dérivés du Cutangus Aerodyne 171A dessiné sur Deviant Art.
|
Cu-138A, B, C : Lightnings dérivés du Cutangus Aerodyne 195Q dessiné sur Deviant Art.
|
Cu-192C, D, Z : Lightnings dérivés du Cutangus Cu-192B dessiné sur Deviant Art.
|
Cu-238A, B, T : Lightnings dérivés du Cutangus Cu-128B dessiné sur Deviant Art.
|
Cu-338B, C, A : Lightnings dérivés du Cutangus Aerodyne 156A dessiné sur Deviant Art.
|
CL.134A, B, C : aspects ienvisageables de la version canard du L.134 (famille contenant le projet XP-58 Chain Lightning et son équivalent non-bipoutre).
|
|
– L.134-3, 3Z, 3C : version non-bipoutre du XP-58 envisagée, et hypothèses double ou canard – P-38L-34A, Z, C : bersions petites à-la-P-38 des précédents  
|
P-38SD, P-38SD-TT, P-38SD-NT : Lightnings avec fonction d'autodéfense arrière (SD, TT, NT signifient Self-Defense étasunien ou Self-Defence britannique, T-tail, no-tail).
|
XCP-38CD, CE, CF : dérivés du Lightning quadrimoteur cargo XCP-38CC.
|
SM-838, 839, 840 : Burnelli Lignthnings cargos inspirés par le SM-84 de TheXHS sur DeviantArt (SM fait peut-être référence à Savoia-Marchetti, pas à Salope Méchante, sinon mes initiales CM seraient dites Connard Mauvais…).
|
PSF-38A, B, C : Lignthnings dérivés du dessin Sky Fortress vu sur FaceBook.
|
Wei-38A, B, Z : Lignthnings dérivés d'un dessin étrange (weird) vu sur FaceBook.
|
Wei-38A', B', Z' : versions monomoteurs des précédents.
|
MHM-38A, C, B, AC, BB : projets de maquettes P-38 à échelle 1/144 de marque Mini Hobby Models avec stabilo intégral monopièce.

|
|
– Focke-Wulf Fw-199 Blitz Zerstörer (et Fw-222 Wespe, Fw-333 Blitz) : vue en perspective d’un dessin de dessus de cortz#9 chez Amternatehistory. – ImP-38 Improved Lightning : vue en perspective d’un dessin 3-vues de cortz#9 chez Amternatehistory. – P-38PP-2 : vue en perspective d’un dessin transformé que j’ai fait d’après cortz#9 réinventant le tripoutre « three-engine P-38 zwilling » (mes Jahsan Pair of 38's, Brooks P-38Z). 
|
CP-38W-1, -2, -3 : cargos Lightning de formule Burnelli encore différents.
|
P-38Fw-1, -2, -3 : dérivés purement Lightning d'un mélange P-38/Fw-190 par Just Leo sur AlternateHistory.
|
|
– dessin 2 de Temco Long Horn (CIA Article 36 variant) : maquette du what-f modeller comrade harps en 2009 (la présentation par Sport16ing sur DeviantArt étant une reprise très partielle en 2017). – LH-38S, T : versions simplifiées du Long Horn 
|
| Lightnings inspirés d'images trouvées sur AlternateHistory.com : – Fokker G.1/38 : cœur Lightning entouré de poutres (et ailes externes) de G.1 – Just Leo modernized Lightning : P-38 à queue d’OV-10 Bronco – Cortz#9 « Z-38 » : maquette d’avion allemand imaginaire inspiré du P-38 
|
DC-38A, B, C : Lightnings imaginés en s'inspirant au départ d'un DC-8 imaginaire très allongé.
|
Stav-38A, B, C : Lightnings dérivés du projet Stavatti SM-150.
|
ISN-38A, B, C : Lightnings dérivés du modèle réduit Itek Super Nova RC.
|
Pol-38A, B, C : Lightnings dérivés du modèle réduit Polaris EX Seaplane Parkflyer.
|
Pol-38A-3, B-3, C-3 : versions tripoutres des précédents.
|
Pic-38A, B, C : Lightnings dérivés de divers projets aériens à grande verrière panoramique (vers le haut).
|
Alb-38A, B, C : Lightnings inspirés d'un brevet Albessard des années 1930.
|
Alb-38A-1, B-2, C-1 : versions motorisées des précédents.
|
Vultee XP-1015, -1015Z, -1015Z-3 : projet concurrent (véridique) du futur XP-38, devenant bifuselage (de manière imaginaire).
|
P-1015A, B, C : versions tripoutres puis bipoutre (imaginaires) du XP-1015.
|
| Dérivés du P-19 half-lightning présenté sur warthunder.com pour faire "comme" de P-82 à P-51 (Twin-Mustang à Mustang) P-19, P-19x2, P-19x3 : recomposition multiplicative après division. 
|
|
– P-19x3TB, P-19x3TBA, P-19x3SB : versions bipoutres puis monopoutre du P-19x3. – P-19x3TB-1, P-19x3-TBA-1, P-19x3SB-1 : versions monoplaces des triplaces précédents.  
|
| Modèles réduits dérivés de P-38 pour Vol Circulaire VCM-38A, B, C : modèle de base, version avec pseudo-cockpit, version bimoteur. 
|
DH-838A, B, C : dérivés Lightning d'un trucage photo de DH (David Holmes ?) sur Facebook présentant un Vickers VC-10 court octomoteur.
|
SF-52-37, -38, -39, -40 : dérivés Lightning d'un dessin SF-523 par TheXHS sur DeviantArt.
|
CP-38SG Super-Gupning : au sol en chargement avant puis en vol soute fermée.
|
SPr-38A, B, C : dérivés Lightning d'un dessin d'astronef Sopwith Plover Mk.1 sur Deviant Art par Jan Boruta.
|
ArP-38ST, -38ST-117, -38ST-2 : mon aperçu simplifié du Stealth P-38 de Yeeky Zhang sur ArtStation, puis dérivés inspirés des F-117 et B-2.
|
TPD-38A, B, Z : Lightnings binacelles (twin-pods).
|
TPD-38A-1, A-2, A-3 : dérivés asymétriques du TPD-38A suggérés par le chat-if modeller PR19_Kit.
|
XCP-38X-1, -2, -3 : cargos Lightnings à soutes latérales.
|
P-38TJt-1, -2, -3 ; -4, -5, -6 : nouveaux Lightnings à turboréacteurs. 
|
P-38 OM-1, -2, -3 : mes étapes pour reproduire le P-38 d'Omer Cybokou (avec empennage en V inversé et moteurs à plat).
|
XCP-38Y-1, -2, -3 : Lightnings cargo de formule Burnelli asymétrique (à fuselage porteur et cockpit décalé latéralement).
|
| Transition de XCP-38Y-2 aux XCP-38Z : – XCP-38Z-1 : après l'objection "Hé, un Lightning est bimoteur, pas monomoteur !" – XCP-38Z-2 : après l'objection "Hé, un Lightning est bipoutre, pas tripoutre !" – XCP-38Z-2 : après l'objection "Hé, un Lightning est symétrique, pas asymétrique !" 
|
ER-138A, B : Lightnings inspirés d'une maquette SM-79+Mi-6 conçue et réalisée par le what-if modeller ericr.
|
FH-38A, B, C : Lightnings rejoignant la forme de l'astronef Jeffs3d Fondor Haulcraft.
|
| Pour purger mon malaise vis à vis des avions codés SM, comme le célèbre Savoia-Marchetti SM-79 Sparviero : P-38SM-79A, -79B, -79C : Sparviering de chez Silvia Metailia, Sylvja Metailjek, Sîlwïy Métèlyë. 
|
|
P-38SM-79C2, C3, C4 : dérivés du 79C suite à suggestion de dérives plus grandes par le what-if modeller Flyer ; ces codes cumulatifs ne sont pas aberrants : les codes SM et 2C2 sont associés pour l'éternité en moi, polytraumatisé. 
|
XS-38, YS-38, S-38A : hésitations initiales pour concevoir le shasseur Lightning, dans un monde parallèle.
|
DLi-38A DoubLightning, -38B, -38C : Doubles Lightnings à 3 ou 4 moteurs et queues séparées.
|
SDL-38A DoubLightning, -38B, -38C : versions simplifiées des précédents.
|
WD-38A, B, C : Lightnings pusher ou push-pull à poutres alaires façon Willoughby Delta 8.
|
EW-38A, B, C : Lightnings peut-être pas volants, inspirés du vélo à hélice (airscrew bicycle) de Ernest Winter dans Popular Mechanics de Février 1963.
|
Ala-38A, B, C : Lightnings dérivés de diverses maquettes "Avions en Pierre" de AvionLumin'Air sur FaceBook (pas de relation avec Alanine, Phenylalanine, Alanie-Ossétie). L'Ala-38B a une aile en fer à cheval (horseshoe wing), presque une aile bipoutre.
|
Ala-38D, E, E-2 : Lightnings dérivés d'autres maquettes "Avions en Pierre".
|
Ala-38F, F-2, F-3 : encore des Lightnings dérivés d'une autre maquette "Avions en Pierre".
|
ZP-38A, B, C : Lightnings inspirés par mon Mitsubishi Zero (spécial...) A6M80.
|
P-38CSE, CSE-3, CSE-2 : Lightnings inspirés d'une base P-38BSE et d'un dessin de "F-14 WW2" sur Art Station par Ariel Alvarez.
|
YFP-38A, B, C : Lightnings à moteurs en étoile partageant le même profil gauche montré sur pinterest.fr, disant que la source est le logiciel discord (mon dessin est presque "sérieux" le 1er Avril 2023).
|
MH-38A, B, C : Lightnings à aile plus ou moins circulaire, inspirés du Millenium Hawkeye de Donald Yatomi sur Art Station.
|
P-38LC-1 à -6 : Lightnings dérivés (avec imagination délirante) du profil P-38L de Laurent Chassard dans le super livre "Encyclopédie Aéro-Cartoon" tome 2 ("Américains").
|
P-38LC-1 et -7 à -9 : autres Lightnings dérivés du profil P-38L de Laurent Chassard dans "Encyclopédie Aéro-Cartoon" tome 2 ("Américains").
|
|
– P-380 : prototype P-38 à ailes externes de P-80 (maquette du what-if modeller TheRat) – P-380A : évolution à ailes entières de P-80 et moteur à réaction. – P-380B : version finalisée de P-38 vers la voie P-80. 
|
P-38FDM-1, -2, -3 : interméfiaires entre le Lightning et une "Flying Thing Dipo Muh" vue sur pinterest.fr.
|
P-38FDM-4, -5, -6 : interméfiaires entre le Lightning et une autre "Flying Thing Dipo Muh" vue sur pinterest.fr.
|
P-38F-166, -167, -168 : Lightnings ancêtres du Fieseler Fi-168.
|
Messerschmitt-Horten 383, Lockheed-Horten 384, Lockheed 385, 386, 387 : famille de Lightnings imaginée à partir de la maquette du what-if modeller killnoizer (avec lourds lance-flammes à l'arrière, pour l'équilibre massique, mais les miens sont civils gentils, déséquilibrés tant pis, comme moi en un sens).
|
CCD-38A, B, C, D : dérivés de la maquette Twine Pod P-38 montrée sur FaceBook, inspirée du Twine Pod Cloud Car des films Star Wars.
|
Xasy-38A, B, C : améliorations d'un Lightning à éléments inversés, à partir d'une version impossible à hélices engrenantes depuis moteurs séparés.
|
PCA-238A, B, C : chaînons manquants entre Lightning et CAO-200.
|
BoB-38A, B, C ; D, E, F : Lightnings inspirés d'un projet d'aile volante Boeing contemporain du XB-15. 
|
DoX-38A, B, C : chaînons manquants entre Lightning et Dornier Do-X.
|
Astro-38A, B, C : dérivés Lightning d'un astronef sesquiplan aperçu sur Facebook.
|
VBP-38A, B, C : dérivés Lightning d'un projet fusée Von Braun.
|
Delanne DEL-38A, B, C : dérivés Lightning de la formule Delanne d'aile tandem, par exemple pour aile réservoir à grande autonomie.
|
BT-38A, B, C : cousins Lightning imaginaires du projet Bartini T-217.
|
BT-38D, E, F : compléments combinatoires dans la même famille, le FaceBooker Alban Dejardin ayant demandé si les précédents étaient oeuvre de 
|
|
– TRN-38A, B, C : dessin sur base Lightning aboutissant à un bifuselage par simple rotation orthogonale d'un avion normal à ile tandem. – TRN-38D, E, F : explication pourquoi ça ne fonctionnerait pas, faute de surface alaire à profil portant. – TRN-38G : version crédible mais sans rotation simple. 
|
P-38PR-1, -2, -3 : nouveaux hybrides de P-38 et Pond Racer, un peu inspirés par un photo-montage de David Holmes
|
tof2023 w.i.001, 002, 003 : nouvelle forme de marquage, suite à la réflexion sur site https://www.kristofmeunier.fr/fake-whif-conciliation.htm
|
sandiego89 Jet-Lightning, tof2023 w.i.005, 007 : maquette d'un what-if modeller avant 2024 et dérivés asymétriques que j'imagine.
|
tof2023 w.i.004, 008, 009 : délire avec P-38 monté sur turbofan (turbojet à double flux), version double et version simple-flux.
|
tof2023 w.i.010, 011, 012 : version zwilling du P-38 mono-turbofan, avec queues diverses.
|
tof2023 w.i.013, 014, 015 ; 017, 018, 019 : groupe de Lightnings semi-planeurs à microréacteurs (microjets) d'appoint, pour décollage. 
|
tof2023 w.i.020, 021, 022 : Lightnings monoréacteurs inspirés du DH-100 Vampire, comme imaginé par le what-if modeller The Rat.
|
tof2023 w.i.024, 032, 033 : Lightnings biréacteurs peu normaux.
|
tof2023 w.i.034, 035, 036 : jet-Lightnings biréacteurs peut-être "à poutres portantes".
|
tof2023 w.i.037, 038, 039 : jet-Lightnings sesquiplan ou biplans.
|
tof2023 w.i.040, 041, 042, 043 : jet-Lightnings inspirés par la maquette Bronco HA du what-if modeller killnoizer, sans plu' de poutre.
|
tof2023 w.i.044, 047, 048 : jet-Lightnings polyréacteurs à microjets.
|
| Mise à jour 22-23/07/2023 | - ajout de pavé tof2023 w.i.034, 037, 040, 044 |
| Mise à jour 26/06/2022 | - allègement : suppression des 1.979 rappels de police de caractères (fichier 11% moins gros) pour environ 5.937 versions de Lightning. |
| Mise en ligne 02/03/2007 | - format HTML, taille imprimable |
| Création 25/02/2007 | - rassemblement en petit livre |
| Contributions 2004-2006 | - sur forum des What-if modellers |
| Contributions 1998-2004 | - dans livres "Fantômes Fourchus"/"Forked Ghosts" |